The Twelve-Factor App
- Introduction
- The twelve-factor app is a methodology for building SaaS apps that
- Use declarative formats for setup automation, to minimize time and cost for new developers joining the project;
- Have a clean contract with the underlying operating system, offering maximum portability between execution environments;
- Are suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration;
- Minimize divergence between development and production, enabling continuous deployment for maximum agility;
- And can scale up without significant changes to tooling, architecture, or development practices.
- The twelve-factor app is a methodology for building SaaS apps that
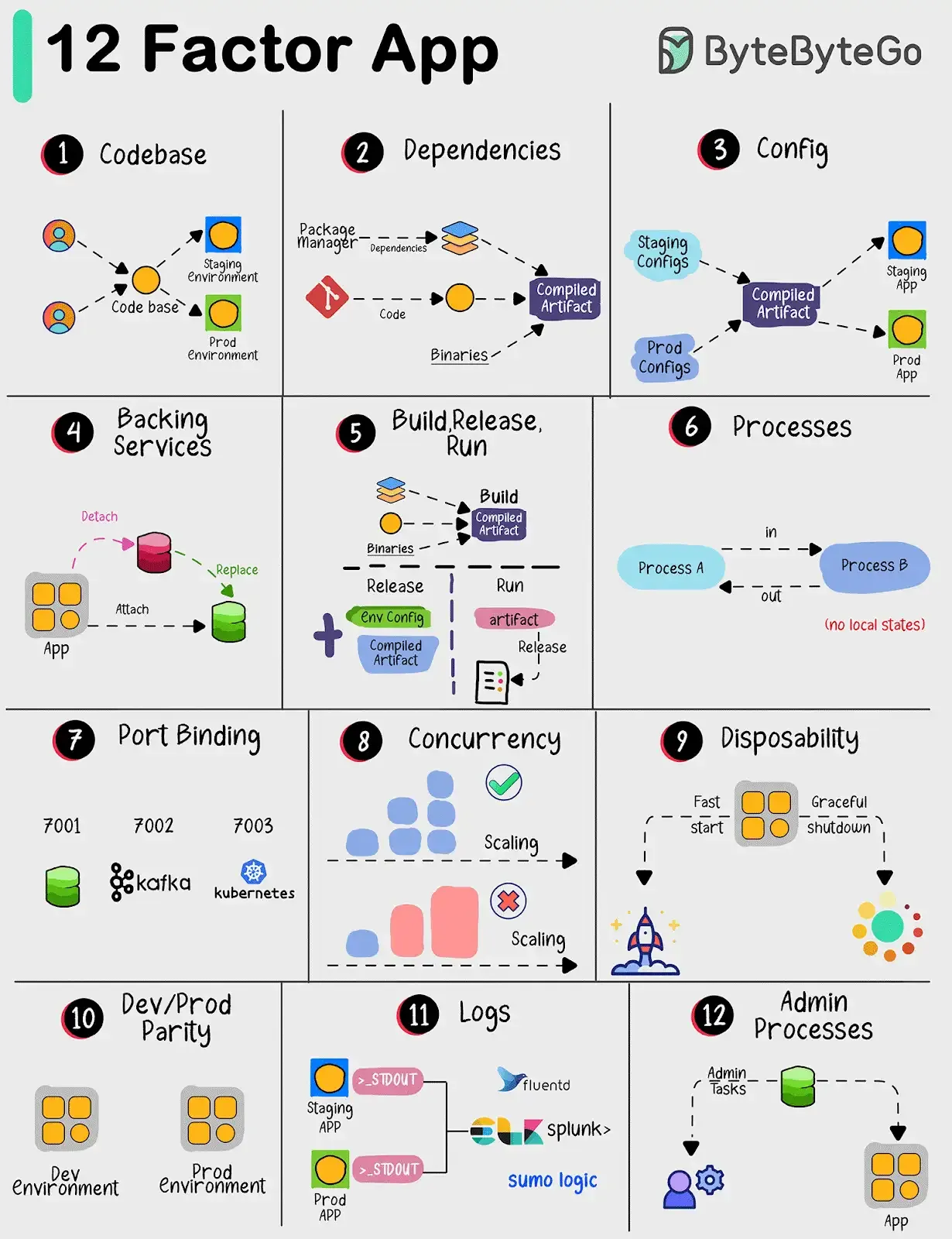
- The twelve factors (TF)
- Codebase — one codebase tracked in revision control, many deploys
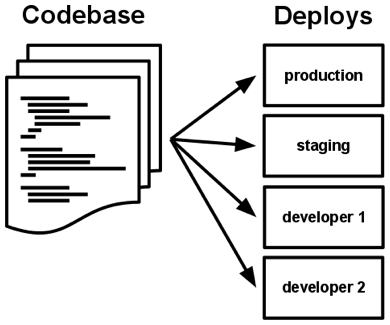
- A TF app is always tracked in a VSC (Git, Mercurial, Subversion)
- A copy of the revision tracking database is known as a code repository (repo)
- A codebase is any single repo (in a centralized revision control system like Subversion), or any set of repos who share a root commit (in a decentralized revision control system like Git)
- There is always a one-to-one correlation between the codebase and the app
- If there are multiple codebases, it’s not an app — it’s a distributed system. Each component in a distributed system is an app, and each can individually comply with twelve-factor.
