Distributed Systems
- Proxy
-
A server or software that mediates internet traffic flow (e.g., making HTTP requests). There are two types
-
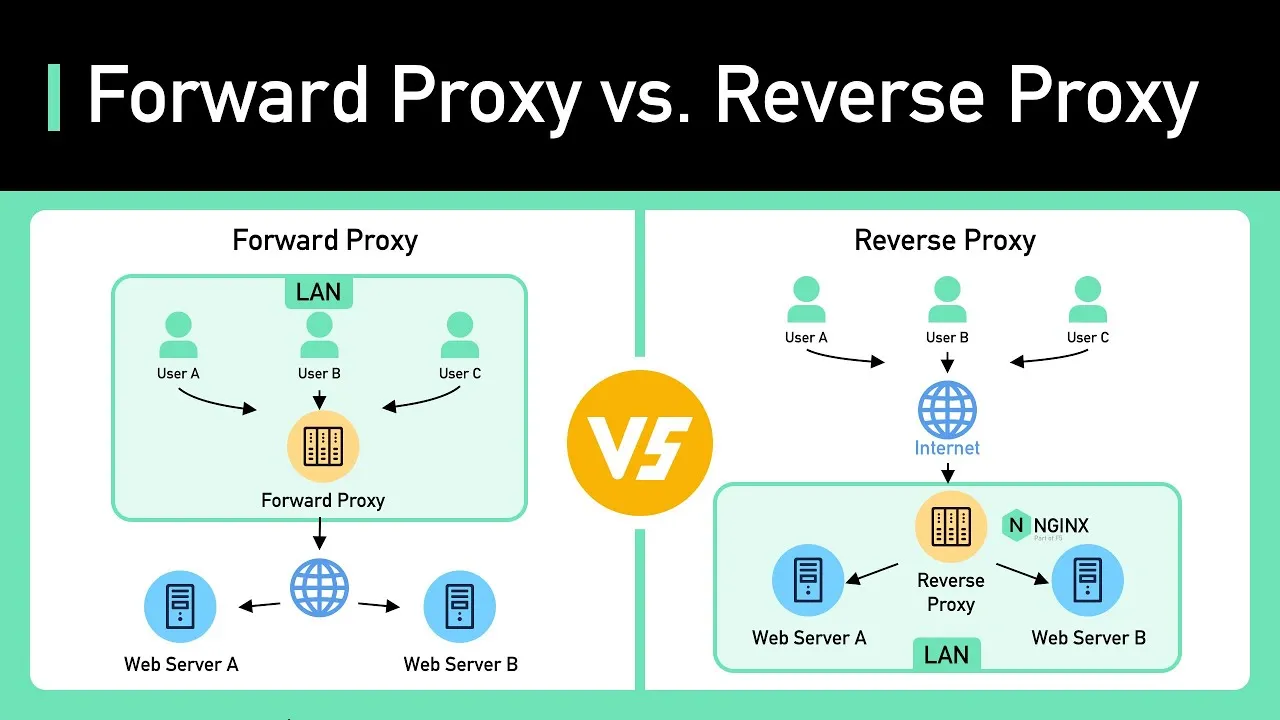
Forward proxy
-
Provides single or multiple clients with access to a proxy service on a common internal network
-
Acts as an intermediary that performs tasks on behalf of clients over the Internet
-
Each request before it reaches the server first passes through the proxy server, which then executes it
-
Benefits
-
Protects the client’s online identity → The IP address of the client is hidden, only the IP address of the forward proxy is visible
-
Bypass browsing restrictions (firewalls)
-
Block clients’ access to certain content
-
-
-
Reverse proxy
-
Intercepts the requests from clients and talks to the web server on behalf of the clients
-
Benefits
-
Protect a website against a DDOS attack → The website’s IP addresses are hidden from the clients
-
Load balancing by distributing the traffic to a large pool of web servers and preventing any one of them from becoming overloaded
- Assumption: the proxy server can handle a large amount of incoming requests
-
Cache static content
-
Handle SSL encryption
-
-
-
-
Best practices for HTTP requests in production
-
Retries: Requests may occasionally fail due to transient issues (e.g., slow network, node failure, power outage, spike in traffic, etc.). Retry failed requests a handful of times to account for these issues.
-
Exponential backoff: To avoid bombarding the application with retries during a transient error, apply an exponential backoff on failure. Each retry should wait exponentially longer than the previous one before running. For example, the first retry may wait 0.1s after a failure, and subsequent retries wait 0.4s (4 x 0.1), 1.6s, 6.4s, 25.6s, etc. after the failure.
-
Timeouts: Add a timeout to each retry to prevent requests from hanging. The timeout should be longer than the application’s latency to give your application enough time to process requests.
-
-
Best practices for HTTP clients
-
The I.D.E.A.L. HTTP client
-
I --- Investing in stability (mandatory)
-
Network is unreliable, services are unpredictable → HTTP communications are unstable → Needs stability
-
Timeouts
-
Set timeouts for all external requests
-
Don’t let services hang indefinitely
-
Reasonably low duration — several seconds is sufficient
-
Long-enough hanging requests should be failed to allow the application to degrade gracefully while missing some functionality
-
Fail fast and loud (Erlang/Elixir philosophy)
-
Should be set wherever possible (database, cache, etc.)
-
-
Error handling
-
Always expect and handle HTTP errors gracefully
-
Use custom error classes
- Can easily group them in error reporting system
-
Craft a consistent error hierarchy
-
-
-
-

