Masked Autoencoders Are Scalable Vision Learners
@heMaskedAutoencodersAre2021
This paper shows that masked autoencoders (MAE) are scalable self-supervised learners for computer vision. Our MAE approach is simple: we mask random patches of the input image and reconstruct the missing pixels. It is based on two core designs. First, we develop an asymmetric encoder-decoder architecture, with an encoder that operates only on the visible subset of patches (without mask tokens), along with a lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Second, we find that masking a high proportion of the input image, e.g., 75%, yields a nontrivial and meaningful self-supervisory task. Coupling these two designs enables us to train large models efficiently and effectively: we accelerate training (by 3x or more) and improve accuracy. Our scalable approach allows for learning high-capacity models that generalize well: e.g., a vanilla ViT-Huge model achieves the best accuracy (87.8%) among methods that use only ImageNet-1K data. Transfer performance in downstream tasks outperforms supervised pre-training and shows promising scaling behavior.
Knowledge
Section titled “Knowledge”Related works section. Good overview of self-supervised learning in vision.
Masked language modeling (GPT, BERT) masks parts of the input and trains the model to predict the masked tokens. Scale excellently and powerful learned representations.
Autoencoding (PCA, k-means) are classical methods that learn representations by reconstructing the input data. Denoising autoencoders (DAE) is a subset that corrupts the input data and train the model to reconstruct the original data. MAE is a more general form of DAE, where the corruption is done by masking random patches of the input image.
Contrastive learning (SimCLR, MoCo) learns representations by contrasting positive and negative pairs of data.

Insights
Section titled “Insights”- Self-supervised pre-training reduces the reliance on large labeled datasets. In vision, progress has lagged behind NLP due to the nature of image data: language is discrete, semantic, and information-dense, while images are continuous, low-level, and highly redundant. This makes designing effective self-supervised tasks for images challenging. Masking a large portion (>75%) of the input image creates a meaningful and difficult task, encouraging the model to learn useful representations.
- The decoder design: Due to the vision-text information density gap above, while in BERT the decoder can be as simple as a MLP, in vision, the decoder needs to be more powerful to reconstruct the original image from the masked input.
- Simple algorithms that scale well are the core of deep learning.
- Table 1a shows that even a single-block decoder when paired with fine-tuning can achieve very good performance.
- Table 1f shows that random sampling of the patches works the best out of block, grid, and random sampling.
- Table 1e shows that in contrast to contrastive learning (SimCLR, BYOL), using augmentations harms performance.
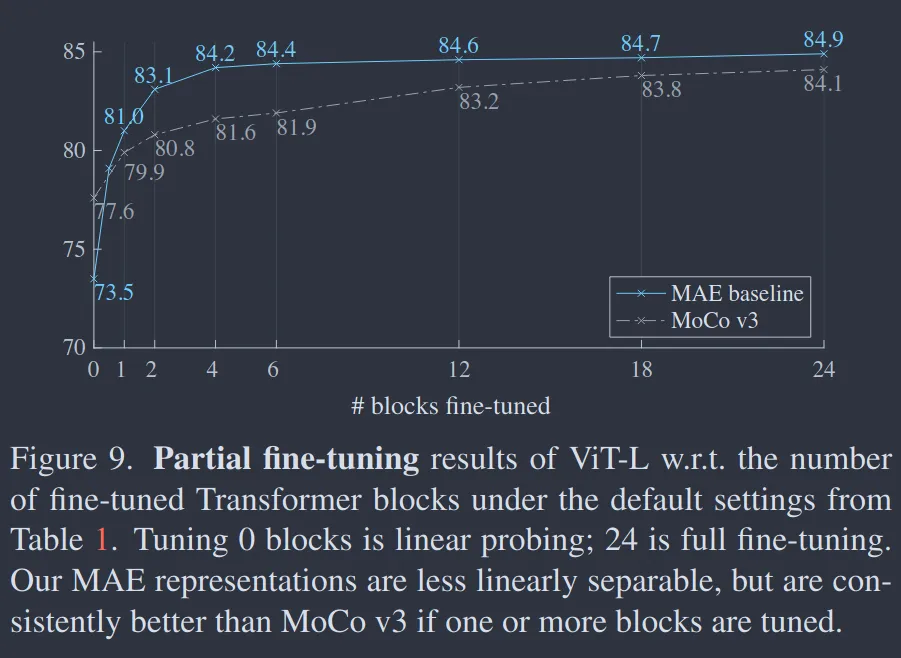
- Also explores partial fine-tuning as opposed to linear probing and full fine-tuning. Main idea is to fine-tune the transformer blocks instead of attaching a linear classifier on top of the frozen features. This is more effective than linear probing and more efficient than full fine-tuning.
- Good ablation design I think.
Conclusion: MAE > BEiT > MoCo v3 > supervised learning on classical vision benchmarks.
Questions
Section titled “Questions”- Why isn’t there a training-inference mismatch for the encoder? It only sees
the visible patches during training, but during inference it sees all patches.
Does this cause any issues?
- The encoder is designed to extract features from any subset of patches, so it generalizes well to the case where all patches are visible.
- The model learns robust representations due to the random masking during training, which acts as a strong regularizer.
- Empirical results show that MAEs perform well even with this mismatch, suggesting the encoder adapts effectively.
Critique
Section titled “Critique”- Is masked image modeling really a good pretext task? Seems like a method to retrofit SSL onto vision