- Multiple apps sharing the same code is a violation of twelve-factor. The solution here is to factor shared code into libraries which can be included through the dependency manager.
- There will be many deploys of the app. A deploy is a running instance of the app
- The codebase is the same across all deploys, although different versions may be active in each deploy
- Dependencies — explicitly declare and isolate dependencies
- Most programming languages offer a packing system for distributing support libraries (npm, pip,…)
- Libraries installed through a packing system can be installed system-wide (“site packages”) or scoped into the directory containing the app (“vendoring”/“bundling”)
- A TF app never relies on the implicit existence of system-wide packages
- It declares all dependencies, completely and exactly, via a dependency declaration manifest
- It uses a dependency isolation tool during execution to ensure that no implicit dependencies “leak in” from the surrounding system
- This full and explicit dependency specification is applied uniformly to both production and development
- Benefits
- Simplifies setup for developers new to the app → only need to checkout the app’s codebase on their development machine, requiring only the language runtime and dependency manager installed as prerequisites
- Config — store config in the environment
- An app’s config is everything likely to vary between deploys (staging,
production, developer environments, etc)
- Resource handles to the database, Memcached, and other backing services
- Credentials to external services such as Amazon S3 or Twitter
- Per-deploy values such as the canonical hostname for the deploy
- Strict separation of config from code. Config varies substantially across deploys, code does not
- Litmus test → The codebase could be made open-source at any moment, without compromising any credentials
- However, this definition of “config” does not include internal application config (e.g. routes, etc.)
- The TF app stores config in environment variables
- Env vars are easy to change between deploys without changing any code
- Unlikely to be checked into the code repo accidentally
- Language- and OS-agnostic standard
- An app’s config is everything likely to vary between deploys (staging,
production, developer environments, etc)
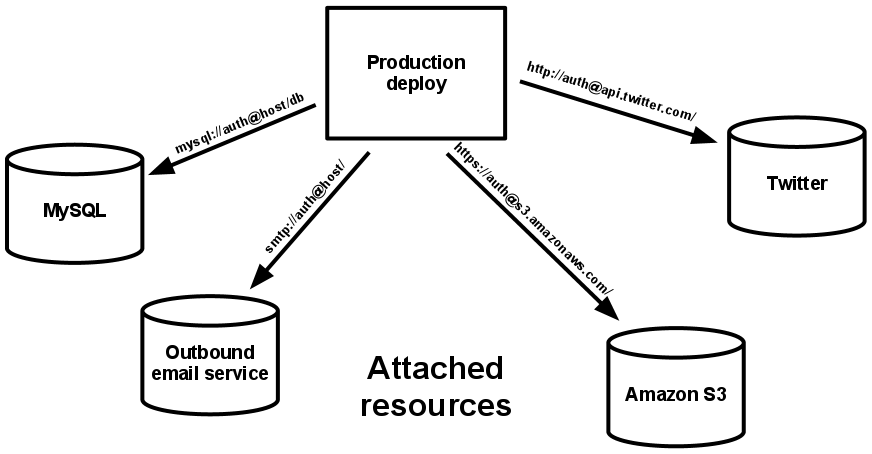
- Backing services — treat backing services as attached resources
-
A backing service is any service the app consumes over the network as part of its normal operation
- Locally-managed services
- Datastores (MySQL, CouchDB)
- Messaging/queueing systems (RabbitMQ, Beanstalkd)
- SMTP services for outbound emails (Postfix)
- Caching systems (Memcached)
- Third-party managed services
- SMTP services (Postmark)
- Metrics-gathering services (New Relic, Loggly)
- Binary asset services (Amazon S3)
- API-accessible consumer services (Twitter, Google Maps, Last.fm)
- Locally-managed services
-
The code for a TF app makes no distinction between local and third-party services
- Both are attached resources, accessed via a URL or other locator/credentials stored in the config/env vars
- A deploy of the TF app should be able to swap out a local service with one managed by a third party without any changes to the app’s code
- Only the resource handle in the config needs to change
-
Each distinct backing service is a resource
- A MySQL database is a resource, two MySQL databases (used for sharding at the application layer) qualify as two distinct resources
- Attached resources are loosely coupled to the deploy they are attached to
- Resources can be attached to and detached from deploys at will without any code changes
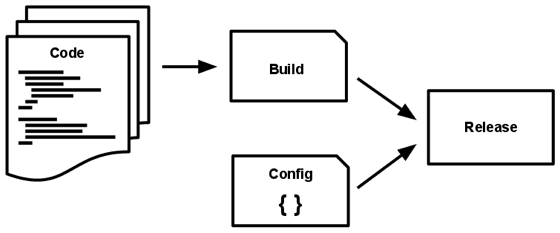
- Build, release, run — strictly separate build and run stages
- A codebase is transformed into a (non-development) deploy through three
stages
- Build: code repo —(transform)→ an executable bundle (build)
- The build stage fetches vendors’ dependencies and compiles binaries and assets
- Release: build + deploy (the current deploy’s) → release
- The release contains both the build and the config ready for immediate execution in the execution environment
- Run/runtime: launch some set of the app’s processes against a selected release to run the app in the execution environment
- Build: code repo —(transform)→ an executable bundle (build)
- The TF app uses strict separation between the build, release, and run
stages
- It is impossible to make changes to the code at runtime, since there is no way to propagate those changes back to the build stage
