Distributed training in PyTorch
There are two primary types of distributed training: data parallelism and model parallelism. Many more such as expert parallelism, pipeline parallelism, and tensor parallelism. And they can mix and match.
Data parallelism
Section titled “Data parallelism”Data parallelism shard data across multiple devices with the same model. Three major tasks:
- Model replication: creates and dispatches copies of the model, one copy per accelerator
- Data sharding: splits the data into batches and distributes them across the devices
- Result aggregation: collects and combines the results from each device to update the model parameters
Distributed data parallel (DDP)
Section titled “Distributed data parallel (DDP)”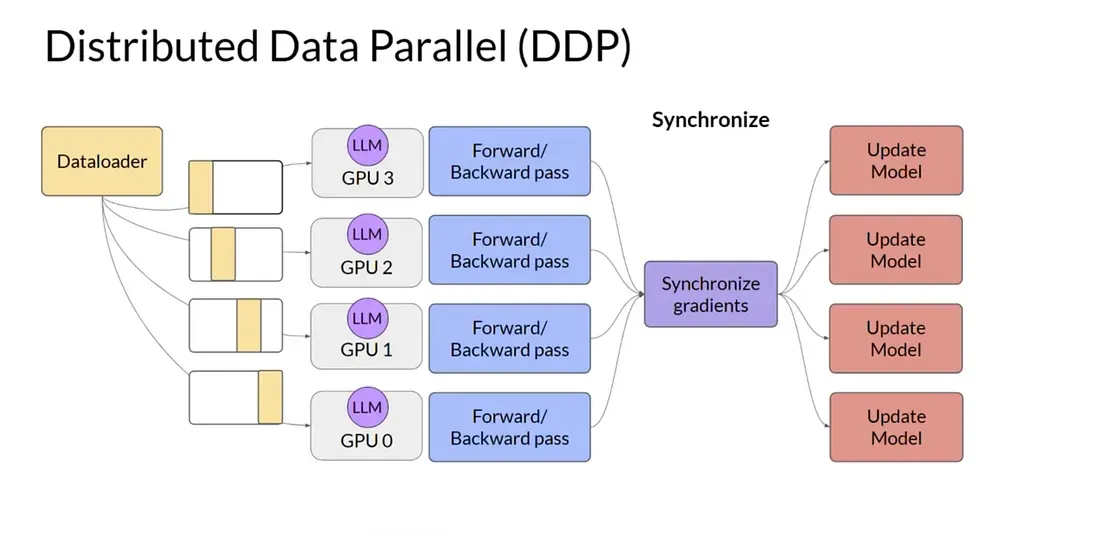
PyTorch’s DistributedDataParallel (DDP) is a widely used module for data
parallelism by leveraging multiple GPUs. It replicates the model across devices,
shards the data, and synchronizes gradients during backpropagation. How it
works:
- Model replication: DDP creates a copy of the model on each GPU. They won’t have different parameters at initialization due to the broadcasting model’s copy on the master process to all other processes at the beginning of training.
- Data sharding: DDP uses
DistributedSamplerto shard the dataset across multiple processes. Each process gets a unique subset of the data, ensuring that each GPU processes different batches. - Parallel processing: All GPUs perform forward and backward passes independently on their respective data shards, reducing time taken for each epoch.
- Gradient synchronization: After the backward pass, DDP synchronizes the gradients across all GPUs using an efficient communication backend (e.g., NCCL). This ensures that each model replica updates its parameters based on the combined gradients from all devices, keeping the replicas in sync.
Benefits of DDP
Section titled “Benefits of DDP”- Faster training.
- Simple implementation: minimal changes from the existing single-GPU code.
- Scalability: ideal for models that fit on a single GPU but could benefit from accelerated training.
Limitations of DDP
Section titled “Limitations of DDP”Wasteful memory usage. If model cannot fit on a single GPU, have to reach for model parallelism.
DDP internals
Section titled “DDP internals”In PyTorch, the DistributedSampler ensures each device gets a non-overlapping
input batch. The model is replicated on all the devices; each replica calculates
gradients and simultaneously synchronizes with the others using the ring
all-reduce algorithm.
