Momentum Contrast for Unsupervised Visual Representation Learning
@heMomentumContrastUnsupervised2020
We present Momentum Contrast (MoCo) for unsupervised visual representation learning. From a perspective on contrastive learning as dictionary look-up, we build a dynamic dictionary with a queue and a moving-averaged encoder. This enables building a large and consistent dictionary on-the-fly that facilitates contrastive unsupervised learning. MoCo provides competitive results under the common linear protocol on ImageNet classification. More importantly, the representations learned by MoCo transfer well to downstream tasks. MoCo can outperform its supervised pre-training counterpart in 7 detection/segmentation tasks on PASCAL VOC, COCO, and other datasets, sometimes surpassing it by large margins. This suggests that the gap between unsupervised and supervised representation learning has been largely closed in many vision tasks.
Knowledge
Section titled “Knowledge”Contrastive learning: can be thought of as training an encoder for a dictionary-lookup task. Can also be a way of building a discrete dictionary out of high-dimensional continuous inputs.
The “keys” (tokens) in the dictionary are sampled from data (e.g., images or patches) and are represented by an encoder network. Unsupervised learning trains encoders to perform dictionary look-up: an encoded “query” should be similar to its matching key and dissimilar to others. Learning is formulated as minimizing a contrastive loss.”
-
Loss function: measure the different between input and target
- Reconstructing input pixels: L1 and L2 losses
- Classifying input into pre-defined categories: cross-entropy, margin-based methods
- Contrastive losses measure sample pair’s similarities in representation space
- Adversarial losses measure difference between probability distributions
-
Pretext task: a task of not true interest, only goal is to learn useful representations for downstream tasks.
- Recovering the input under some corruption: Auto-encoders
- De-noising
- Cross-channel (colorization)
- Context
- Contrastive loss-based methods
- Instance discrimination
- Contrastive predictive coding (CPC)
- Contrastive multi-view coding (CMC)
- Noise-contrastive estimation (NCE)
- Recovering the input under some corruption: Auto-encoders
Some pretext tasks form pseudo labels by transformations of a single image, patch orderings, tracking or segmenting objects in videos, or cluster features
MoCo uses InfoNCE loss, where
…Noise-contrastive estimation. We are contrasting the actual signal (positive examples of neighboring words) with noise (randomly selected words that are not neighbors). This leads to a great tradeoff of computational and statistical efficiency.

- Different types of moving averages:
- Simple moving average (SMA):
- Exponential moving average (EMA):
(MoCo, I-JEPA)
- Simple moving average (SMA):