- Deployment tools typically offer release management tools (rollback to previous release, etc.)
- Every release should always have a unique release ID, such as the timestamp
of the release or an incrementing number
- Treat releases as an append-only and immutable ledger
- Any change must create a new release
- Builds are initiated by the app’s developers whenever new code is deployed
- Runtime execution can happen automatically with reboot/restart by the server or process manager → the run stage should be kept to as few moving parts as possible
- The build stage can be more complex since errors are always in the foreground for a developer who is driving the deploy
- A codebase is transformed into a (non-development) deploy through three
stages
- Processes — execute the app as one or more stateless processes
- The app is executed in the execution environment as one or more processes
- A production deploy of an app may use many process types, instantiated into zero or more running processes
- TF processes are stateless and share-nothing
- Any data that needs to persist must be stored in a stateful backing service, typically a database
- The memory space or filesystem of the process can be used as a brief, single-transaction cache
- The TF app never assumes that anything cached in memory or on disk will be available on a future request or job
- With many processes of each type running, chances are high that a future request will be served by a different process
- A restart (triggered by code deploy, config change, or the execution
environment relocating the process to a different physical location) will
usually wipe out all local state
- “Sticky sessions” — caching user session data in memory of the app’s process and expecting future requests from the same visitor to be routed to the same process — violates TF and should never be used
- Session state data is a good candidate for a datastore that offers time-expiration, such as Memcached or Redis
- The app is executed in the execution environment as one or more processes
- Port binding — export services via port binding
- Web apps are sometimes executed inside a webserver container
- The TF app is completely self-contained and does not rely on runtime injection of a webserver into the execution environment to create a web-facing service
- The web app exports HTTP as a service by binding to a port, and listening to requests coming in on that port
- Local development
- The developer visits a service URL like
http://localhost:5000/to access the service exported by their app
- The developer visits a service URL like
- Deployment
- A routing layer handles routing requests from a public-facing hostname to the port-bound web processes
- Add a webserver to an app by using dependency declaration, which happens in the app’s code
- The contract of the app with the execution environment is binding to a port to serve requests
- Nearly any kind of server software can be run via a process binding to a
port and awaiting incoming requests
- HTTP, XMPP, Redis protocol
- Port-binding approach means that one app can become the backing service for another app by providing the URL to the backing app as a resource handle in the config for the consuming app
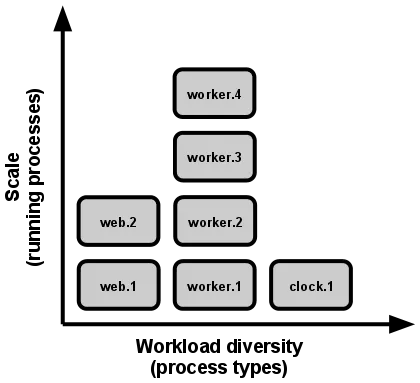
- Concurrency — scale out via the process model
- In the TF app, processes are a first-class citizen
- TODO: continue when have enough knowledge
- Disposability — maximize robustness with fast startup and graceful shutdown
- The TF app’s processes are disposable, meaning they can be started or stopped at a moment’s notice
- Benefits
- Fast elastic scaling
- Rapid deployment of code or config changes
- Robustness of production deploys
- Short startup time provides more agility for the release process and scaling up
- Robustness of production processes → The process manager can easily move processes to new physical machines when warranted
- Processes should strive to minimize startup time
- Processes shutdown gracefully when they receive a SIGTERM signal from the
process manager
- For a web process, graceful shutdown is ceasing listening on the service
port (refusing any new requests), allowing any current requests to finish,
and then exiting
- Assumption: HTTP requests are short
- For web processes with long polling, the client should seamlessly attempt to reconnect when the connection is lost
- For a worker process, graceful shutdown is achieved by returning the current job to the work queue
- For a web process, graceful shutdown is ceasing listening on the service
