CS 3013: Operating Systems
-
What happens when a program runs?
-
It executes instructions, very fast!
-
Von Neumann computation model: Fetch (an instruction from memory) - decode (figure out which instruction this is) - execute (does the thing) cycle
-
While a program runs, other wild things are going on to make the system easy to use → the operating system (OS)
- Make sure the system operates correctly, efficiently in an easy-to-use manner
-
This is done through virtualization
-
Transform a physical resource (processor, memory, disk) into a more general, powerful, and easy-to-use virtual form
-
Why OS is also referred to as a virtual machine
-
-
OS provides some APIs for users/applications to tell it what to do and make use of its features
- Called system calls/standard library
-
Since virtualization allows many programs to run (sharing processor), many programs to concurrently access their own instructions and data (sharing memory), and many programs to access devices
- OS also called resource manager
-
OS use policies to determine which program runs when
-
-
Tips/Terminology
-
<C-c> on UNIX-based system terminates the program running in the foreground
-
killall <process_name> kills all instances of a program
-
Model of physical memory in modern machines
-
Represented by an array of bytes
-
Read memory by accessing data at an address
-
Write memory by specifying the data to be written to the given address
-
While a program is running, the memory contains (so called in-memory)
-
All of the program’s data structures
-
All of the program’s instructions (to load and store or other memory instructions)
-
-
Memory is accessed on each instruction fetch
-
-
A shell — a program that allows users to interact with an operating system by typing commands
-
The shell provides pipes to enable meta-programming → easy to string together programs to accomplish a bigger task (originated from the UNIX OS and its core principle)
-
A device driver is some code in the operating system that knows how to deal with a specific device
-
-
Design goals of an OS
-
Performance: minimizes OS overhead in the form of time (number of instructions) and space (in memory or on disk)
-
Reliability: runs non-stop because it’s a single point of failure for all programs running on it
-
Security/protection/isolation: malicious behavior of a process should not affect other processes or the OS itself
-
Mobility/portability: runs on many different devices
-
-
Virtualization

-
CPU
- OS turns a single CPU (or a small set of them) into a seemingly infinite number of them → allowing multiple programs to run at once
-
Memory
-
Each process has its own private virtual address space, which the OS maps to the underlying physical memory
-
Memory references of a process does not affect other running processes’ address spaces and the OS itself
-
-
Chapter 4: Processes
-
The process is a running program
-
Program itself doesn’t do anything — just a bunch of instructions (and static data) sitting on disk
-
The OS takes these bytes and run them → turns it into a process
-
-

-
The OS does this by virtualizing the CPU — running one process, then stopping it and run another — time sharing of the CPU
-
+ Can run many concurrent processes
-
- Performance cost
-

-
CPU virtualization requires low-level machinery (mechanisms) and high-level intelligence (policies)
-
Mechanisms
-
Low-level methods or protocols that implement a needed piece of functionality
-
E.g., context switch allows the OS to stop running one program and start another on a given CPU
-
-
Policies
-
Algorithms for making decisions in the OS
-
E.g., the OS depends on a scheduling policy to decide which program to run given some programs
-

-
At any point in time, a process can be described by its machine state — its interaction with the system during its execution. This consists of
-
Memory in its address space
-
Instructions
-
Data that the program R/W
-
-
Contents of CPU registers
-
Program counter (PC, aka instruction pointer (IP)) — which instruction of the program will execute next
-
Stack pointer and frame pointer — manage the stack for function parameters, local variables, and return addresses
-
-
I/O information
- List of files the process currently has open
-
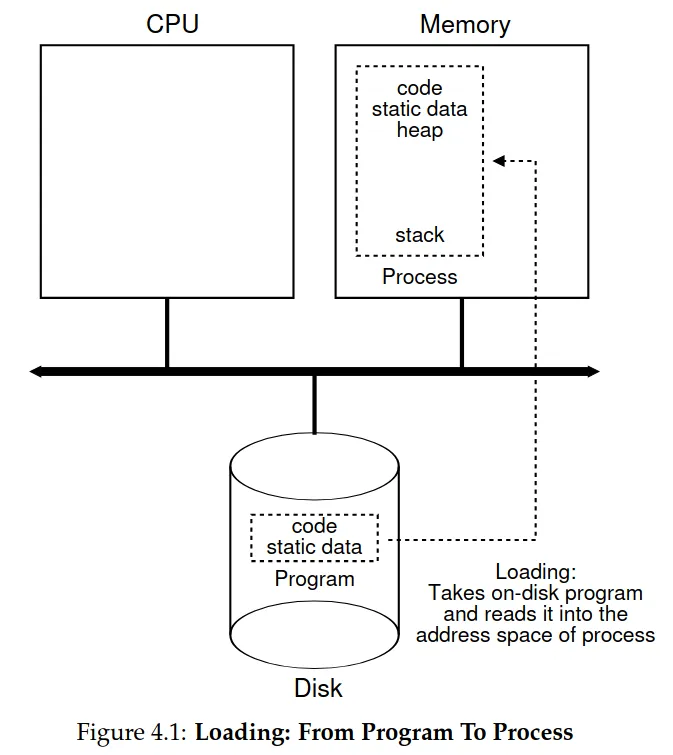
- Process creation: how does the OS run a program/create a process?
-
The program initially resides on disk (or flash-based SSDs) in an executable format
-
Load the program’s code and static data (e.g., initialized variables) into memory/address space of the process
a. Early OSes load programs eagerly while modern ones do this lazily via paging and swapping mechanisms
-
Allocate memory for the run-time stack
a. C programs use this for local variables, function parameters, and return addresses
b. OS will also likely initialize the stack with arguments (argc and argv array of the main() function)
-
The OS may also allocate memory for the program’s heap
a. C programs use this for explicitly requested dynamically-allocated data (malloc(), free())
b. May start small and expanded via malloc() library API (the OS gets invoked and allocates more memory to the process to satisfy these calls)
-
Other initialization tasks like I/O setup
a. In UNIX systems, each process by default has 3 open file descriptors (stdin, stdout, stderr) — let programs easily read input from the terminal and print output to the screen
-
Start the program at the entry point (main())
a. By jumping to the main() routine, the OS transfers control of the CPU to the new process and begins its execution
- Process exists in one of many **process states**- Simplified view: 3 states
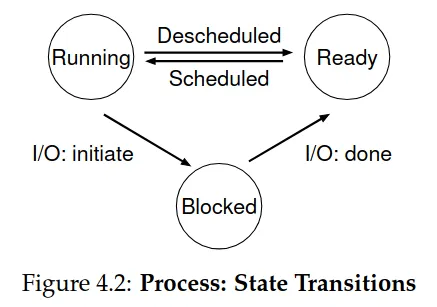
-
Running: a process is running on the processor (executing instructions)
-
Ready: a process is ready to run but has not at the moment
-
Blocked: a process has performed an operation that makes it not ready to run until some event takes place
- E.g., when a process initiates an I/O request to a disk, it becomes blocked and thus the processor is free to use by others
-
Different events transition a process from one state to another

-
An OS scheduler makes decisions about which process runs when
-
A process list has information about all system processes
- Each entry is contained in a process control block (PCB)/process descriptor — just a structure that contains a process information

-
The register context holds the contents of a stopped process’ registers so it can restore these (i.e., place the values back into the actual physical registers) when the OS resumes running it → context switching
-
Some more states: initial — when the process is being created, final — when a process has exited but has not been cleaned up
-
UNIX-based systems call final state the zombie state. It allows for other processes (usually the parent that created the process) to check if the process executed successfully via its return code
-
A child becomes a zombie process if a parent doesn’t wait() on it. A zombie cannot be destroyed via kill signals. It will roam the system until it is reaped
-
A child whose parent dies, voluntarily or involuntarily, is called an orphan process
-
-
Homework takeaway: OS scheduling policies
-
Process switch behavior: when to switch between processes
-
Switch on I/O: switches when current process issues an I/O request
-
Switch on end: only switches when current process is done
-
-
I/O behavior: when a process runs after it issues an I/O
-
I/O run later: switches back to this process when it’s natural to
-
I/O run immediate: switches back to this process right now
-
-
IO_RUN_IMMEDIATE and SWITCH_ON_IO typically pair well together to increase system utilization.
-
-
Chapter 5: Process API
-
Essential interface that any modern OS should have
-
Create
-
Destroy: processes run and exit by themselves when complete. This is only useful for users to forcefully kill runaway process
-
Wait: wait for a process to stop running
-
Miscellaneous Control
- E.g., suspend (stop a process from running for a while), resume (continue it)
-
Status: how long a process has run for, what state it is in…
-
-
In UNIX systems
-
Create: fork() and exec()
-
fork() creates a new child process from a parent process. It is a near-identical copy of the parent. However:
-
It has its own
-
copy of the address space (i.e., private memory)
-
its own registers
-
its own PC, etc.
-
-
-
exec() allows a child to break free from its similarity to its parent and execute an entirely new program
-
Fork bomb: calling fork() repeatedly, filling out the system’s process tables and crashing it
-
-
Destroy: kill() — sends signals to a process
-
For convenience, in most UNIX shells certain keystroke combinations deliver signals to the currently running process
-
<C-c> sends a SIGINT (interrupt/normal termination)
-
<C-z> sends a SIGSTP (stop/pause mid-execution which can be resumed with fg)
-
-
A process can catch various signals with signal()
- It will suspend its normal execution and runs a piece of code in response to the just-delivered signal
-
-
Wait: wait()
-
The shell is just a user program. When a user types a command (name of an executable program, plus any arguments):
-
-
-
The shell finds where the executable is in the file system
-
Calls fork() to create a new child process to run the command
-
Calls some variants of exec() to run the command
-
Waits for the command to complete by calling wait()
-
Child completes, the shell returns from wait() and prints out a prompt, ready for the next command
-
The separation of fork and exec enables features like input/output redirection, pipes, and other cool features,
-
Redirection is easily implemented by closing the stdout and open the target file before calling exec() with the desired command → all output gets directed to the file instead of the screen
-
Same with pipes, only that the output is connected to an in-kernel pipe (i.e., queue) and the input of another process is connected to that same pipe
-
-
The OS has a notion of user
-
Allows multiple users onto the system
-
Ensures users can only control their own processes
-
A superuser can control all processes
-
-
Useful utilities: ps, top, kill, killall
-
Homework takeaway: process tree
-
OSes often create one or a few initial processes to get things going; on Unix, for example, the initial process is called init which spawns other processes as the system runs
-
When a parent process exits before its children, the children reparent to either the init process or the local parent
-
Don’t share address space — Forked processes are given a copy of the address space of their parents. Changes made to variables in the forked process do not affect their counterparts in the parent’s since they are in different memory spaces
-
Share file descriptors — Forked processes share file descriptors previously opened by their parents before forking. Both can write concurrently to the file descriptors
-
-
Chapter 6: Mechanism: Limited Direct Execution
-

- Direct execution means running the program directly on the CPU → performant

-
Problems with this approach
-
Cannot control what the program does while still running it efficiently
-
While it’s running how do we suspend it to switch to another process? (i.e., implementing the time sharing required to virtualize the CPU)
-
-
Restricted operations

-
Introduce a new processor mode: user mode
-
Code that runs in this mode has restricted capabilities
-
E.g., when running in user mode, a process can’t issue I/O request; doing so makes the processor raises an exception, the OS would then likely kill the process
-
-
Contrast is kernel mode
-
OS (or kernel) runs in this mode
-
Can do what it likes (I/O requests, executing restricted instructions, etc.)
-
-
To enable processes in user mode to do privileged operations, virtually all modern hardware provides user programs with system calls
-
Allow the kernel to carefully expose certain functionality to user programs
-
Accessing file system
-
Creating and destroying processes
-
Communicating with other processes
-
Allocating more memory
-
-
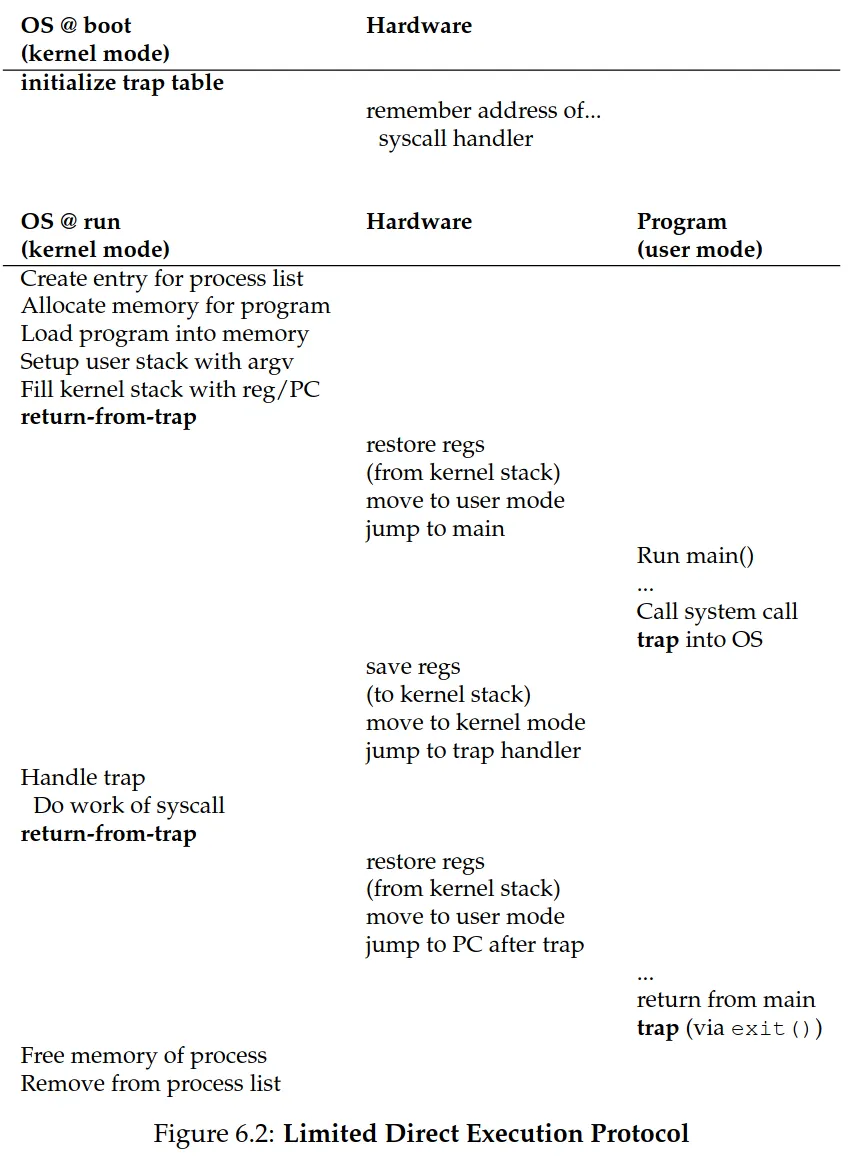
-
Each process has a kernel stack where registers (general purpose registers and the program counter) are saved to and restored from (by the hardware) when transitioning into and out of the kernel
-
PCB vs kernel stack
-
PCB: Stores the high-level process state and metadata
-
Kernel stack: Stores the execution context and temporary data specific to kernel mode
-
Context switch
-
-
Trigger: timer interrupt, system call, hardware interrupt
-
Save current process state: trap handling begins, the current process is already in kernel mode or switches to it, the CPU pushes the current execution context (PC, registers) onto the kernel stack of the running process, the OS copies the current CPU state (execution context) in the kernel stack into the process’ PCB (ensuring essential state is preserved even if kernel stack is overwritten), marks the process as not running, updates other metadata in the PCB
-
Select the next process: the scheduler chooses the next process based on its scheduling policy, the next process’ PCB is retrieved
-
Restore the next process’ state: The OS switches to the kernel stack of the next process, ready for system calls, interrupts, or traps. The OS restores the saved CPU state of the next process from its PCB onto the CPU
-
Returns to user mode
-
Switching between processes
- If a process is running on the CPU, the OS is technically not running and cannot take any actions
-