Fully sharded data parallel (FSDP): PyTorch’s model parallelism
Section titled “Fully sharded data parallel (FSDP): PyTorch’s model parallelism”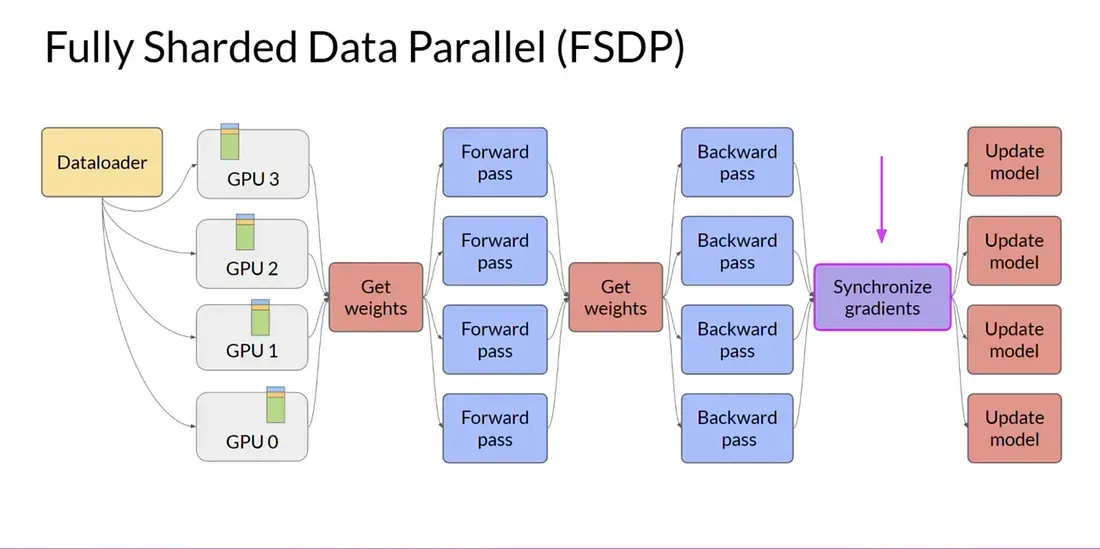
When your model weights more than what a single GPU can handle, reach for PyTorch’s FSDP. FSDP builds on a technique called ZeRO (Zero Redundancy Optimizer) to shard the model state (gradients, optimizer state, and parameters) across multiple GPUs.
ZeRO (Zero Redundancy Optimizer)
Section titled “ZeRO (Zero Redundancy Optimizer)”
While we often think of model in terms of their parameters, the optimizer state is often the real memory-hog during training. Two reasons:
- Redundancy (storing multiple values per parameter): For various popular optimizers like Adam and AdamW, the optimizer needs the history of every single weight to calculate the next step.
- Precision (needing high-resolution numbers to keep training stable): While parameters and gradients can be stored in lower precision (e.g., FP16 or BF16) to save memory, the optimizer state cannot be low-precision to maintain numerical stability during training. Updates typically are small, and using lower precision can lead to underflowing, vanishing updates.
| Component | Precision | Bytes per param |
|---|---|---|
| Parameters | FP16 / BF16 | 2 bytes |
| Gradients | FP16 / BF16 | 2 bytes |
| Master weights (Optimizer) | FP32 | 4 bytes |
| Momentum (Optimizer) | FP32 | 4 bytes |
| Variance (Optimizer) | FP32 | 4 bytes |
| Total | 16 bytes |
The 16x Adam rule: with a standard FP16 Adam setup, don’t expect a 1 billion parameter model to fit on 2GB VRAM, it takes roughly 16GB VRAM due to the optimizer state.
Interplay with automatic mixed precision (AMP): AMP casts your master weights to FP16/BF16 on-the-fly to increase FLOPs. The original weights are still stored in FP32 to maintain numerical stability, but the actual computations are done in lower precision for speed.
ZeRO tackles this memory-hogging problem by sharding the optimizer state, gradients, and parameters across multiple GPUs. It has three stages of sharding:
- Stage 1: Only shards the optimizer states, which can reduce memory usage by up to 4 times.
- Stage 2: Shards both optimizer states and gradients, leading to up to 8 times memory reduction.
- Stage 3: Shards everything, including model parameters, optimizer states, and gradients, achieving memory reduction proportional to the number of GPUs.
Implementing FSDP
Section titled “Implementing FSDP”- Model sharding: FSDP shards the model state across multiple GPUs. Each GPU holds only a fraction of the model’s state, allowing you to train models that exceed the memory capacity of a single GPU.
- On-demand data collection: During training, each GPU requests the necessary shards from other GPUs as needed for forward and backward passes. This on-demand collection minimizes memory usage while ensuring that the required data is available when needed.
- Synchronization: After the backward pass, FSDP synchronizes the gradients across all GPUs similar to DDP.
Performance vs memory tradeoff
Section titled “Performance vs memory tradeoff”FSDP can significantly reduce memory usage, but significantly increases communication overhead. You can adjust the sharding factor to find the right balance between memory savings and communication overhead for your specific model and hardware setup.
DDP is essentially FSDP with a sharding factor of 1, where the entire model state is replicated on each GPU.