Joint Embedding Predictive Architecture (JEPA)
Cursory knowledge
Section titled “Cursory knowledge”World model vs. transition function in RL
Section titled “World model vs. transition function in RL”The transition function defines the specific next state (or probability distribution over next states) given the current state and action.
World models, on the other hand, often used in partially observable environments where one has to model the transition dynamics in latent space.
Transition functions can make use of unobserved state in its calculation, while world models can only use the observables.
Manifold hypothesis
Section titled “Manifold hypothesis”Manifold hypothesis states that high-dimensional data (e.g., images, audio) often lie on a low-dimensional manifold embedded in the high-dimensional space. This is the core basis of unsupervised learning and manifold learning.
Free energy principle
Section titled “Free energy principle”From Wikipedia:
The free energy principle is a mathematical principle of information physics. Its application to fMRI brain imaging data as a theoretical framework suggests that the brain reduces surprise or uncertainty by making predictions based on internal models and uses sensory input to update its models so as to improve the accuracy of its predictions. This principle approximates an integration of Bayesian inference with active inference, where actions are guided by predictions and sensory feedback refines them. From it, wide-ranging inferences have been made about brain function, perception, and action. Its applicability to living systems has been questioned.
Important papers and talks
Section titled “Important papers and talks”https://rohitbandaru.github.io/blog/JEPA-Deep-Dive/
https://elonlit.com/scrivings/the-annotated-jepa
Problems with current AI