-
CPU scheduling
-
Cooperative approach
-
The OS trusts the processes to be well-behaved
-
Processes that run for too long are assumed to periodically give up the CPU so OS can do some other task
-
The OS regains control of the CPU by waiting for a system call (user program traps into OS) or an illegal operation (divide by 0, illegal memory accesses also generate a trap to the OS)
-
What if a process never ends (e.g., has an infinite loop) and never makes a system call?
- Can only reboot the machine
-
-
Non-cooperative approach
-
Hardware comes in to help
-
Once a program is running, the OS use hardware mechanisms to ensure the user program does not run forever, namely the timer interrupt
-
A timer device is programmed to raise an interrupt every so many milliseconds. When this happens
-
The currently running process is halted
-
A pre-configured (at boot time) interrupt handler in the OS runs
-
The OS regains control of the CPU and can do what it pleases
-
-
At boot time, the OS
-
informs the hardware of which code to run when the timer interrupt occurs
-
Starts the timer
-
-
The hardware must save enough state of the program to resume it correctly (similar to what it does during a system-call trap)
-
After the OS gains control, the scheduler (part of the OS) decides whether to continue running the previously-running process or switch to a different one based on scheduling policies
-
Sometimes during a timer interrupt or system call, the OS might wish to switch from running the current process to a different one — context switch. The OS
-
Save the general-purpose registers, PC, and the kernel stack pointer of the currently executing process (onto the kernel stack, for example)
-
Restore said registers, PC (a.k.a execution context from its kernel stack), and switch to the kernel stack for the soon-to-be-executing process
-
Resumes execution of the new process when return-from-trap executes
-
-
-
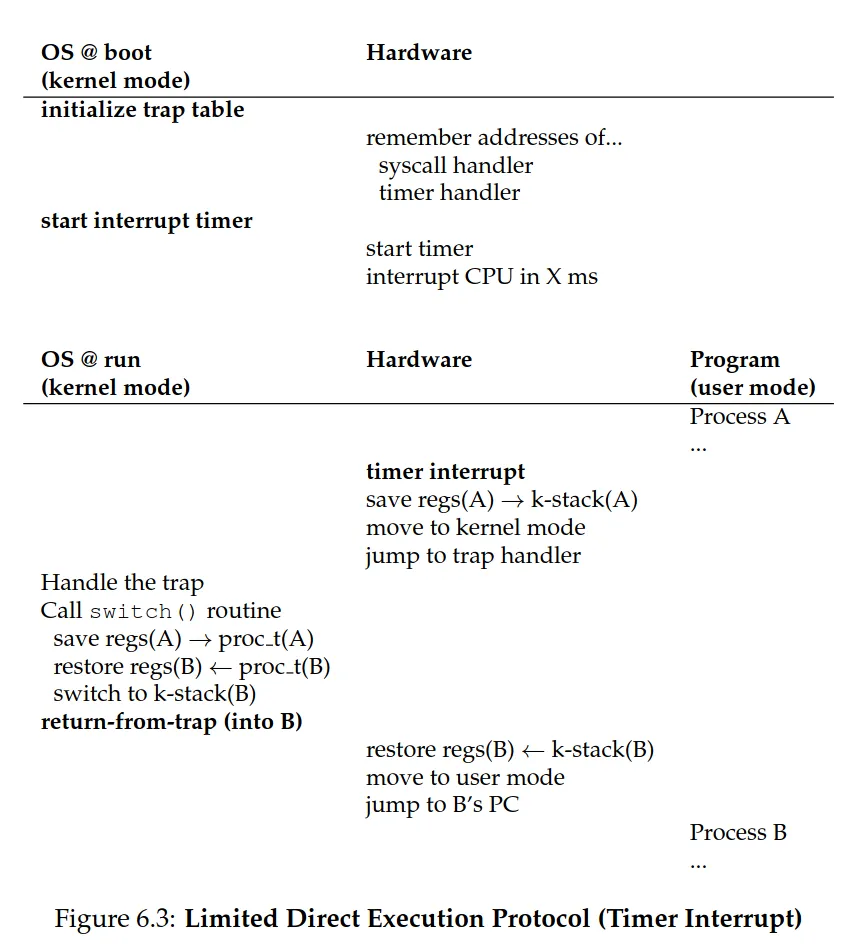
-
The OS handles concurrency during interrupt or trap handling. It might
-
Disable interrupts during interrupt processing
-
Locking schemes to protect concurrent access to internal data structures
-
-
Chapter 7: Scheduling: Introduction
- See lectures notes below
-
Chapter 13: The Abstraction: Address Spaces
-
Every address generated by a user program is a virtual address, the OS provides an illusion to each process that it has its own large and private memory → a form of virtualization
-
Some hardware helps OS turn these into real physical addresses
-
+ Ease of use, + isolation, + protection
-
-
-
Concurrency

-
Meaning: working on many things at once (“concurrently”) in the same program
-
Can think of thread as a function that runs in the same memory space as other functions in the program, with more than one active at a time
-
Chapter 26: Concurrency and Threads
-
The OS supports multi-threaded application with locks and condition variables
-
The OS itself is a concurrent program
-
A new abstraction for a single process — thread
-
A thread is a single point of execution within a program
-
Allows programs to have multiple points of execution (i.e., multiple PCs) instead of one (i.e., a single PC)
-
Can think of threads as separate processes, but share the same address space → access the same data
-
Also can think a sequence of instructions that execute sequentially
-
But each has its own
-
Program counter (PC)
-
Private set of registers for computation
-
Separate stack
-
-
-
Switching from one thread to another requires a context switch — similar to context switch in processes
-
The register state of thread 1 must be saved and the register state of thread 2 restored before running thread 2
-
State is saved to thread control blocks (TCBs) instead of PCBs
-
Two major differences
- No need to switch page table (i.e., the address space remains the same)
-
-
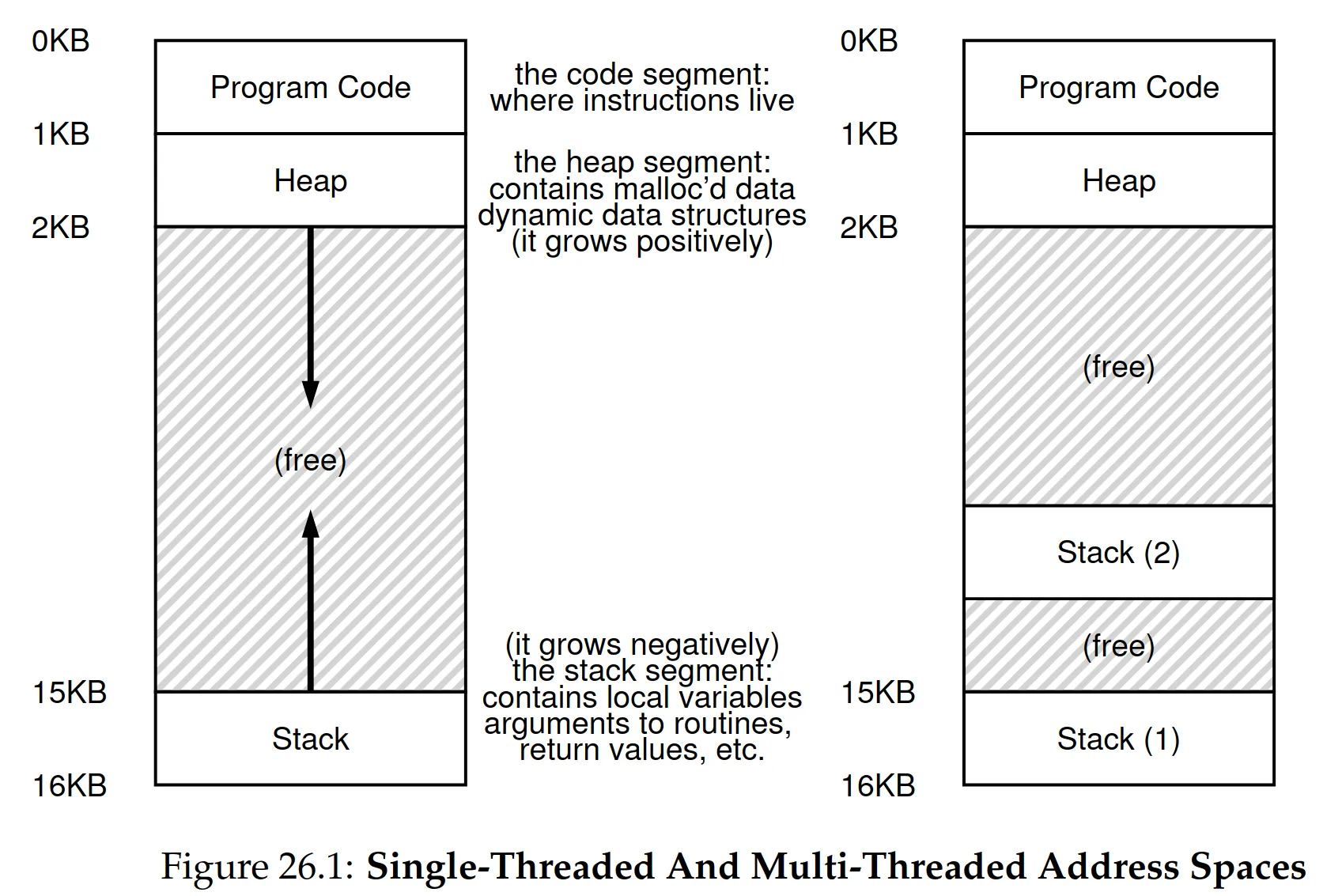
-
Since threads in a process run independently, each will get their own stack
-
Any stack-allocated variables, parameters, return values, and other things are put onto the thread-specific stack (a.k.a thread-local storage)
-
Usually OK if we don’t have very large stacks (recursion-heavy programs)
-
-
Why use threads?
-
Parallelism: transform single-threaded programs into a multi-threaded, multi-CPU program using a thread (a virtual abstraction within a process) per CPU core (hardware unit actually doing the work) for faster performance on modern hardware
-
Avoid blocking I/O: Using threads is a natural way to avoid getting stuck; while one thread in your program waits (i.e., blocked waiting for I/O), the CPU scheduler can switch to other threads (either on different CPU or the same CPU via a context switch) and do other things
- Enables overlap of I/O with other activities within a single program
-
-
Use threads when data sharing is needed, otherwise use processes
-
Think of thread creation a bit like making a function call but the system creates a new thread for the execution of that routine and it runs independently of the caller
- Can return BEFORE the creation call returns to the main thread or even much later, cannot deterministically tell
-
Aside: OS threads vs green-threads (fibers, coroutines, etc.)
-
Green threads (cooperative scheduling):
-
Scheduled by a user-space thread scheduler, not the OS scheduler
-
Share the same kernel thread (The OS only sees one “real” thread) → Platform-independent
-
Examples: JVM (Java Virtual Machine), Goroutines, Erlang processes (lightweight, user-space threads managed by the Erlang VM), gevent (Python), Fibers (Ruby)
-
+ Lightweight (faster context switching because of no kernel involvement), portable, efficient, and predictable, relying on developers to write well-behaved code. Best for controlled, I/O-heavy environments
-
- Cannot handle rogue tasks or leverage multicore CPUs natively (no true parallelism). Blocking calls block all threads (because they shame the same OS thread, has to use async I/O)
-
-
OS threads (preemptive/non-cooperative scheduling)
-
+ Robust, fair, and parallel, as the kernel can interrupt tasks to prevent monopolization
-
- Handles diverse, uncontrolled environments but at higher overhead and complexity.
-
-
Hybrid models (e.g., Tokio, Goroutines): Blend cooperative efficiency with preemptive safeguards to balance performance and robustness
-
JavaScript has a single-thread runtime, but handles async operations with an event loop and non-blocking I/O model
-
-
Critical section
-
piece of code that accesses shared resource (i.e., variable/data structure)
-
must not be concurrently executed by more than one thread
-
-
Race condition/data race: the results of an operation depends on the timing of the code’s execution, indeterminate
-
Mutual exclusion: a property that guarantees that if one thread is executing within the critical section, others will be blocked.
- Implemented through locks and condition variables
-
Atomic operations

- Instead of having a “atomic update” instruction supported by the hardware which is not generic for all cases, we build a general set of synchronization primitives on some useful instructions provided by the hardware

-
Condition variables help make the interaction where one thread must wait for another to complete some action (e.g., I/O) before it continues possible
-
Historical context
-
OS’s were first concurrent programs
-
Techniques developed in OS design apply to multi-threaded applications
-
Critical for managing shared kernel data structures
- Page tables, process lists, file system structures, etc.
-
-
Chapter 27: Thread API
-
pthread_create(): creates a new thread
-
Parameters:
-
Thread identifier
-
Thread attributes
-
Start routine (function to run)
-
Arguments to the routine
-
-
-
pthread_join(): waits for a specific thread to complete
-
Can retrieve return values from threads
-
Ensures thread completion before main thread continues
-
-
Locks (pthread_mutex)
-
Key functions
-
pthread_mutex_lock(): Acquire the lock
-
pthread_mutex_unlock(): Release the lock
-
-
Initialization methods
-
Static initialization with PTHREAD_MUTEX_INITIALIZER
-
Dynamic initialization with pthread_mutex_init(). We usually use this
-
-
-
Condition variables
-
Key functions
-
pthread_cond_wait(): Put thread to sleep
-
Releases the lock it takes in as its second argument so other threads can acquire that lock, enter the critical section that signal the sleeping thread to wake up
-
Before returning after being woken, the pthread_cond_wait() re-acquires the lockc
-
-
pthread_cond_signal()/pthread_cond_broadcast(): Wake up one/all waiting threads on the condition variable, does not anything with any mutexes
-
-
-