port (refusing any new requests), allowing any current requests to finish,
and then exiting
- Processes should be robust against sudden death, in the case of hardware failure → robust queueing backend that returns jobs to the queue when clients disconnect or time out
- Dev/prod parity — keep development, staging, and production as similar as
possible
- The gap between development (a developer making live edits to a local deploy
of the app) and production (a running deploy of the app accessed by end
users) manifest in three areas
- The time gap: Local changes may a long time to go into production
- The personnel gap: Developers write code, ops engineers deploy it
- The tools gap: Developers may be using a stack like Nginx, SQLite, and OS X, while the production deploy uses Apache, MySQL, and Linux
- The TF app is designed for continuous deployment by keeping the gap
between development and production small
- Make the time gap small: write code and have it deployed hours or even minutes later
- Make the personnel gap small: developers who wrote code are closely involved in deploying it and watching its behavior in production
- Make the tools gap small: keep development and production as similar as possible
- Backing services, such as the app’s database, queueing system, or cache, is
one area where dev/prod parity is important
- Many languages offer libraries that simplify access to the backing service (ORMs, Celery,…)
- Developers may find great appeal in using a lightweight backing service in their local environments and a more serious one in production
- The TF developer resists the urge to use different backing services
between development and production, even when adapters theoretically
abstract away any differences in backing services
- Tiny incompatibilities may crop up
- Lightweight local services are less compelling than they once were
- Declarative provisioning tools (Chef, Puppet, Ansible, Terraform) + light-weight virtual environments (Docker, Vagrant) → run local environments that closely approximate production environments
- The gap between development (a developer making live edits to a local deploy
of the app) and production (a running deploy of the app accessed by end
users) manifest in three areas
- Logs — treat logs as event streams
- Logs provide visibility into the behavior of a running app
- In server-based environments, they are typically written to a file on disk (a “logfile”)
- Logs are the streams (not files) of aggregated, time-ordered events
collected from the output streams of all running processes and backing
services
- In their raw form, text format with one event per line (backtraces from exceptions may span multiple lines)
- No fixed beginning or end, flow continuously as long as the app is operating
- A TF app never concerns itself with routing or storage of its output stream. It should not attempt to write to or manage logfiles
- Each running process writes its event stream, unbuffered, to stdout
- In local development, the developer will view this stream in the foreground of their terminal to observe the app’s behavior
- In staging or production deploys, all streams are captured and collated by the execution environment and routed to one or more final destinations for viewing and long-term archival
- These archival destinations are not visible to or configurable by the app and instead are completely managed by the execution environment
- Open-source log routers (Logplex, Fluentd) are available for this purpose
- The event stream for an app can be routed to a file, or watched via realtime tail in a terminal
- The stream can be sent to a log indexing and analysis system (Splunk), or a
general-purpose data warehousing system (Hadoop/Hive) → introspecting an
app’s behavior over time
- Finding specific events in the past
- Large-scale graphing of trends (such as RPM)
- Active alerting according to user-defined heuristics (such as an alert when the quantity of errors per minute exceeds a certain threshold)
- Logs provide visibility into the behavior of a running app
- Admin processes — run admin/management tasks as one-off processes
- The process formation is the array of processes used to do the app’s regular business (such as handling web requests) as it runs
- Developers will often wish to do one-off administrative or maintenance tasks
for the app
- Running database migrations
- Running a console (REPL shell) to run arbitrary code or inspect the app’s models against the live DB
- Running one-time scripts committed into the app’s repo
- One-off admin processes should be run in an identical environment as the