Section titled “Problems with current AI”From Yann Lecun’s position paper @lecunPathAutonomousMachine.
The current generation of self-supervised learning with a huge pretraining phase followed by fine-tuning and reinforcement learning to produce a class of LLMs. Many capabilities but also face limitations:
- Hallucinations
- Limited reasoning
- Lack of planning
All of these problems can be attributed to a lack of common sense.
Common sense can be thought of as either:
- a lower bound on the types of errors an agent makes
- a collection of world models: mental models of how the world works, which can be used to make predictions and guide actions.
Essentially, animals are believed to use world models to generalize their learnings.
Dupoux listed the limitations of current AI systems with respect to learning:
(1) confronting the “data wall” on quality text data (2) inability to learn new things beyond current human knowledge because of the absence of interaction with the environment (Silver and Sutton, 2025) (3) excessively language-centrism as opposed to spatial, embodied and grounded reasoning in the physical world (4) lack of continual life-long learning (self-improvement after deployment) [@dupouxWhyAISystems2026, p. 1]
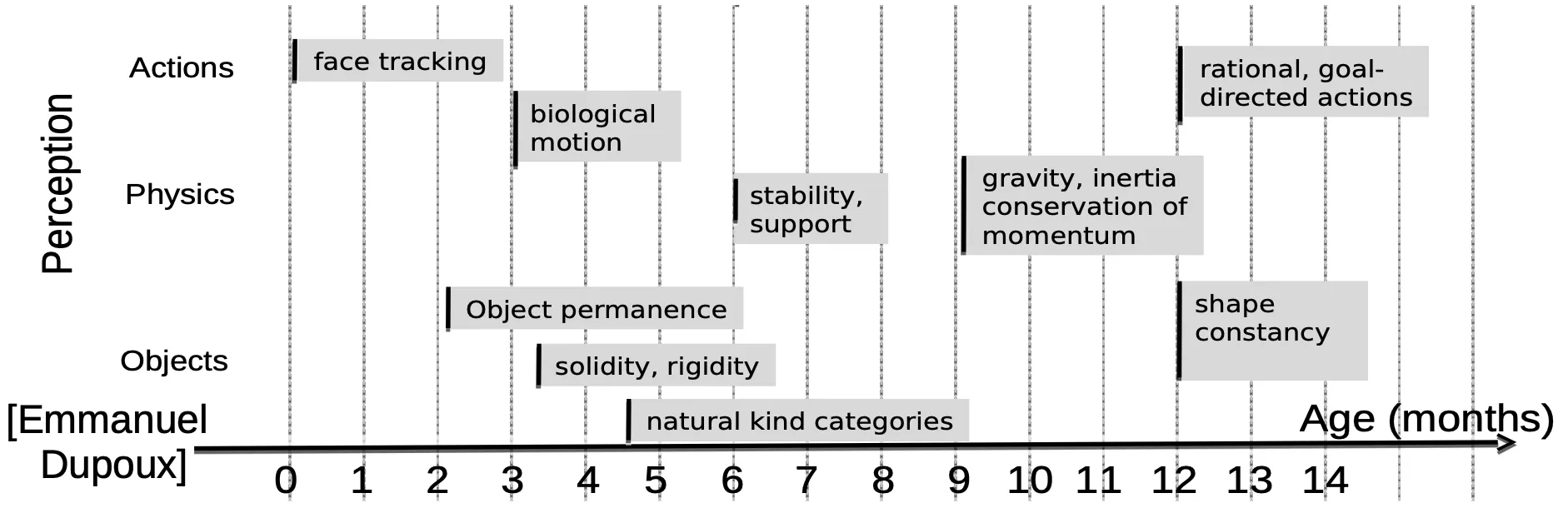
The biggest difference between AI and humans here is the data efficiency gap. While small at the beginning for basic tasks like face tracking and object permanence, the gap only grows larger with age and task complexity.
A framework for building human-level AI
Section titled “A framework for building human-level AI”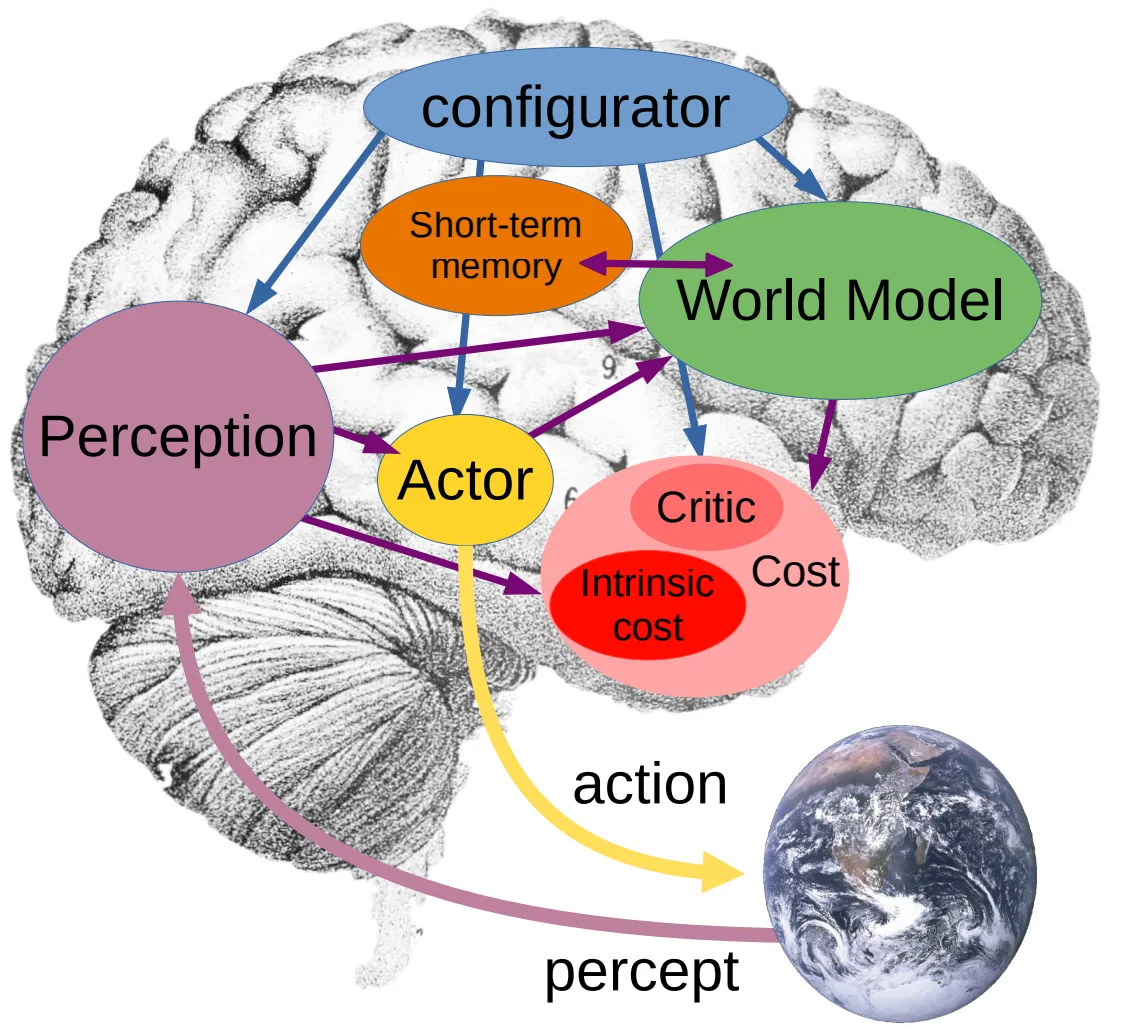
- Configurator: Configures input from all other modules and configures them for the task at hand. It tells the perception module what information to extract.