-
Best practices
-
Always use with an associated lock
-
Prefer over simple, ad-hoc flag-based signaling
-
The waiting thread has to spin to check condition → Less performant
-
More error-prone
-
-
Use while loops for condition checking
-
-
Best practices in threaded programming
-
Keep interactions simple
-
Minimize thread interactions
-
Always initialize locks and condition variables
-
Check return codes
-
Be careful with argument passing and return values
-
Remember each thread has its own stack
-
Don’t share stack-allocated variables between thread. No easy way to either
-
Use heap or some other globally accessible locale
-
-
Always use condition variables for inter-thread signaling
-
Use the man pages
-
-
Chapter 28: Locks (TODO: have only read summary, need deeper dive)
-
Purpose: Ensure atomic execution of critical sections in concurrent programming.
-
Lock variable (mutex):
-
States: Available (unlocked) or Acquired (locked)
-
lock() and unlock() control access to critical sections
-
-
Lock semantics
-
lock(): Acquires the lock if free; otherwise, waits
-
unlock(): Releases the lock, allowing other threads to acquire it
-
Provides mutual exclusion and scheduling control.
-
-
A more coarse-grained locking strategy with different locks protecting different data structures instead of one big global lock protecting everything increases concurrency
-
Evaluating locks
-
Criteria
-
Correctness: Ensures mutual exclusion
-
Fairness: Prevents starvation (all threads get a fair chance)
-
Performance: Overhead in no contention, single-CPU, and multi-CPU scenarios
-
-
-
Early lock implementations
-
Interrupt disabling
-
Disables interrupts on single-CPU systems.
-
Issues: Privilege abuse risk, fails on multiprocessors, and lost interrupts
-
Limited to OS internal use
-
-
Failed flag-based lock
-
Uses a flag variable with spin-waiting
-
Problem: Race conditions (e.g., both threads see flag=0 and set to 1)
-
-
-
Hardware support for locks
-
Test-and-Set (TAS)
-
Atomic instruction: Returns old value and sets new value
-
Spin lock:
-
-
-
void lock(lock_t *lock) {
while (TestAndSet(&lock->flag, 1) == 1);
}
-
Correct but unfair; spin-waiting wastes CPU cycles
-
Compare-and-Swap (CAS)
-
Atomic check-and-update: if (*ptr == expected) *ptr = new
-
Similar to TAS but more flexible for lock-free algorithms
-
-
Load-Linked (LL) & Store-Conditional (SC)
-
LL reads a value; SC writes only if no intervening update occurred
-
Used to build locks without spinning indefinitely
-
-
Fairness solutions
-
Ticket lock
-
Uses ticket and turn variables
-
Threads acquire locks in FIFO order
-
Avoids starvation
int myturn = FetchAndAdd(&ticket);
-
-
while (turn != myturn);
-
Avoiding spin-waiting
-
Yield
-
Thread yields CPU if lock is held
-
Reduces waste but incurs context-switch overhead
-
-
Queue-based lock (OS support)
-
Solaris: park() (sleep) and unpark(threadID) (wake)
-
Linux: futex_wait() and futex_wake()
-
Guard lock: Protects queue operations with a spin lock
-
Wakeup/Waiting race: Solved via setpark() or atomic guard release
-
-
-
Advanced lock techniques
-
Two-phase locks
-
Phase 1: Spin briefly
-
Phase 2: Sleep if lock not acquired
-
Balances efficiency and CPU conservation (e.g., Linux futex)
-
-
Priority inversion
-
High-priority threads blocked by low-priority ones
-
Solutions: Priority inheritance, uniform priorities
-
-
-
Lock performance considerations
-
Uniprocessor: Spin-wasting is costly (preemption risk)
-
Multiprocessor: Spin-waiting effective if critical sections are short
-
Hybrid approaches: Combine spinning and sleeping (e.g., two-phase locks)
-
-
Real-world implementations
-
Solaris: Uses park()/unpark() with guard locks.
-
Linux futex: Tracks lock state via integer bits; futex_wait() and futex_wake().
-
-
Summary
-
Locks require hardware (atomic instructions) and OS (sleep/wake) support
-
Trade-offs: Correctness vs. fairness vs. performance
-
Modern locks (e.g., futex, ticket lock) optimize for common cases and avoid starvation
-
-
Chapter 29: Lock-based Concurrent Data Structures
-
Adding locks to a data structure to make it usable by threads makes the structure thread-safe
-
TODO: Not finished
-
-
Chapter 30: Condition Variables (TODO: have only read summary, need deeper dive)
-
Locks alone are insufficient for certain synchronization tasks
-
Example: A parent thread waiting for a child thread to complete, simply spinning (busy-waiting) wastes CPU cycles
-
Solution: Use condition variables to allow threads to sleep until a condition is met
-
Condition variable (CV)
- A queue where threads wait for a condition to become true.
-
Operations
-
wait(): Puts the calling thread to sleep, releasing the associated lock
-
signal(): Wakes up one waiting thread
-
broadcast(): Wakes up all waiting threads
-
-
Key point: Always hold the lock when calling wait() or signal()
-

- Key insight: Always use a while loop to check conditions, not an if statement, to handle spurious wakeups

-
CV best practices
- Always use while loops for condition checks to handle spurious wakeups
-
Hold the lock when calling wait() or signal()
-
Use multiple condition variables to avoid waking the wrong threads
-
Broadcast can be used conservatively to ensure all relevant threads are woken
-
Chapter 31: Semaphores (TODO: have only read summary, need deeper dive)
-
A versatile synchronization primitive introduced by Dijkstra
-
can be used as locks, condition variables
-
for ordering
-
-
Operations
-
sem_wait(): Decrements the semaphore value. If the value is negative, the thread waits
-
sem_post(): Increments the semaphore value and wakes up a SINGLE waiting thread if any
-
-
-
-
sem_init(&s, 0, X) initializes the semaphore s to value X
-
Binary semaphores (Locks)
-
A semaphore used as a lock, initialized to 1
-
sem_wait(): Acquires the lock (decrements to 0)
-
sem_post(): Releases the lock (increments back to 1)
-
-
Ordering
-
Semaphores can be used to ensure one thread waits for another to complete
-
Example: Parent thread waits for child thread to finish
-
Initialization: Semaphore initialized to 0
-
Parent: Calls sem_wait() to wait for the child
-
Child: Calls sem_post() to signal completion
-
-
Key insight: The semaphore value should be 0 initially to ensure the parent waits
-
-

-
Reader-writer locks
-
Problem: Allow multiple readers but only one writer at a time
-
Solution
-
Readers: Increment a reader count. The first reader acquires the write lock
-
Writers: Wait for the write lock
-
Starvation: Writers can starve if readers keep acquiring the lock
-
-
Key insight: Use a read-write lock to balance reader and writer access
-
-
-
Thread throttling
-
Problem: Prevent too many threads from executing a resource-intensive task simultaneously
-
Solution: Use a semaphore to limit the number of threads in the critical section
-
Example: Initialize the semaphore to the maximum number of allowed threads
-
-
Implementing semaphores
-
Zemaphore
-
A semaphore implemented using locks and condition variables
-
Zem_wait(): Decrements the value, waits if the value is 0
-
Zem_post(): Increments the value, signals a waiting thread
-
-
Key insight: Semaphores can be built using lower-level primitives like locks and condition variables
-
-
-
Chapter 32: Common Concurrency Problems
- TODO: Not finished
-
Chapter 33: Event-based Concurrency (Advanced)
- TODO: Not finished
-
Persistence

-
We need data to be stored persistently
-
Some hardware stores values in a volatile manner → susceptible to loss
-
Users care about their data
-
-
This requires hardware and software
-
Hardware: I/O device (hard drive/solid-state drives)
-
Software: file system (software in OS that manages the disk)
- Stores user files on system disk reliably and efficiently
-
Assumption: Users want to share information in files → no need virtualization of disks here
-
-
Lecture Notes
- How the OS fits into and communicates with other parts of the machine
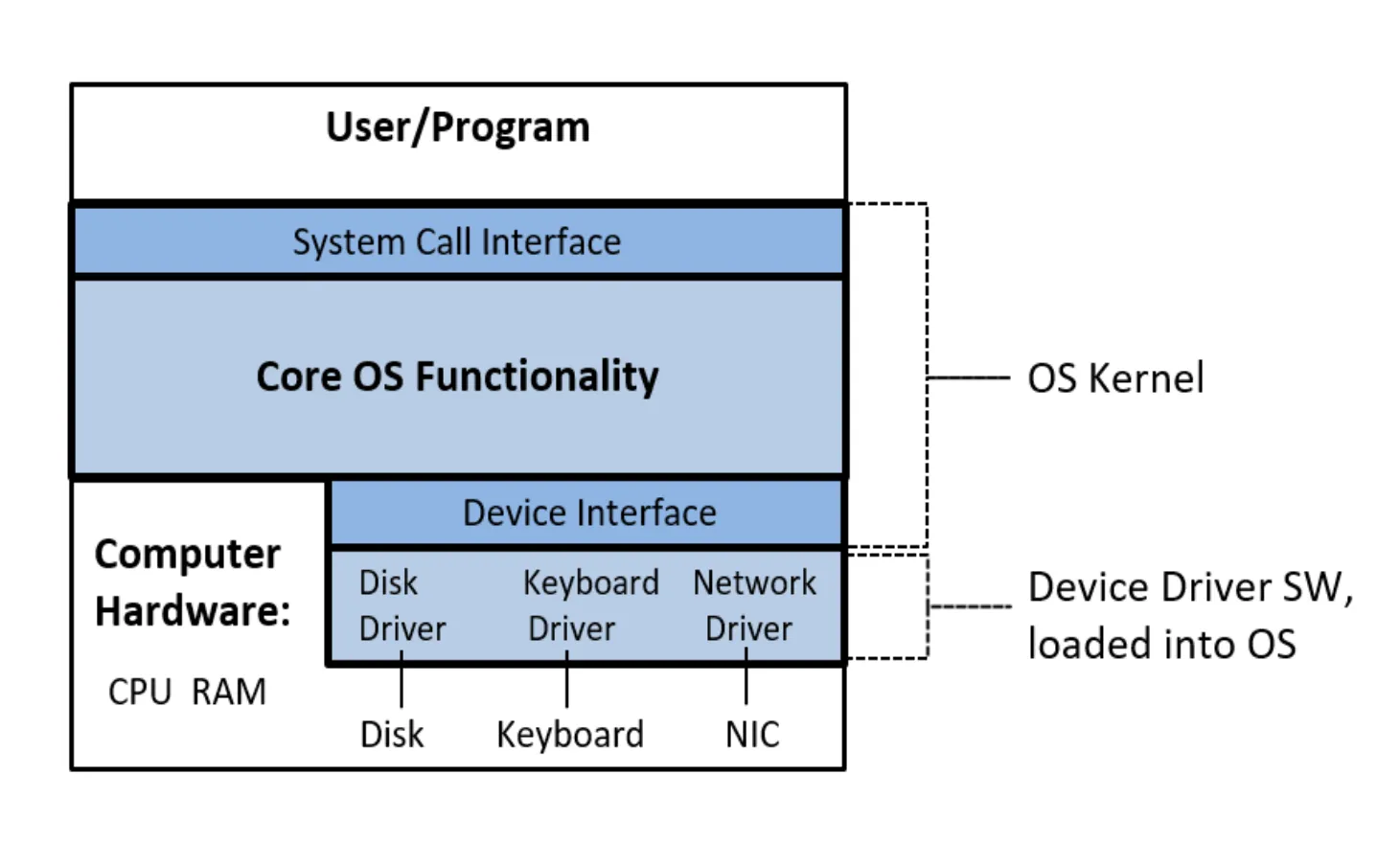
-
After bootloading (i.e., loading the OS from hard drive or secondary memory), the kernel is executed
-
The kernel eventually starts the init process which spawns other processes (through fork() and exec())
-
The kernel provides an API consisting of system calls, divided into families
-
Memory management
-
Time management
-
File system
-
Process system
-
Signal system: rudimentary IPC
-
Socket system: communication with other program on another device through a network
-
And more…
-
-
Libraries vs. syscalls
-
Most standard library functions are built on top of system calls
- E.g., malloc() calls mmap() and brk() — malloc() is a C standard library, while mmap() is a system call
-
System calls provide direct access to the kernel, different OS’s have different system calls
-
Library functions hide the implementation details of how system resources are managed, providing a simpler interface to application programs
-
Library functions tend to be more portable than system calls
-
-
Aside: man 1 <program_name> is for system programs, man 2 <syscall_name> is for system calls, man 3 <lib_func_name> is for library functions, bare man searches from 1 upwards
-
System calls can fail — typically returns a -1 value, should handle error cases
-
Signal system calls
-
Communication between running programs (processes) is called inter-process communication (IPC)
-
OS itself is a program → communicates with other applications via signals
-
Two-way communications
-
OS to application: sends a termination signal
-
Application: installs a signal handler, a function to run when a specific signal is received
- Executed asynchronously, interrupting the process at its current execution point and execution is jumped to the signal handler
-
-
Each process is given a default signal handler for each signal type
-
-
-
Intro to concurrency
-
Process creation is heavy-weight while thread creation is light-weight
-
Kernel is process-aware but not user-thread-aware
-
The library maintain its own thread table in user space
-
These green threads are invisible to the kernel
-
On the other hand, OS threads are fully managed by the kernel
-
Each kernel thread has a thread control block (TCB), typically linked to the process control block (PCB) of the parent process
-
-
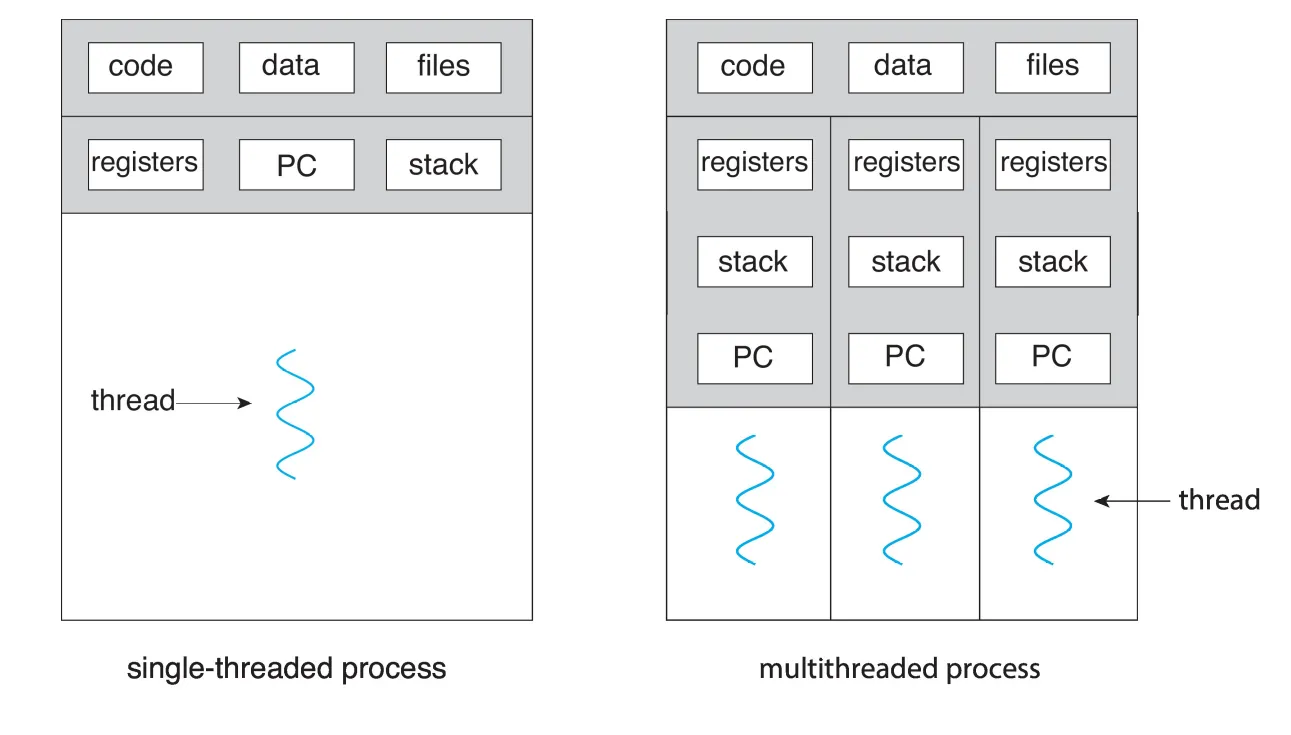