regular long-running processes of the app
- Run against a release, using the same codebase and config as any process run against that release
- Admin code must ship with application code to avoid synchronization issues
- Dependency isolation techniques should be used on all process types
- In a local deploy, developers invoke one-off admin processes by a direct shell command inside the app’s checkout directory
- In a production deploy, developers can use ssh or other remote command execution mechanism provided by that deploy’s execution environment to run such a process
- The Twelve-Factor Container
- Codebase — one codebase tracked in revision control, many deploys
- Dependencies — explicitly declare and isolate dependencies
- Containers have dependencies that all live in layers 1 through n of your built image
- Pin the tag of your base image
- Config — store config in the environment
- Kubernetes: Use a ConfigMap (or a Secret) to pass information into environment variables
- Do not bake confidential data into your container images
- Backing services — treat backing services as attached resources
- Kubernetes treats everything in the cluster as a Service (in a Kubernetes sense)
- Services in the the cluster communicate through their published APIs
- Build, release, run — strictly separate build and run stages
- Make multi-stage build for your app
- In the run stage, place compiled or produced artifacts or binaries into a new image and hand that off for testing and release
- Processes — execute the app as one or more stateless processes
- The interaction between client and server are stateless
- Twelve factor asks you to treat local storage as ephemeral, cloud-native recommends making it immutable
- Cloud-native approach is to wrap each stateless process in its own container
- Shared-nothing, stateless containers make related services such as load balancing much more easy to design, implement and operate
- Port binding — export services via port binding
- Concurrency — scale out via the process model
- Containers scale by running more of themselves
- The application runs in the foreground, in only one running process, of the container (doesn’t detach and become a daemon) and relies on an external agent to supervise it
- Spot wrongly built image with Docker and the PID 1 zombie reaping problem
- Disposability — maximize robustness with fast startup and graceful shutdown
- Container runtime adds some overhead to the startup and shutdown processes
- Even so, it beats the VM approach by a wide margin
- This calls for a failure-tolerant design
- Your stateless app needs to track its work backlog using a remote, clustered service (or not have a work backlog at all)
- Long-running tasks should have a “dying gasp” behaviour that stops progress and explicitly returns part-processed jobs the queue
- Dev/prod parity — keep development, staging, and production as similar as
possible
- Don’t have a Dockerfile that’s special to each environment
- Instead, build artefacts once and promote them during release
- Logs — treat logs as event streams
- Cloud-native has a lot of logging standards to choose from
- Docker json-file output: each line is a separate JSON document, timestamped in a key called time.
- Text: the application writes to standard output and standard error, and each line represents a new entry. The container runtime captures timestamps and other metadata. (This is what the 12 Factor methodology recommends).
- fluentd: a popular de facto standard and often used with containers.
- Graylog Extended Log Format, another popular standard.
- OpenTelemetry: logging, metrics and tracing all in one.
- Syslog: this is actually a family of related standards. In theory you can have structured metadata, message authenticity checks and more; in practice, it’s rare to have both the client and the server implement those features how you want them to.
- Cloud-native has a lot of logging standards to choose from
- Admin processes — run admin/management tasks as one-off processes
- Use the same container image to run the regular app and to execute one off
tasks
- Might have multiple entrypoints, or one entrypoint with different subcommands
- In Kubernetes, this work belongs to the Job rather than a long-running
Deployment or StatefulSet
- May use the operator pattern to take care of maintenance tasks: running database migrations, backups, and more
- Depending on the application, you might be able to move repair tasks and DB schema setup into the main app
- Use the same container image to run the regular app and to execute one off
tasks