- Perception: Estimates the current state of the world from different sensory signals.
- World model: Estimates missing information about the state of the world and predicts future states. It simulates the world and extracts relevant information as determined by the configurator.
- Cost module: Measures the level of discomfort as energy. This energy is the sum of the intrinsic cost module and the trainable critic module.
- Intrinsic cost: Computes a cost given the current state of the world and predicted future states. This cost can be imagined as hunger, pain, or general discomfort. This cost can be hardwired in AI agents, as done with rewards in RL.
- Trainable Critic: Predicts future intrinsic energy. It has the same input as the intrinsic cost. This estimate is dependent on the intrinsic cost and cannot be hardwired. It is trained from past states and subsequent intrinsic cost, retrieved from memory.
- Short term memory: Stores relevant information about past present and future states of the world along with intrinsic cost.
- Actor: Proposes sequences of actions. These sequences are executed by the effectors. The world model predicts future states from the sequence which then generates a cost.
Objective driven AI
Section titled “Objective driven AI”The components described above can be used to build an intelligent system that carries out tasks to achieve objectives determined by humans.
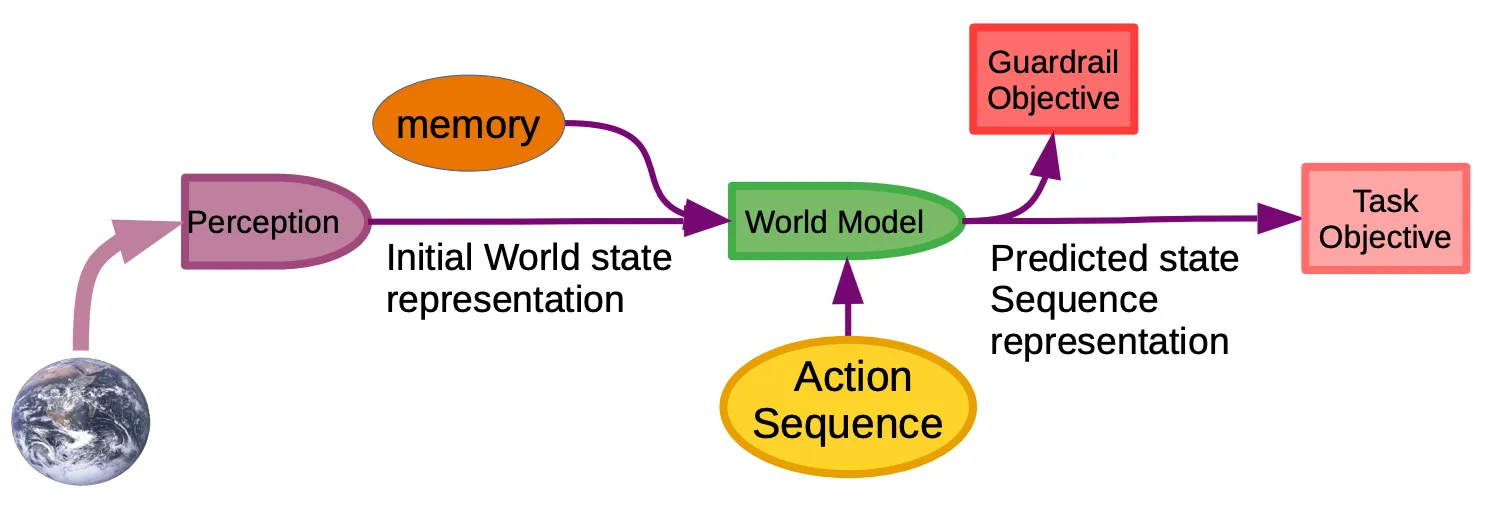
Perception takes in the current state of the world to create an initial state representation. The actor proposes a sequence of actions, which would be used by the world model to predict the future state reached if the sequence is carried out. The task objective determines how far away the predicted future state is from the actual objective. The guardrail objective makes sure the system accomplishes the task without any unwanted behavior, designed for safety (intrinsic cost). Latent variables are introduced to represent the uncertainty in the world model’s predictions.