-
Benefits
-
Responsiveness — non-blocking execution, important for UI
-
Resource sharing — share resources of process
-
Economy — cheaper than process creation, context switching between is less expensive
-
Scalability — takes advantage of multicore architectures
-
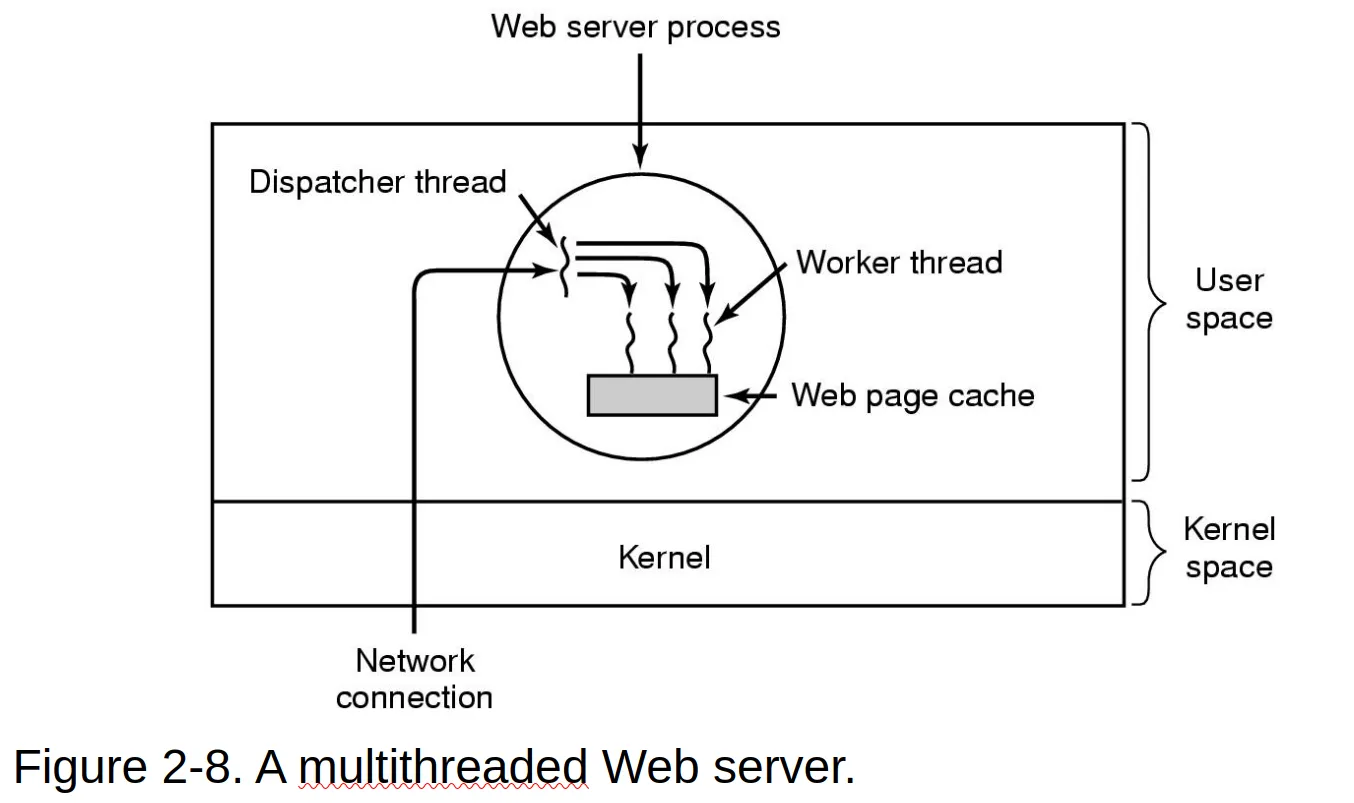

-
Multicore or multiprocessor systems puts pressure on programmers, challenges include:
-
Dividing activities
-
Balance
-
Data splitting
-
Data dependency
-
Testing and debugging
-
-
Parallelism implies a system can perform more than one task simultaneously
-
Concurrency supports more than one task making progress
- Single processor / core, scheduler can provide concurrency but not parallelism
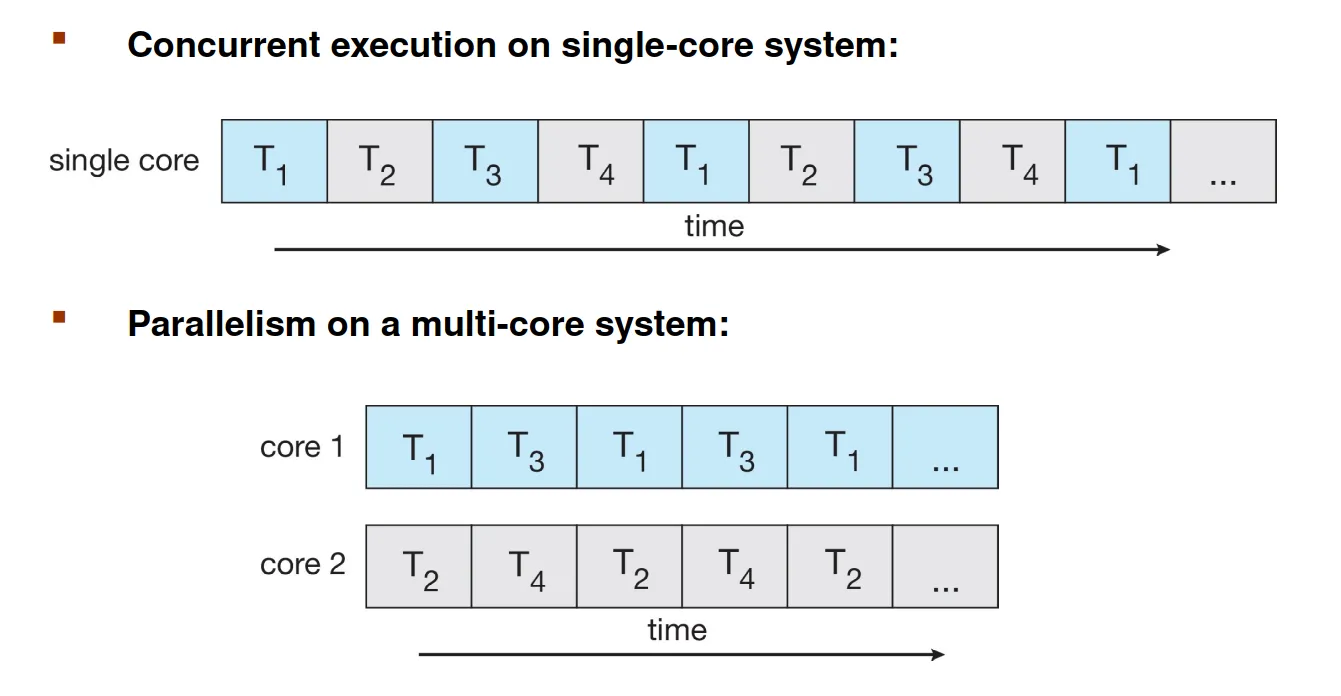
-
Types of parallelism
-
Data parallelism — distributes subsets of data across multiple cores
-
Task parallelism — distributes threads across cores
-
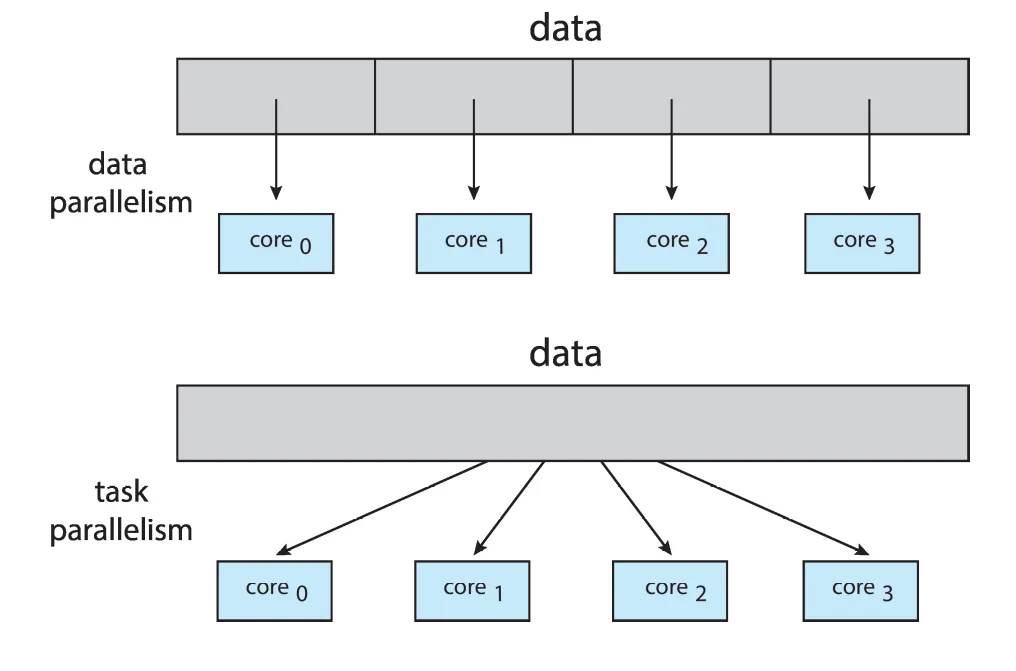
-
Amdahl’s Law
- Serial portion of an application has disproportionate effect on performance gained by adding additional cores

