A Simple Framework for Contrastive Learning of Visual Representations
@chenSimpleFrameworkContrastive2020
This paper presents SimCLR: a simple framework for contrastive learning of visual representations. We simplify recently proposed contrastive self-supervised learning algorithms without requiring specialized architectures or a memory bank. In order to understand what enables the contrastive prediction tasks to learn useful representations, we systematically study the major components of our framework. We show that (1) composition of data augmentations plays a critical role in defining effective predictive tasks, (2) introducing a learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations, and (3) contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning. By combining these findings, we are able to considerably outperform previous methods for self-supervised and semi-supervised learning on ImageNet. A linear classifier trained on self-supervised representations learned by SimCLR achieves 76.5% top-1 accuracy, which is a 7% relative improvement over previous state-of-the-art, matching the performance of a supervised ResNet-50. When fine-tuned on only 1% of the labels, we achieve 85.8% top-5 accuracy, outperforming AlexNet with 100X fewer labels.
Knowledge
Section titled “Knowledge”
- Data augmentation is critical to define effective predictive tasks
- Prevents trivial forms of agreement, such as agreement of the color histograms, by random crop + color distort

No single transformation (that we studied) suffices to define a prediction task that yields the best representations, two transformations stand out: random cropping and random color distortion. Although neither cropping nor color distortion leads to high performance on its own, composing these two transformations leads to state-of-the-art results.
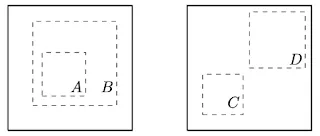
Consider the problem of maximizing agreement between two crops of the same image. Two types of prediction tasks depending on what areas are cropped: (a) Predicting local view from global view, and (b) predicting neighboring views
However, difference crops of same image typically has the same color space so the model can cheat by just focusing solely on color and ignoring other more generalizable features.
-
A learnable nonlinear transformation between the representation and the contrastive loss substantially improves the quality of the learned representations
- Improving the performance of a linear classifier trained on the SimCLR-learned representation by more than 10%.
-
Contrastive learning benefits from larger batch sizes and more training steps compared to supervised learning.
Insights
Section titled “Insights”- Interesting is that they pass the output of the ResNet through a MLP before computing the contrastive loss. The reasoning for this is that it amplifies the invariant features and maximizes the ability of the network to identify different transformations of the same image
- The contrastive task when composed with many data augmentations becomes harder, but the quality of representation improve dramatically.
Questions
Section titled “Questions”Critique
Section titled “Critique”- I like the data augmentation ablation. Love the conclusion that model is using shortcut learning to cheat through the color channel.
- Highly doubtful of adding the MLP before the contrastive loss. It trivially closes the train-test gap, increases compute requirements, and could be folded into the encoder. Perhaps why the MLP need nonlinearity to extract the invariant features is because the encoder is too shallow and the features are not linearly separable.