The action sequence is optimized to minimize the objectives.
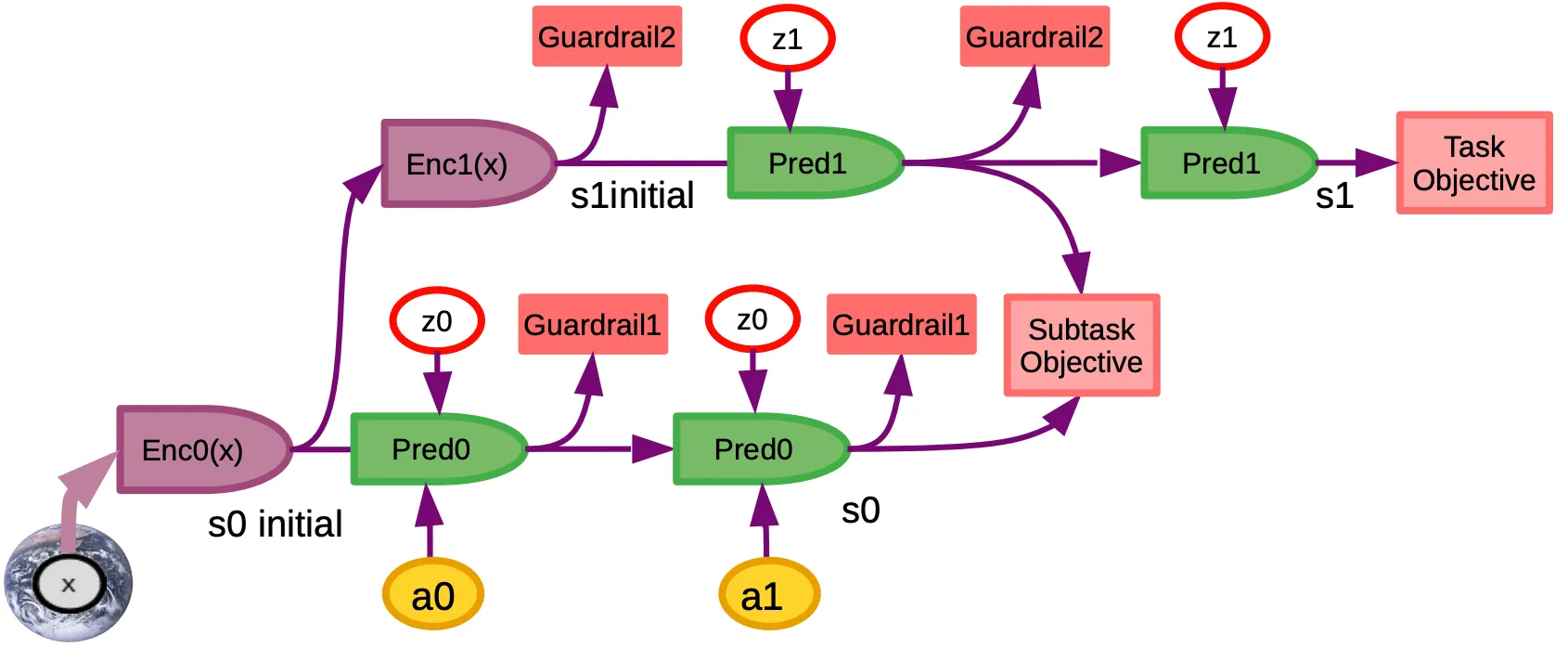
The system can be extended to allow for hierchical planning. The higher levels of planning produce a “wanted” future state which will become the lower levels’ objectives. This state can be considered as a subgoal that is necessary to achieve the higher level goal.