-
Threading models: indicate whether threads are user threads or kernel threads
-
1:1 (kernel threads)
-
N:1 (user threads)
-
M:N (hybrid)
-
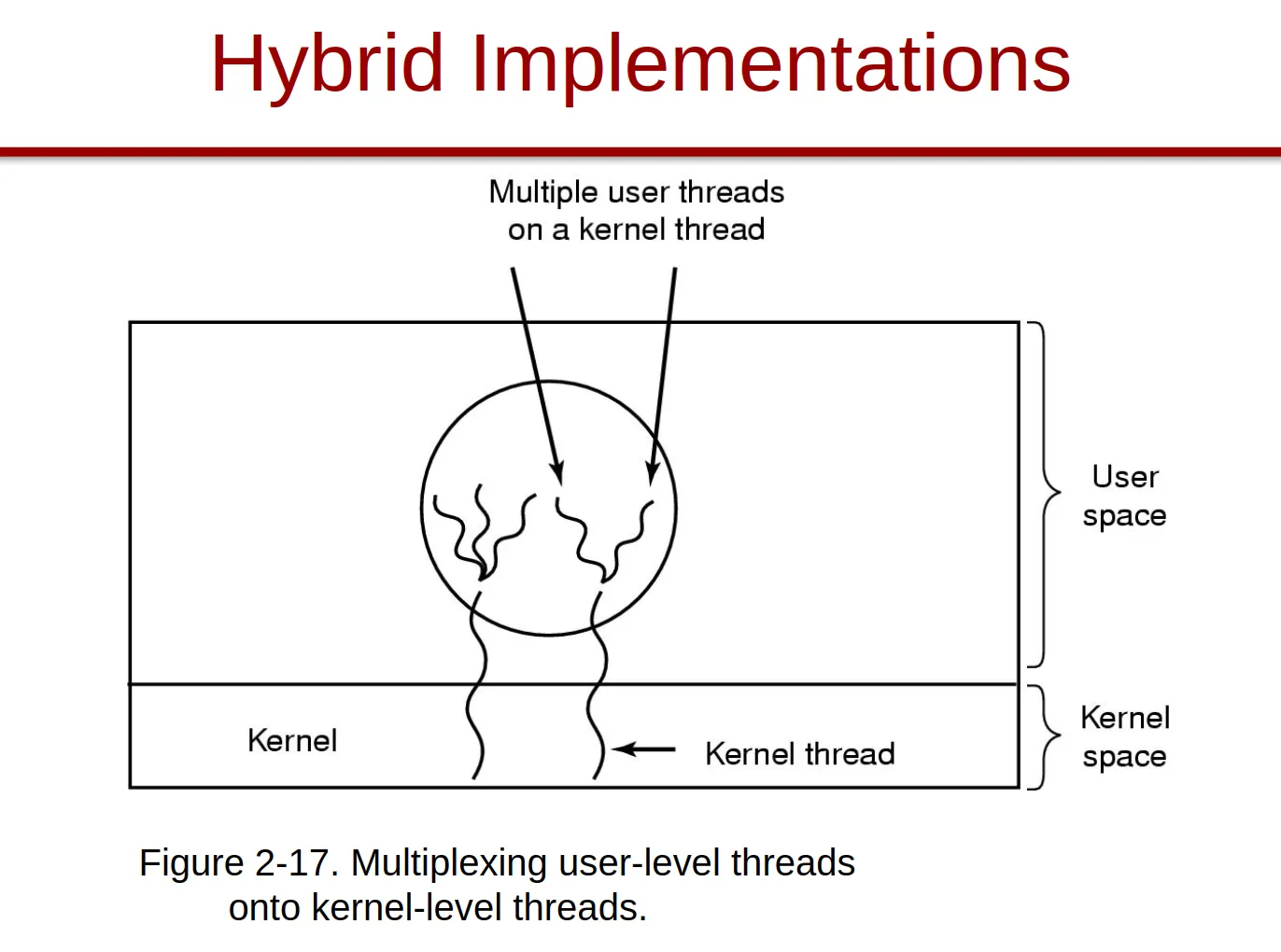
-
User threads and kernel threads
-
User threads — managed by user-level threads library
- POSIX Pthreads, Windows threads, Java threads
-
Kernel threads — managed by the kernel
- Windows, Linux, Mac OSX, iOS, Android
-
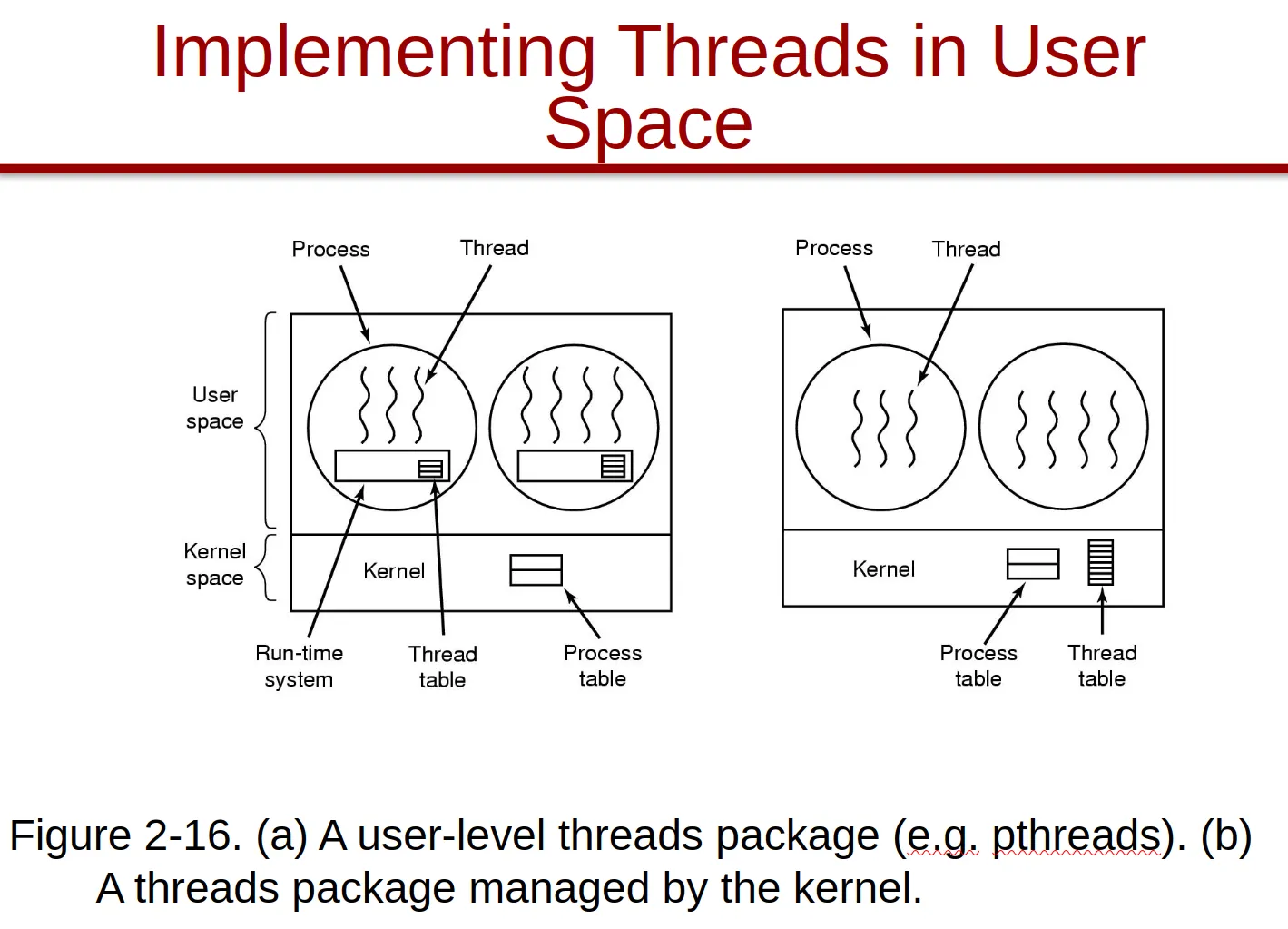
-
POSIX threads (Pthreads)
-
Pthreads themselves are just an abstraction. Depending on the threading model:
-
In an N:1 model, Pthreads are implemented entirely in user space and are user threads.
-
In a 1:1 model, Pthreads are directly mapped to kernel threads and are effectively kernel threads.
-
Refers to the conceptual logical user-level threads interface the programmer interacts with. How it’s implemented depends on the platform (Linux - kernel threads, Windows - Win32 threads)
-
Candidates for threading: routines that are interchangeable, interleaved and/or overlapped in real time
-
-
Pthread API
-
Can be grouped into 4 major groups
-
Thread management: CRUD on threads, CR on threads’ attributes
-
Mutexes: CRUD on mutexes, CU on mutexes’ attributes
-
Condition variables: communications between threads that share a mutex based on programmer specified conditions. CD, wait and signal on specified variable values. CR on condition variable attributes
-
Synchronization: manages R/W locks and barriers
-
-
Terminating threads
-
Returns normally
-
Calls pthread_exit()
-
Canceled by another thread via pthread_cancel()
-
The entire process (not just the thread where this is called) is terminated via exec() or exit()
-
When the main thread (the thread running the main() entrypoint function) finishes execution, the entire process terminates by default, terminating all threads in that process whether t hey are finished or not
-
-
-
Critical regions
-
Conditions required to avoid race condition:
-
No two processes may be simultaneously inside their critical regions.
-
No assumptions may be made about speeds or the number of CPUs
-
No process running outside its critical region may block other processes
-
No process should have to wait forever to enter its critical region
-
-
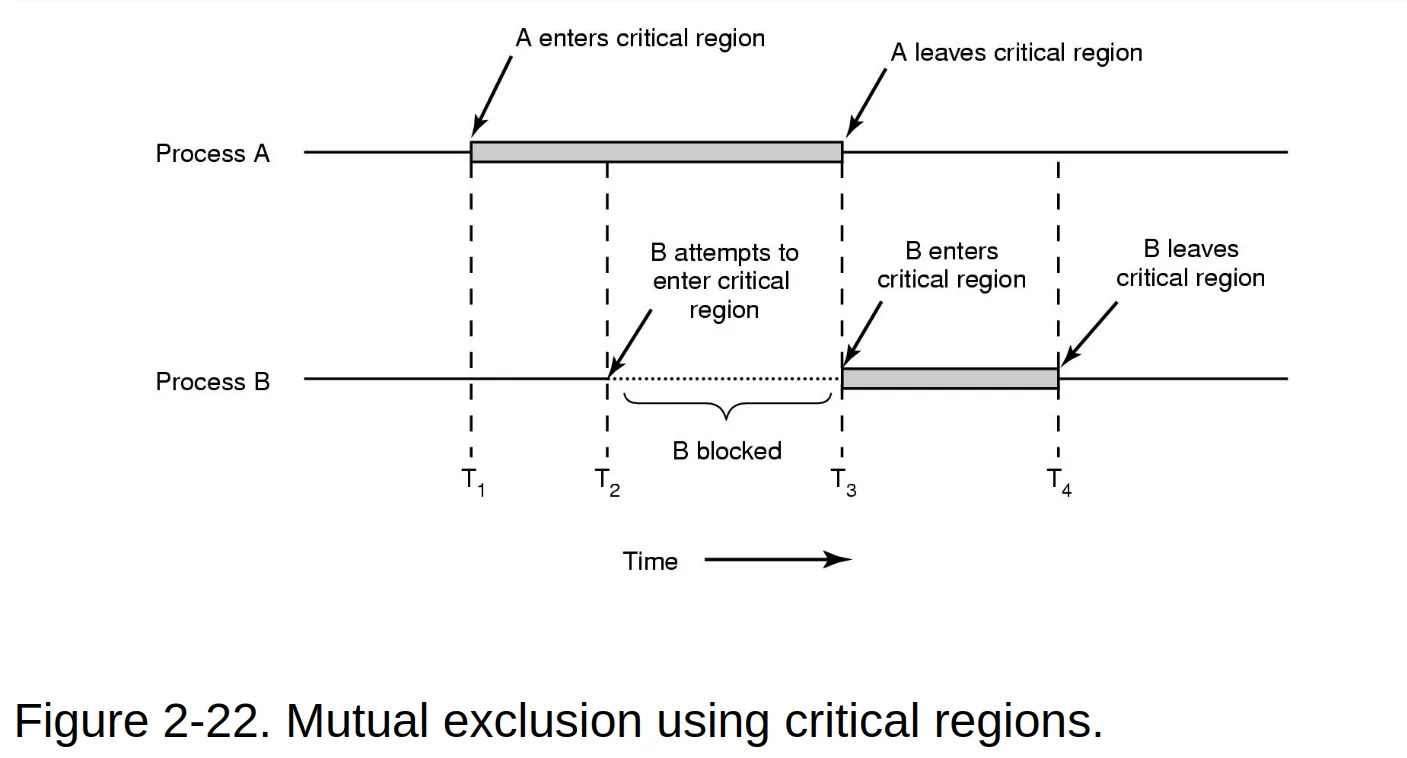
-
Proposals for achieving mutex
-
Disabling interrupts
-
Lock variables
-
Strict alternation
-

- Peterson’s solution

- The TSL instruction

-
Condition variables
-
An explicit queue that threads can put themselves on when some state of execution is not as desired
- Another thread, when it changes said state, can signal on the condition to wake up one or more waiting threads
-
-
Semaphores
-
An object with an integer value that can be manipulated
-
sem_wait(): decrements semaphore by one and returns immediately if value is greater than zero, else waits
- If semaphore is negative, the absolute value of its value is the number of threads that are waiting on this semaphore
-
sem_post(): increments semaphore, if there are one or more threads waiting, wake ONLY ONE
-
-
-
The producer-consumer problem, a classic synchronization problem