-
Retries
-
Attempt to retry requests to simplify things when recovering from sneaky flapped errors
-
Idempotent requests are safe for retries (GET, HEAD, PUT, DELETE, OPTIONS, TRACE), never try non-idempotent requests (POST, PATCH)
-
Limit the number of retries and the time between them to make way for service recovery
- Retry with exponential backoff
-
Multiple processes waiting for the same event simultaneously triggered once the event happens
- Thundering herd problem
-
More advanced: circuit breaker pattern
- Prevent overloading services with retries
-
-
D --- Debugging uncertainties (mandatory)
-
Logging, monitoring, error reporting
- Keep logs of external requests
-
User-agents
- Identify the HTTP client on our side to other services
-

-
Correlation ID and tracing
- Add a correlation ID to your HTTP client to track requests to external services in the logs and to correlate them within request and response pairs

-
E --- Exploring the client (mandatory)
-
Configuration
-
Keep configuration clean and directed to a single service
-
The best configuration is no configuration
- Keep the defaults sane for end users
-
-
Performance
-
Beware of memory exhaustion due to larger file downloads or uploads
- Stream large files instead of loading them into memory
-
Fine-tune HTTP client based on application-specific performance metrics
-
Leverage HTTP/2 for connection reuse
-
Employ binary protocols to reduce payload sizes
-
Some methods require collaboration with upstream services
-
Parallelize requests
-
HTTP caching
-
Persistent connections
-
-
Benchmark your application to find the best approach
-
-
Standardization
- Have a standardized way to handle external requests in an application
-
-
A --- Advancing with abstractions (opinionated)
-
HTTP client as a library
-
An HTTP client can be separated into several reused layers
-
Configuration
-
Unified error handling and error hierarchy
-
Retry
-
Logging and monitoring facilities
-
API client
-
Domain models
-
-
-
-
L --- Laying out a sound structure (opinionated)
- Typed domain models
-
Testing
- Use a contract testing approach to ensure that the HTTP client works as expected
-
MapReduce
-
Programming model for distributing and parallelizing a large computation over a cluster of machines → Faster execution time
-
Developed at Google
-
High-level workflow
-
The user
-
Define the map function
-
Define reduce function
-
-
MapReduce
-
Partition input data
-
Schedule tasks
-
Handle machine failures
-
Facilitate inter-machine communication
-
-
-
Deep dive
-
The MapReduce library splits the input into M chunks based on what the user specified
-
Make copies of the program for the machines in the cluster
-
One of them is the master, the rest are workers
-
The workers will be given map task or reduce task (M map tasks and R reduce tasks in total)
-
-
The worker with a map task executes the user-defined map function on an input chunk
-
The value returned (an intermediate key-value pair) will first be saved in RAM (buffered in memory)
-
Eventually persisted on the worker’s local disk, which is partitioned into R regions/files
- One for each unique key of the R reduce tasks
-
The file paths of intermediate key-value pairs are passed back to the master
-
The master then forwards these locations to the reduce workers
-
-
The reduce worker gets all key-value pairs associated with the reduce task’s key
- Once it has all the key-value pairs, it will pass them to the reduce function and save the output to a globally available storage (S3, GFS)
-
The MapReduce returns the output to the user
-
-
-
CRDT (Conflict-free Replicated Data Type)
-
A data structure that can be stored on different computers (peers)
-
Each peer can update its own state instantly, without a network request to check with other peers
-
Peers may have different states at different points in time, but are guaranteed to eventually converge on a single agreed-upon state
-
Great for building rich collaborative apps without requiring a central server to sync changes
- E.g., Google Docs, Figma
-
Two kinds of CRDTs
-
State-based
-
Transmit their full state between peers
-
A new state is obtained by merging all the states together
-
-
Operation-based
- Transmit only the actions that users take, which can be used to calculate a new state
-
-
Operation-based CRDT
-
+ more efficient → only send differential state
-
- constraint on communication channel: exact-once delivery, in causal order, to each peer
-
-
State-based CRDTs
- Any data structure that implements this interface
interface CRDT<T, S> {
value: T;
state: S;
merge(state: S): void;
}
-
-
value: the part that the rest of our program cares about
-
state: the metadata needed for peers to agree on the same value
- To update other peers, the whole state is serialized and sent to them
-
merge function: takes some state (possibly received from another peer) and merges it with the local state