World model
Section titled “World model”In JEPA, the world model is used to predict future representations of the world state. There are 3 main issues:
- The diversity of state sequences the model observes during training
- The world is partially observable, so the model has to predict multiple plausible representations following an action.
- Predictions must be made at different time scales and abstractions.
Energy-based model (EBM)
Section titled “Energy-based model (EBM)”Yann LeCun proposes an self-supervised learning energy-based model (EBM) for training world models.
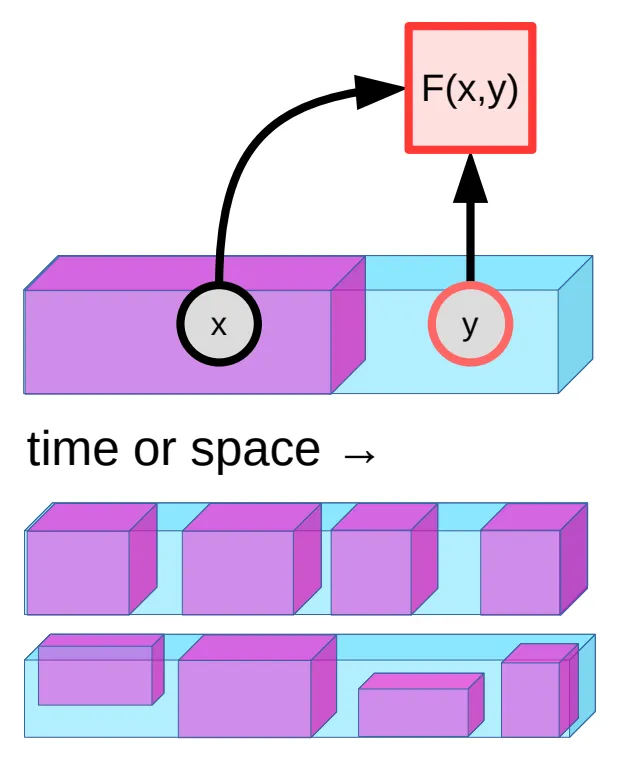
EBM learns an energy function
Predicting exactly
We can’t predict future values of
The encoder will be trained such that the
To handle uncertainty, we introduce a latent variable
The energy function can then be determined by finding the
Model collapse
Section titled “Model collapse”The ideal energy landscape looks like this, where data samples gather around
low-energy valleys and outside are high-energy regions.
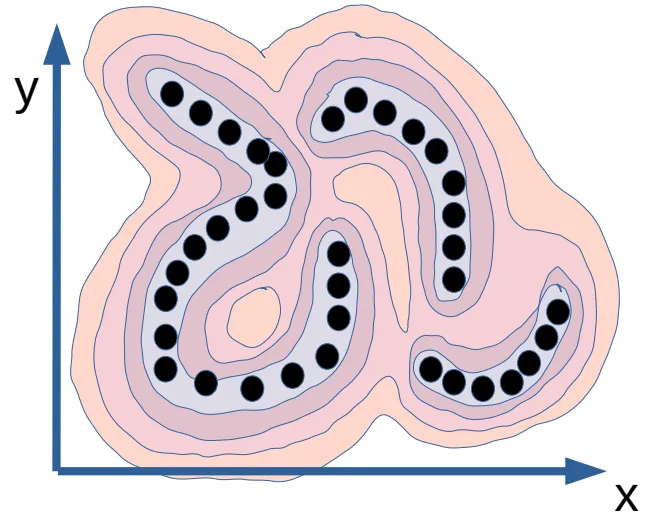
Collapse happens when the energy is low everywhere, which renders the EBM useless. This can happen when the latent variable carry too much information capacity.