-
Deadlocks: resources that wait for each other, bringing system to a halt

-
Tips for multi-threading code
-
Always wait for the conditions before acquiring the lock to avoid holding the lock unnecessarily and avoid deadlocks
-
Release the mutex before signaling for best performance. Sleeping and waking up are expensive operations
-
-
Scheduling algorithms
-
CPU scheduler
-
Selects from the processes in the ready queue
-
Allocates a CPU core to one of them
- Queue may be ordered in various ways/metrics
-
-
Scheduling metrics
- Simplicity, job latency, interactive latency, throughput, utilization, determinism, fairness, etc.
-
Pre-emptive vs. non-preemptive
-
Scheduling decisions may take place when a process
-
Running → Wait (non-premptive)
-
Running → Ready (pre-emptive)
-
Wait → Ready (pre-emptive)
-
Terminated (non-preemptive)
-
-
Non-premptive scheduling
- Once allocated a CPU core, the process keeps the core until it terminates or switches to waiting (1 & 4)
-
Virtually all modern OSes use pre—emptive scheduling algorithms
-
-
Scheduling — process behavior
-
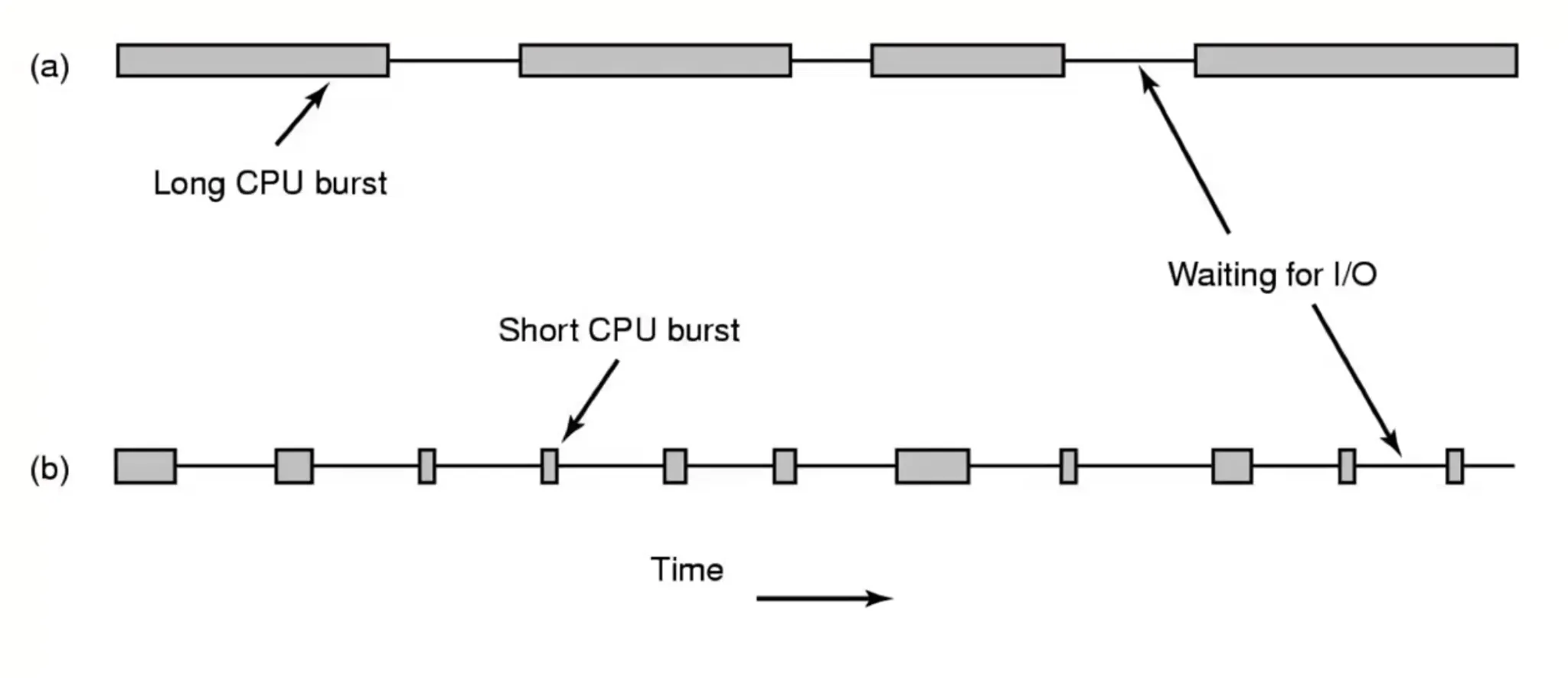
-
Categories
-
Batch: optimize for throughput, turnaround time, CPU utilization
-
First-come first-served
-
Suffers from the convoy effect
-
Short tasks stuck behind long tasks
-
Increases average waiting time
-
-
-
Shortest job first
- Can have non-premptive and pre-emptive versions
-
Shortest remaining time next
-
-
Interactive: optimize for response time, proportionality
-
Round-robin scheduling
-
Priority scheduling
-
Multiple queues
-
Shortest process next
-
Guaranteed scheduling
-
Lottery scheduling
-
Tickets in relationship to priority
-
Cooperative jobs can share tickets
-
-
Fair-share sheduling
-
-
Real-time: optimize for meeting deadlines, predictability
-
All systems: optimize for fairness, policy enforcement, and balance/utilization
-
-
Thread scheduling
-
When kernel-level threads are used, CPU can interleave execution of threads of process A with threads of process B; however, this is not possible in user-level threads since kernel isn’t aware of the threads
-
Many-to-one and many-to-many (user-level-to-kernel-level thread mapping) models
-
Thread libraries manage the scheduling of user-level threads to run on light-weight process (LWP, Linux’s “threads”)
-
Known as process-contention scope (PCS) since scheduling competition is within the process
-
Typically done via priority set by the programmer
-
-
Kernel threads are scheduled onto available CPU cores is system-contention scope (SCS)
-
-
Pthread scheduling API
-
Allows specifying either PCS or SCS during thread creation
-
PTHREAD_SCOPE_PROCESS & PTHREAD_SCOPE_SYSTEM
-
OS-limited — Linux & macOS only SCS
-
-
-
Memory management
-
CPU can only access main memory and cache/registers
- If something is not in memory/on disk, it has to be loaded into memory
-
The memory unit only sees a stream of
-
Addresses + read requests
-
Addresses + data and write requests
-
-
Register access is fast, = 1 CPU cycle (or less)
-
Main memory access is slower, takes many cycles, causing a stall
-
Cache sits between the main memory and CPU registers
-
Protection of memory required to ensure correct operation
-
Protection
-
Each process can only access addresses in its address space
-
Does this by the base and limit registers → defines the logical address space of the process
-
-
Memory management unit
-
Base register can also be called relocation register
-
The value in the relocation register is added to every address generated by a user process at the time it is accessed
-
-
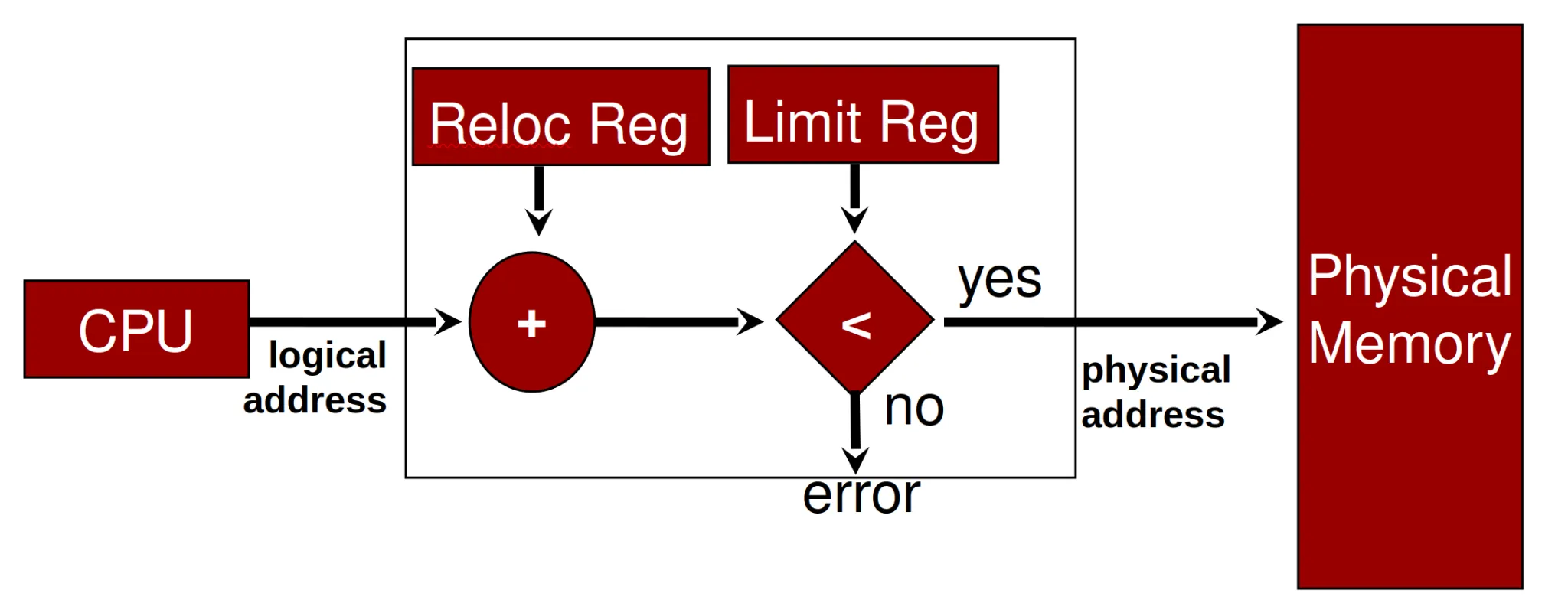
-
Strategies
-
Fixed partition
-
Divides memory into fixed-size partitions
-
Degree of multiprogramming (many programs concurrently) = # of partitions
-
+ Easy
-
- Process size is limited to partition
-
- Internal fragmentation — unused memory within a partition unavailable to other processes
-
-
Variable partition
-
Dynamically divides memory based on processes’ needs
-
+ Better memory utilization
-
- More complex
-
- External fragmentation — a lot of holes, memory outside of any partition that’s too small to fit any process
-
-
Internal and external fragmentation apply to all forms of spatial resource allocation
-
RAM, disk, virtual memory
-
File systems
-
-
“No free lunch”
-