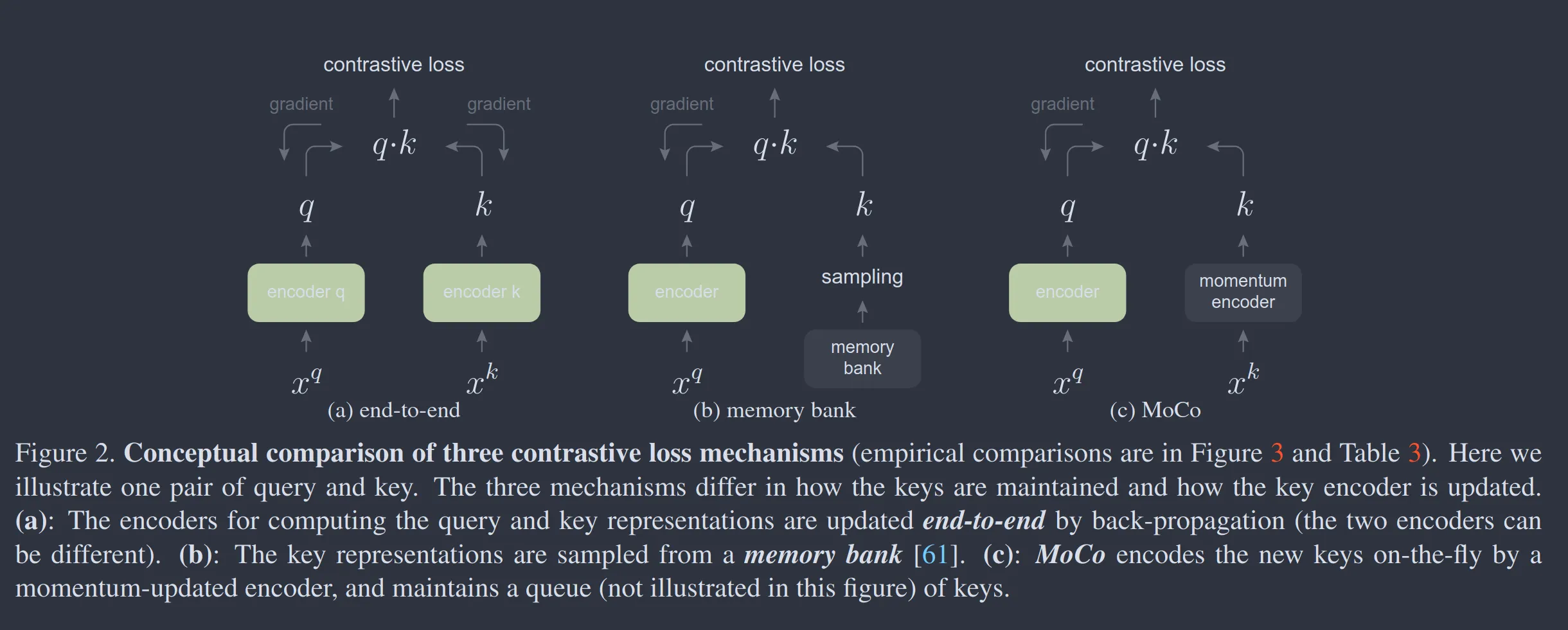
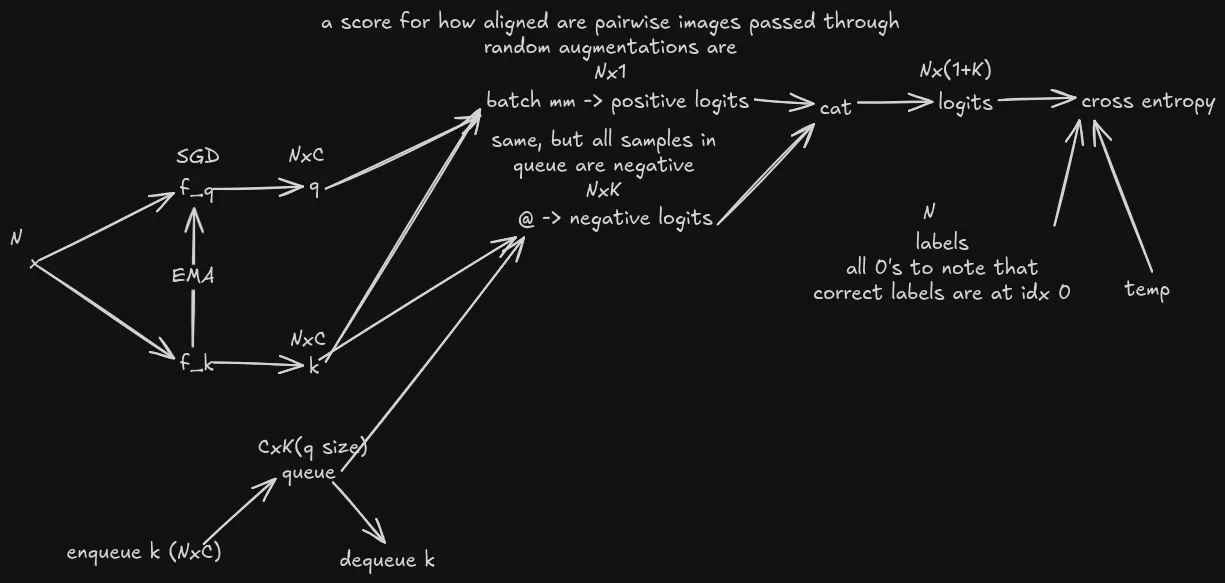
Insights
Section titled “Insights”- Reframed unsupervised learning as a dictionary building exercise
- Distance-based vs classification losses (InfoNCE): The alignment perspective treats contrastive learning as a direct “push-pull” task, aiming to force positive pairs toward an absolute similarity of one and negative pairs toward zero. Alternatively, the classification approach frames the task as a competitive multiple-choice test, using a softmax function to ensure the positive pair “wins” by being significantly stronger than all available negatives.
- Temperate set to 0.07 to give more peaky distribution, which might be important for good contrasting.
- MoCov2 achieves 11% accuragy gain (71.1%) over MoCoV1 (60.6%) given small changes to the data augmentation and output projection head.
- Overall, MoCo has largely closed the gap between unsupervised and supervised representation learning in multiple vision tasks.
- Remarkably, in all these tasks, MoCo pre-trained on IG-1B is consistently better than MoCo pre-trained on IN-1M. This shows that MoCo can perform well on this large-scale, relatively uncurated dataset. This represents a scenario towards real-world unsupervised learning.
- MoCo’s improvement from IN-1M to IG-1B is consistently noticeable but relatively small, suggesting that the larger-scale data may not be fully exploited. We hope an advanced pretext task will improve this.
- MoCov2 combined SimCLR’s data augmentation and projection head while sidestepping its large batch size requirement, achieving a significant boost in accuracy. This suggests that the pretext task design is an important factor for improving unsupervised learning.
Questions
Section titled “Questions”- What is the role of the dynamic queue?
The dictionary is dynamic in the sense that the keys are randomly sampled, and that the key encoder evolves during training. Our hypothesis is that good features can be learned by a large dictionary that covers a rich set of negative samples, while the encoder for the dictionary keys is kept as consistent as possible despite its evolution.
- Difference between energy functions and contrastive loss function? Both assign
low values to similar pairs and high values to dissimilar pairs.
- Contrastive loss is a strategy for shaping an energy function by creating “contrast” between the data and the noise. Non-contrastive methods (like BYOL or Barlow Twins) shape the same energy function using different tricks (like momentum networks or redundancy reduction) to avoid the need for those negative pairs.
Critiques
Section titled “Critiques”- Can improve upon this framework by trying out different pretext tasks
This paper’s focus is on a mechanism for general contrastive learning; we do not explore orthogonal factors (such as specific pretext tasks) that may further improve accuracy