Imagine in a frame prediction problem where the sampled
There are two training methods to prevent collapse:
- Contrastive methods: Form peaks around negative data examples. This requires some method to generate negative examples to contrast against. Number of examples needed grow exponentially with the number of the representation dimensions.
- Regularized methods: The loss is regularized to minimize the volume
around
where the valleys are. These are more resistant to the curse of dimensionality. Contrastive architectures can be regularized.
Joint Embedding Predictive Architecture (JEPA)
Section titled “Joint Embedding Predictive Architecture (JEPA)”JEPA is a specific type of EBM designed by Yann LeCun that solves by “pixel problem” by performing predictions in the representation space.
If you’re walking through a field, you can’t predict the exact position of every blade of grass as the wind blows. It’s physically impossible and, more importantly, irrelevant to your goal of walking across the field.
Key features of JEPA:
- Joint-embedding: JEPA uses two encoders to turn the “past” and “future” into
abstract representations (
) - Predictive: it has a “Predictor” module that tries to guess
from and . - Latent space: all the work happens in that abstract “thought space,” never returning to pixels.
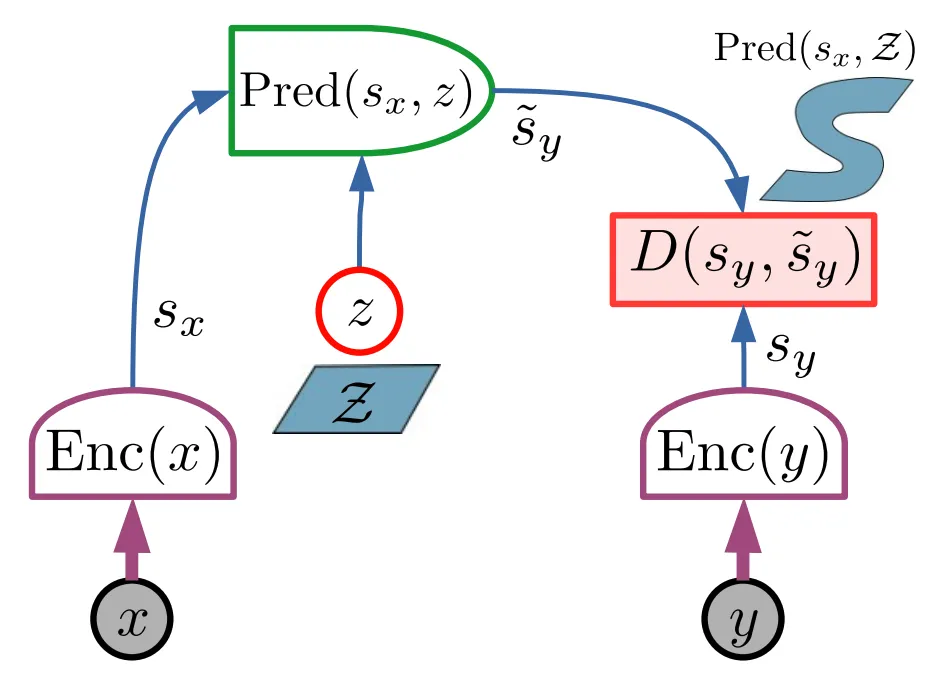
Now ask: when can the predictor succeed? Only when the context encoding contains enough information to determine what must be. If you saw the hood of a car, predicting the representation of the wheels requires that your encoding of the hood captures this is a car. If you saw a face, predicting the representation of the hair requires that your encoding captures identity, pose, and lighting. The predictor cannot hallucinate structure that the context encoding lacks.
This is the forcing function. The context encoder must learn to extract features from that are predictive of ‘s representation. These are exactly the semantic, structural features: object identity, spatial relationships, physical constraints. Pixel-level noise in does not help predict , so the encoder learns to ignore it. What remains is what generalizes.