Fixed size partition, no external, more internal
-
Variable size partition, more external, no internal
-
-
-
Mechanisms — how the internal memory system maintains info about free and allocated memory
-
Bit-map — 1 bit per allocation unit
-
+ Can see big picture
-
+ Easy to search with bitwise operations
-
+ Holes automatically coalesce
-
- No association between blocks and processes that owns them
-
-
Linked lists — free list updated and coalesced when not allocated to a process
-
+ Direct associated between block and process owning it
-
- Cannot see big picture
-
- Searching is expensive
-
- Coalescing adjacent blocks is sort (basically sorting a linked list)
-
-
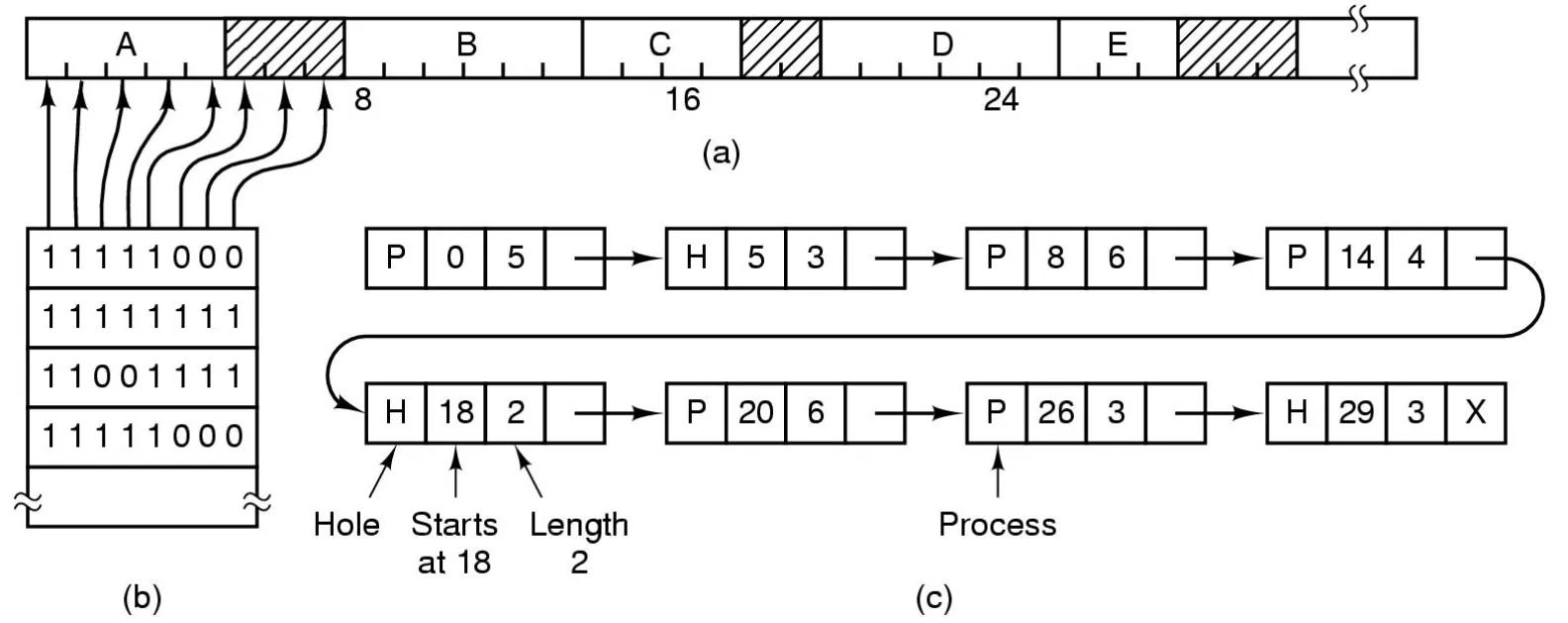
-
Compactions
-
Move things around to consolidate holes
-
Expensive in OS time
-
-
Policies
-
First Fit: scan free list and allocate first hole that is large enough — fast
-
Next Fit: start search from end of last allocation
-
Best Fit: find smallest hole that is adequate — slow and lots of fragmentation
-
Worst Fit: find largest hole
-
Simulation shows First Fit usually the best
-
-
Swapping and scheduling
-
Move process from memory to disk (swap space)
-
Swap space is a portion of the disk reserved as a “parking lot” for blocked processes
-
When process is blocked or suspended
-
-
Move process from swap space to big enough partition
-
When process is ready
-
Load base and limit registers in CPU
-
-
Memory manager unit (MMU) and process scheduler work together
-
Scheduler keeps track of all processes
-
MM keeps track of memory owned by those processes
-
Scheduler marks processes as swappable and notifies MM to swap in processes
-
Scheduler policy must account for swapping overhead
-
MM policy must account for need to have memory space ready for processes
-
-
Segmentation
-
Memory management technique where memory is divided into variable-sized segments, each representing a logical unit (e.g., stack, heap, code, data)
-
Additional MM hardware support: each segment has a base and a limit register, defined in a segment table
-
Advantages
-
+ Code segment doesn’t need to be swapped out and may be shared
-
+ Stack and heap can grow — may require segment swap
-
-
Disadvantage
- External fragmentation
-
Logical address of a segment: <segment-number, offset>
-
Segment number identifies the segment in the segment table
-
Offset is the offset in that segment
-
-
Each process has a segment table
-
Maps segment numbers to 2D physical addresses; each entry has
-
Base: starting physical address where the segment resides in memory
-
Limit: length of segment (bounds checking)
-
-
-
Segment lookup
-
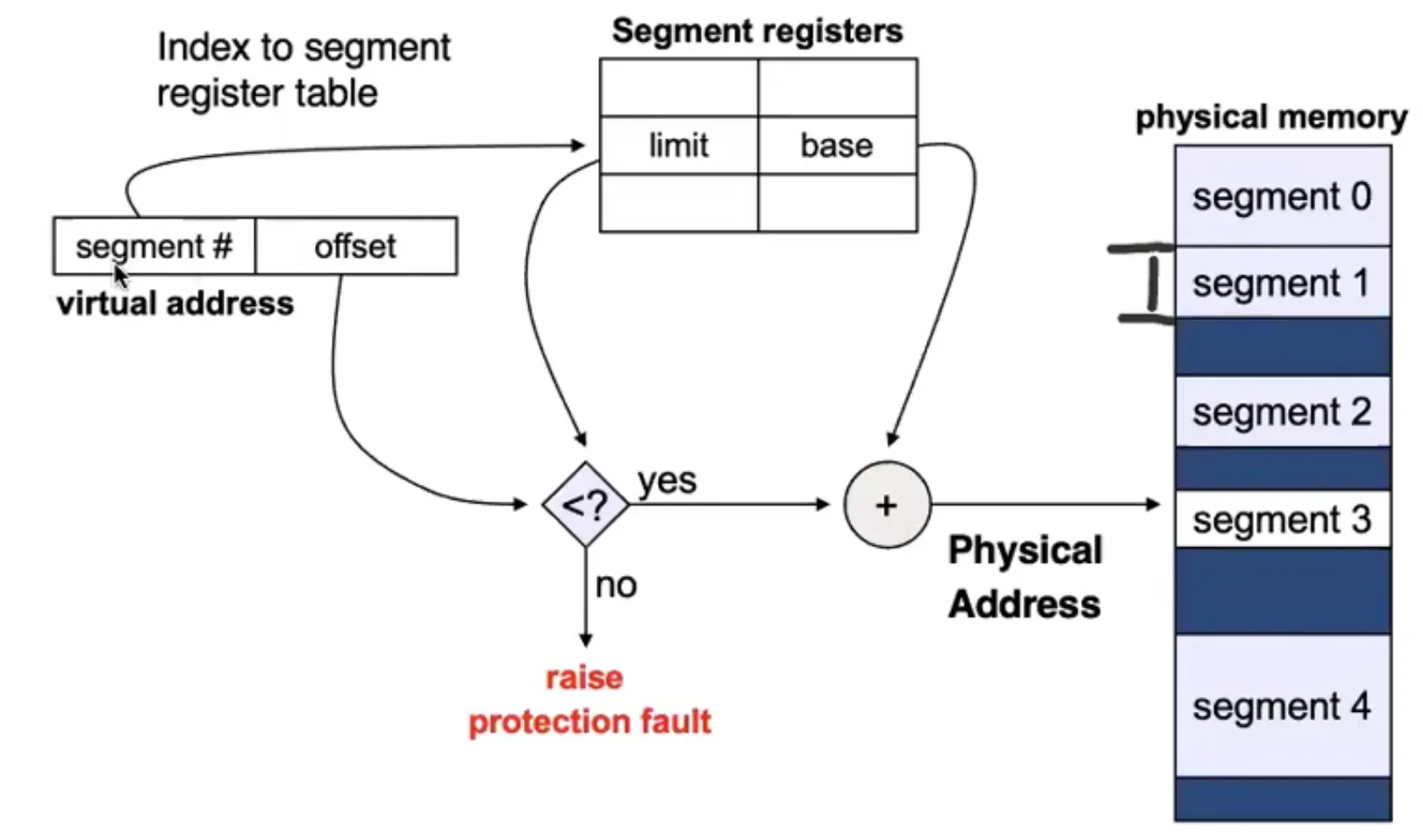
-
Segmentation fault (segfault)
- When a program tries to access a memory location that it is not allowed to access (e.g., outside its segment limit or an invalid address)
-
Protection
-
With each pair of segment registers, include
-
validation_bit = 0 → illegal segment
-
read/write/execute privileges
-
-
Protection bits associated with segments; code sharing occurs at segment level
-
Since segments vary in length, memory allocation is a dynamic storage-allocation problem
- With all the problems of fragmentation!
-
-
Compaction
-
Technique used to reduce external fragmentation in memory
-
Move all allocated memory blocks to one end of memory, freeing up a large contiguous block of free space
-
Expensive in terms of time and processing — requires updating all references to moved memory locations
-
Commonly used in systems with variable-sized memory allocation (e.g., segmentation).
-
-
Paging
-
A new MM approach that solves segmentation’s issues but introduces new ones
-
Physical address space can be non-contiguous; process is allocated physical memory whenever the latter is available
-
Avoid external fragmentation
-
Avoid problems of varying sized memory chunks
-
-
Divide physical memory into fixed-sized blocks called frames
- Size is power of 2, between 512 bytes and 16 Mbytes
-
Divide logical memory into blocks of same size called pages
-
Keep track of all free frames
-
Run a program of size N pages: Find N free frames and load
-
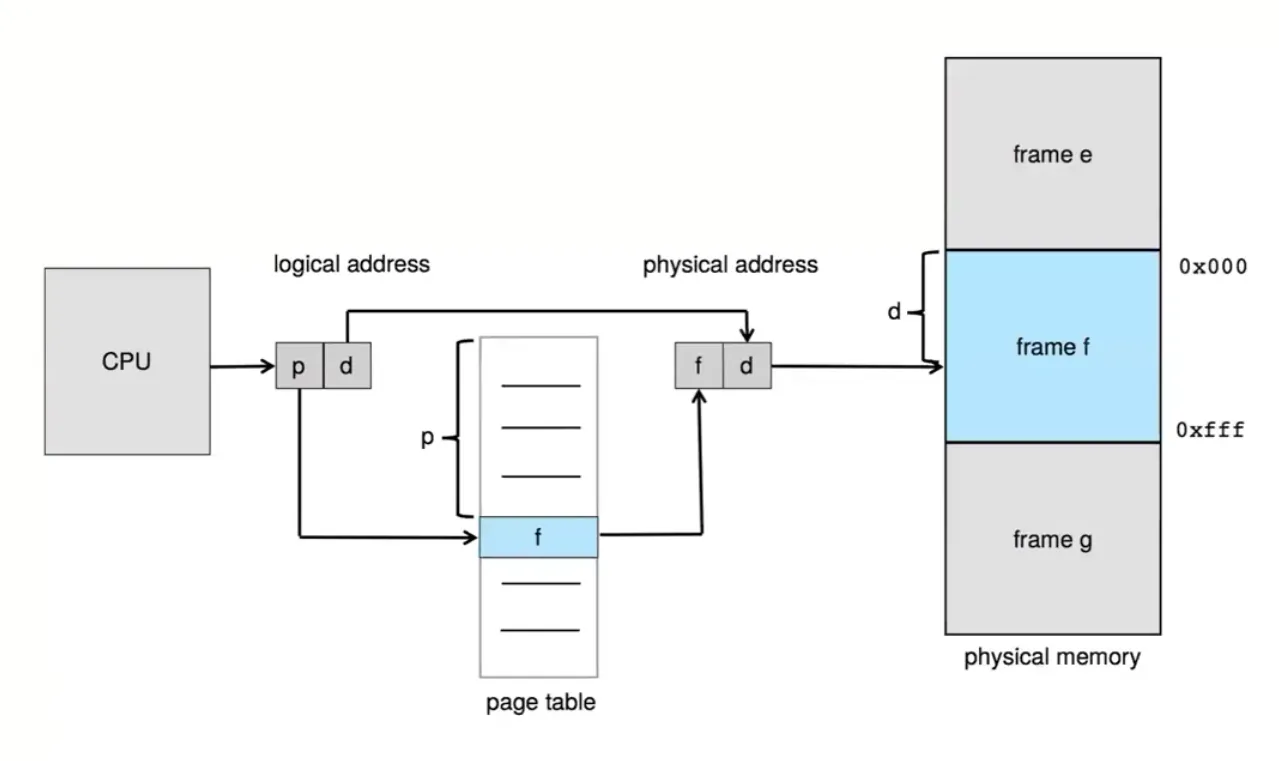
Set up a page table to translate logical → physical addresses
-
Backing store likewise split into pages
- Reserved area on disk
-