To be useful, a JEPA model needs multi-modality (in this context, means mathematical modes of a probability distribution, NOT audio, text, video, etc.).
This is achieved by two methods:
- Encoder invariance: throw away noise in the world state. Train
to be blind to details that are unpredictable and irrelevant. As a result, the encoder may map different to the same . - Latent variable predictor: varying
will lead to different plausible predictions of .
There are four criteria that can be used to train this architecture without contrastive loss:
- Maximize the information content of
about : - Maximize the information content of
about : - Make
predictable from : - Minimize the information content of the latent variable with a regularizer:
Hierchical JEPA (H-JEPA)
Section titled “Hierchical JEPA (H-JEPA)”There is a trade off between information loss in the encoding and the predictability of the encodings. If a representation contains most of the information of the input, it would be hard to predict. A more abstract and higher level representation would be lower in dimension and more predictable. Higher dimension representations are also more suitable for longer term predictions.
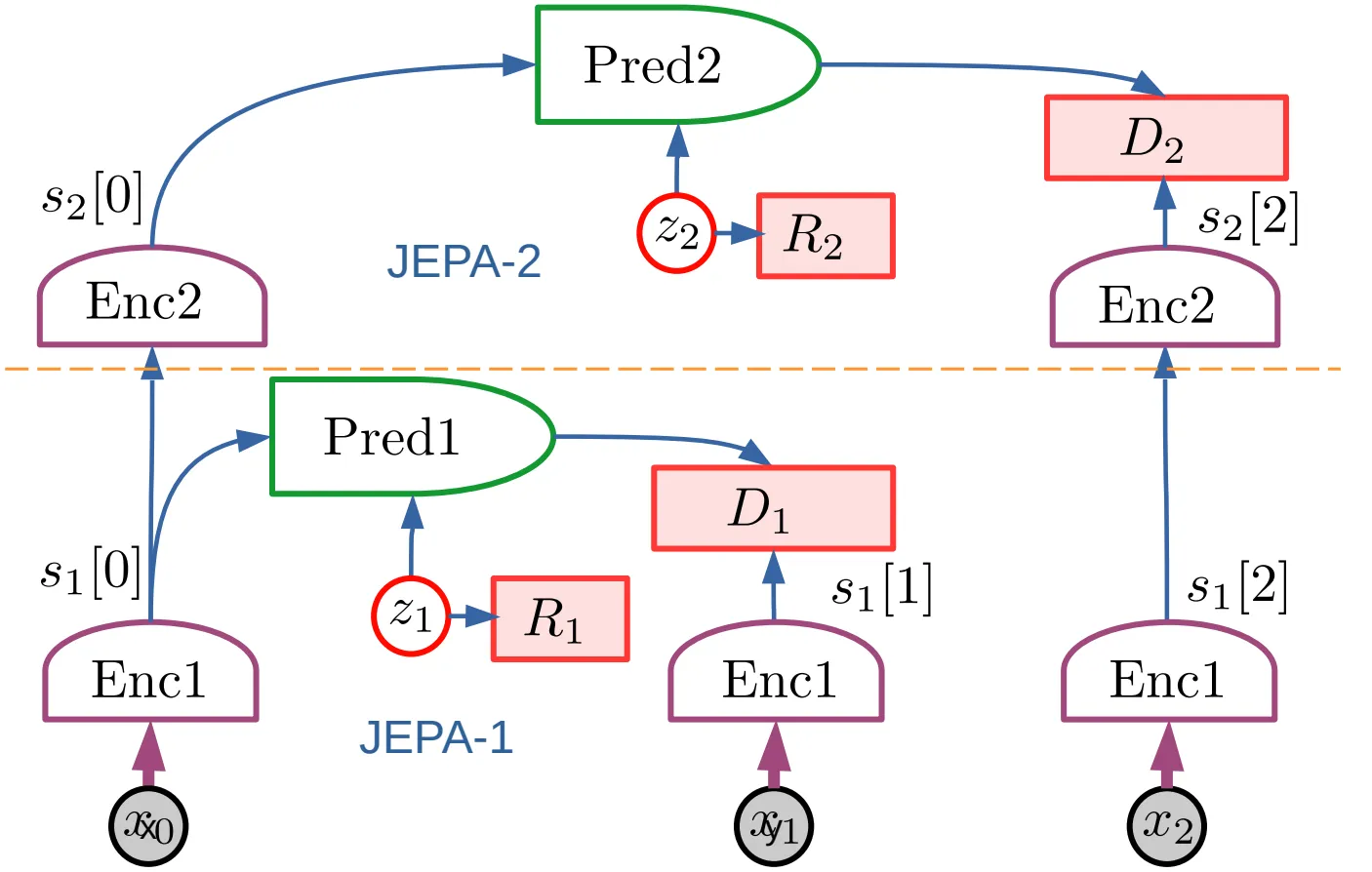
H-JEPA is an implementation of the hierarchical planning architecture described above. Each level of the architecture is a JEPA that predicts the next state representation at its level of abstraction and uses a different encoder.
Implementations of JEPA
Section titled “Implementations of JEPA”From Julian Saks:
- JEPA / H-JEPA: avoids predicting every single pixel (too expensive) and rather predicts in latent space. H-JEPA adds hierarchy - short term details vs long term planning ie. how humans actually learn
- I-JEPA: built for very efficient vision models. Masks image patches and predicts the semantics and in doing so bypasses heavy compute of traditional autoencoders
- MC-JEPA & V-JEPA: both of these are built for videos. MC-JEPA separates content (what an object is) vs motion (how it moves). V-JEPA masks video features with no text labels making it perfect for action tracking at scale
- Audio-JEPA: filters out background noise by treating sounds like visuals
- Point-JEPA & 3D-JEPA: used primarily in AVs. Uses LiDAR point clouds & volumetric grids
- ACT-JEPA: filters out real world noise to learn manipulation tasks efficiently via imitation learning
- V-JEPA 2: predicts future physical states of the world caused by an action before it happens
- LeJEPA: replaces techniques like masking with an Energy-Based Model (EBM) which mathematically prevents “feature collapse” & ensures the model scales reliably as data increases
- Causal-JEPA: for learning true cause-and-effect physics by applying object level masking
- V-JEPA 2.1: great for spatial grounding since it combines a dense predictive loss across image & video
- LeWorldModel: built directly on LeJEPA’s math but super compact - 15M params
- ThinkJEPA: uses dense physical prediction with VLM reasoning. Best used when long-term strategy is needed
See also GraphJEPA for graph-structured data using hyperbolic embeddings, GeneJEPA for single-cell transcriptomics, Signal-JEPA for EEG signals, ST-JEMA for for fMRI functional connectivity, and various time-series JEPAs for sensor data and forecasting.
JEPA is a general pattern for self-supervision in arbitrary domains; whenever you have structured data with natural notions of context and target, you can instantiate the template.
When you see JEPA this way, many design questions become engineering problems. What is your notion of context and target in your domain? What representation space preserves what you care about and discards what you do not? What predictor architecture is expressive enough to solve the predictive problem without learning shortcuts? What anti-collapse mechanism is appropriate: an EMA teacher, explicit covariance regularization, or a distribution-matching regularizer like SIGReg?
Critiques
Section titled “Critiques”Feels exactly like @oordRepresentationLearningContrastive2018.
I-JEPA
Section titled “I-JEPA”- Essentially: MIM with block sampling + MoCo momentum encoder + L2 loss on predictor’s output
- Uses block sampling instead of random sampling while MAE @heMaskedAutoencodersAre2021 shows that empirically, random sampling works better.
- Using a target encoder seems not parameter-efficient, as the only useful part we get out of I-JEPA is the context encoder. Contrast this with the lightweight decoder design in MAE, which constraints the model to learn useful representations in the encoder.
- Looks almost like MoCo’s design @heMomentumContrastUnsupervised2020
- Predictor design needs to be slimmer, might need to even just a linear layer to match evals.
- Spiritual successor of BYOL