Still have internal fragmentation, but not as severe
-
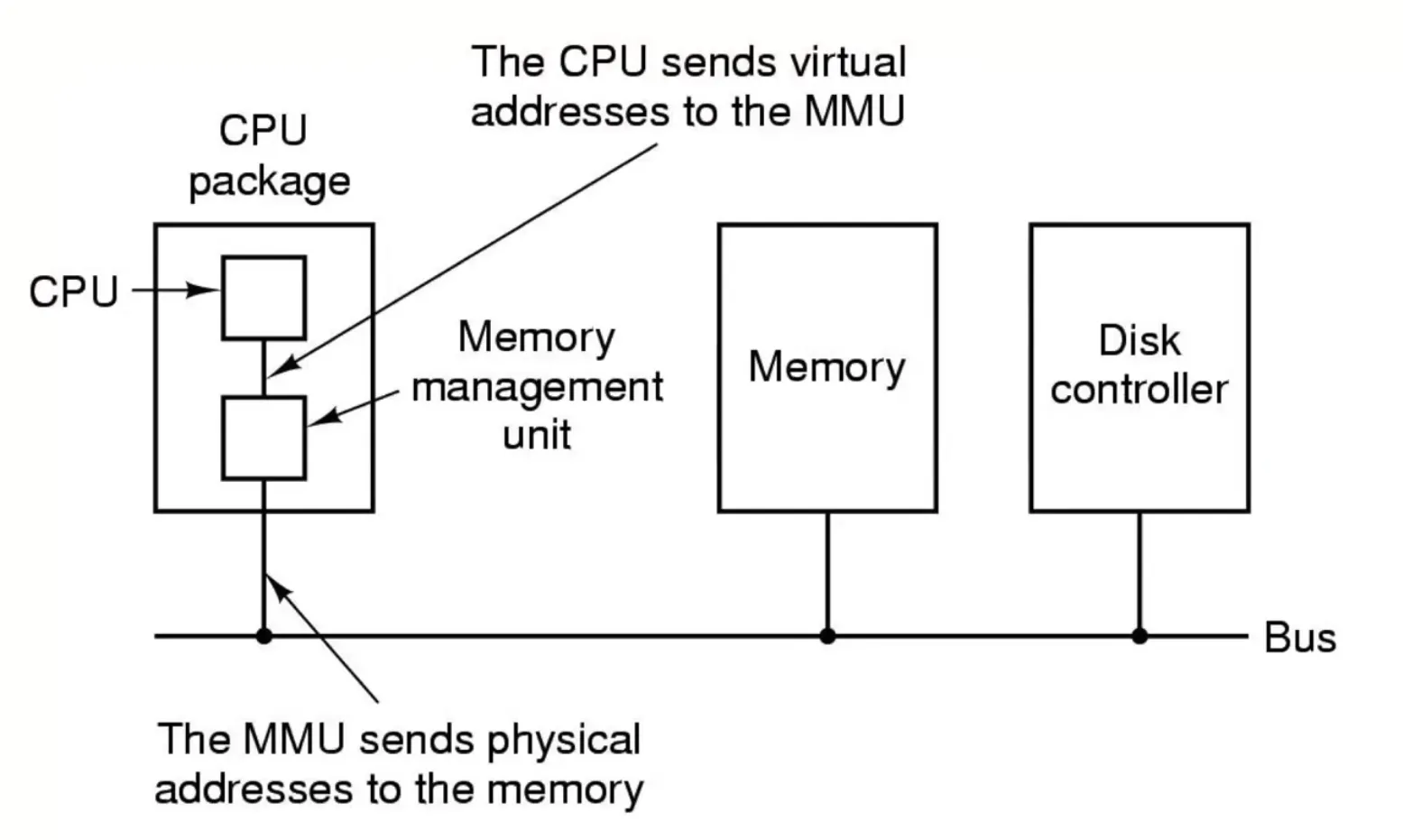
-
Provides sufficient MMU hardware to allow page units to be scattered across memory
-
Make it possible to leave infrequently used parts of virtual address space out of physical memory
-
Address translation scheme
-
Page number (p)
-
Page offset (d)
-
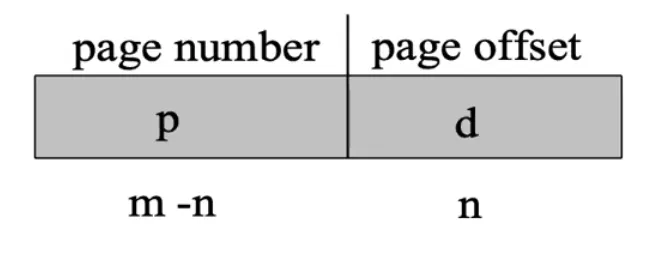
- For given logical address space 2^m and page size 2^n
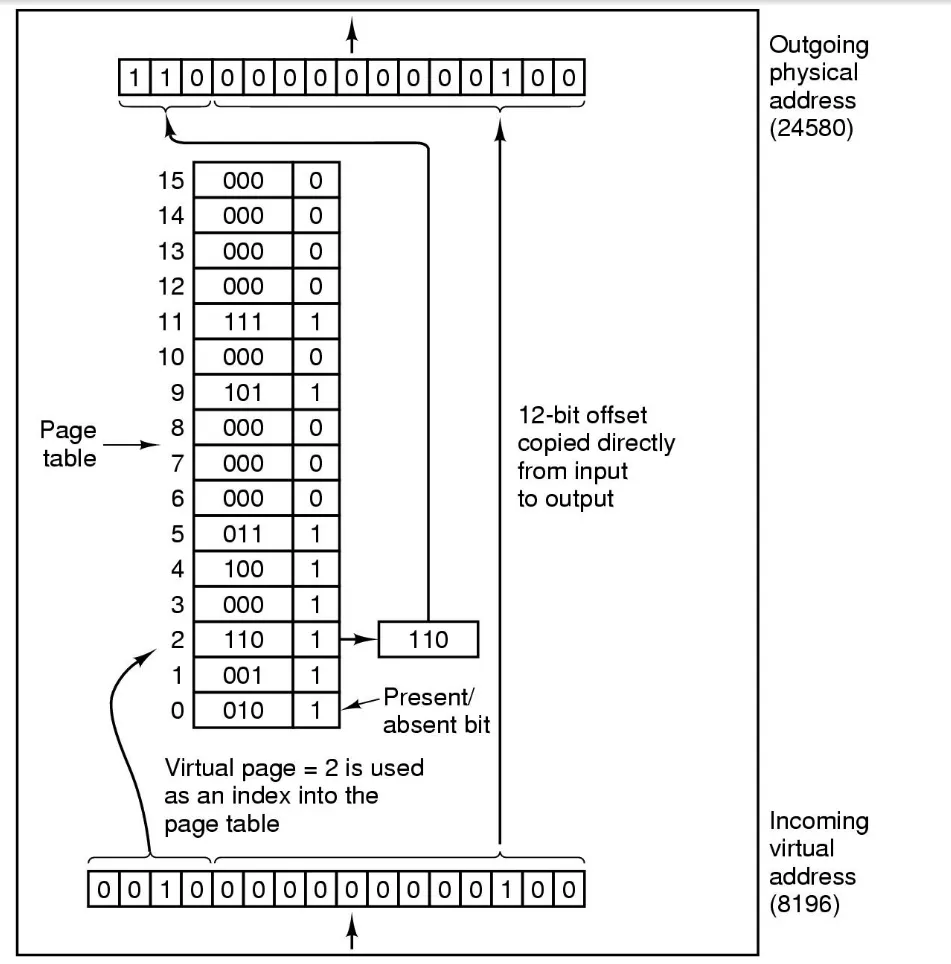
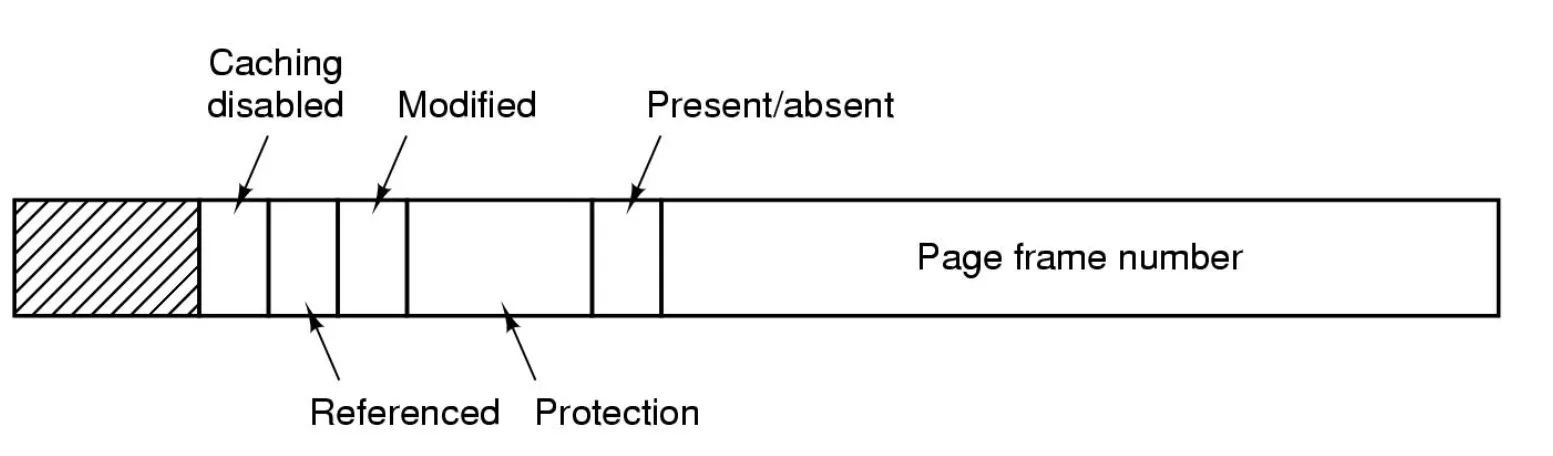
- Page table entry anatomy
-
Calculating internal fragmentation
-
Page size = 2,048 bytes
-
Process size = 72,766 bytes
-
35 pages + 1,086 bytes
-
Internal fragmentation of 2,048 - 1,086 = 962 bytes
-
Worst case fragmentation = 1 frame — 1 byte
-
On average fragmentation = 1 / 2 frame size
-
So small frame sizes desirable?
-
But each page table entry takes memory to track
-
Page sizes growing over time
- Solaris supports two page sizes — 8 KB and 4 MB
-
-
Implementation
-
Page table is kept in main memory
-
Page-table base register (PTBR) points to the page table
-
Page-table length register (PTLR) indicates size of the page table
-
-
In this scheme every data/instruction access requires two memory accesses
- One for the page table and one for the data / instruction
-
The two-memory access problem can be solved by the use of a special fast-lookup hardware cache called translation look-aside buffers (TLBs) (also called associative memory)
-
-
Advantages
-
+ Easy to allocate physical memory
- pick (almost) any free frame
-
+ No external fragmentation
- All frames are equal
-
+ Minimal internal fragmentation
- Bounded by page/frame size
-
+ Easy to swap out pages (called pageout)
-
+ Processes can run with not all pages swapped in
-
-
Page fault
-
Trap when virtual address has valid bit=0 in page table
-
If page exists on disk
-
Suspend process
-
Possibly evict another page (and update its page table entry)
-
Swap in desired page, resume execution
-
Restart instruction — the OS telling the process that hey your previous instruction triggered a page fault, I have set the stage for it not to page fault again. you can try the previous instruction again
-
-
If page does not exist on disk
-
Return program error
-
Conjure up a new page and resume execution
- Example: growing the stack
-
-
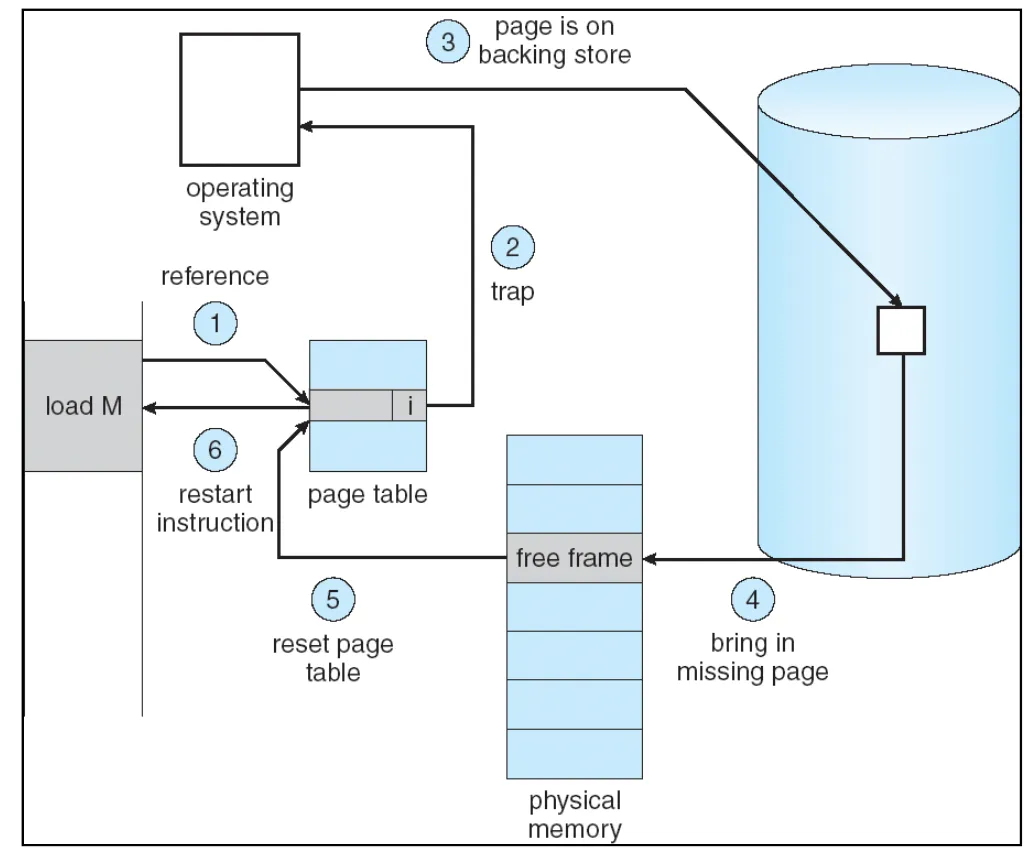
-
Backing storage
-
A place on external storage medium where copies of virtual pages are kept
-
For pages that are not currently on RAM
-
Usually a hard disk (locally or on a server)
-
-
Allow the OS to free up RAM by moving inactive or less frequently used pages to disk
-
Place from which contents of pages are read after page faults
-
Place where contents of pages are written if page frames need to be re-allocated
-
-
Protection bit
-
A process may have valid pages that are
-
not writable
-
execute only
-
-
Setting protection bits in PTE to prohibit certain actions is a legitimate way of detecting the first action to that page
-
Definition of Page Fault is extended to include:
-
Trap when valid=0 in PTE
-
Access inconsistent with protection setting
-
-
-
Recurring themes in paging
-
Temporal Locality: locations referenced recently tend to be referenced again soon
-
Spatial Locality: locations near recent references tend to be referenced soon
-
-
Definitions
-
Working set: The set of pages that a process needs to run without frequent page faults
-
Thrashing: Excessive page faulting due to insufficient frames to support working set
-
-
Issues
-
Page tables can be huge
-
32bit: 4KB pages x 4-byte PTEs = 4MB (per process)
- Stored in main memory
-
64bit
-
Solution: Multi-level page table
-
-
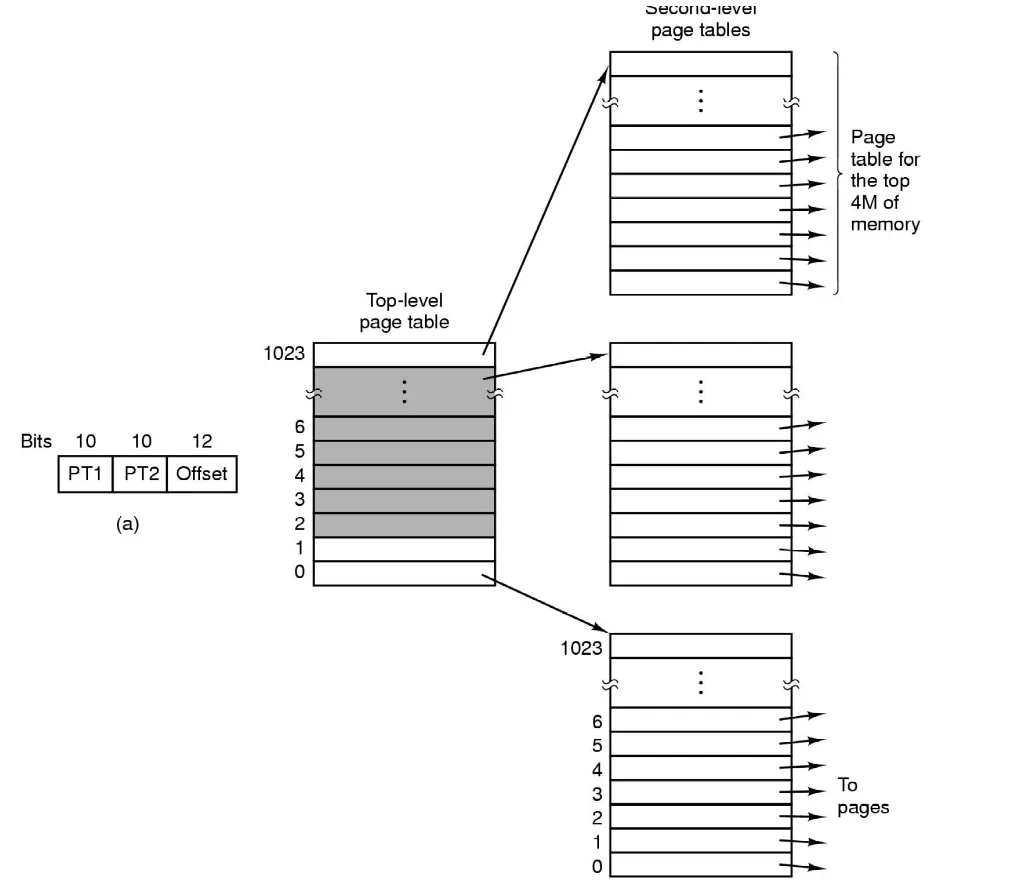
-
Performance is important
-
Virtual → physical requires multiple memory operations
-
Fast hardware support needed to reduce memory accesses and validation checks
-
Translation lookaside buffer/associative memory/dynamic address translation
- Provides quick access (1 machine cycle) to frequently accessed PTEs through caching
-
-
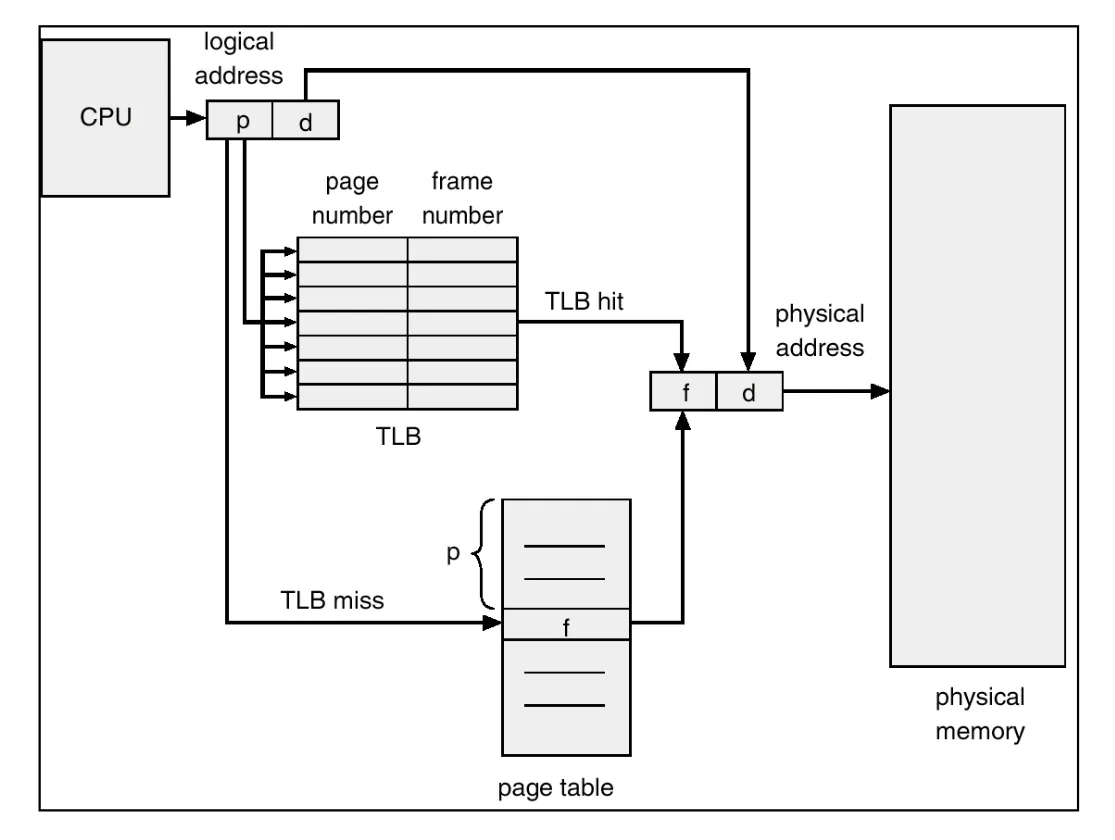
- Typical machine architecture
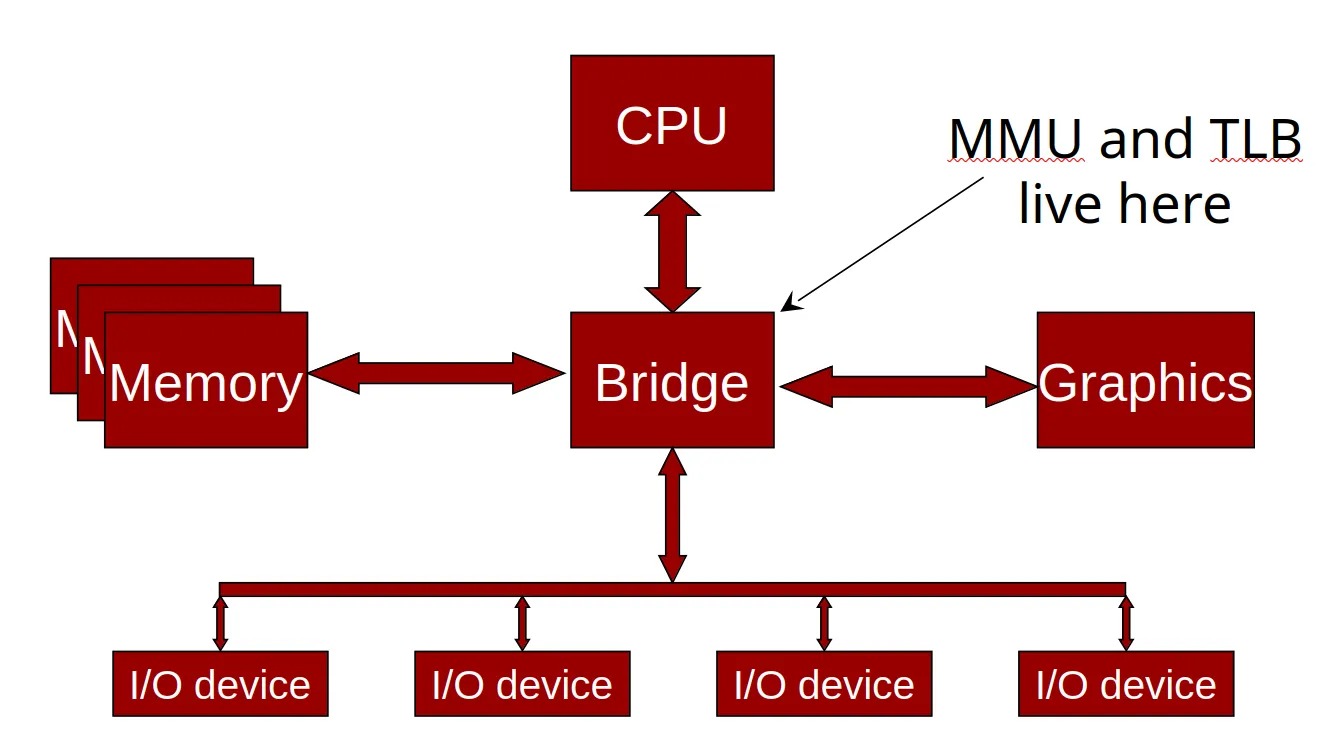
-
Caching
-
Virtual memory
-
Separation of user logical memory from physical memory
-
Only part of the program needs to be in memory for execution
-
Logical address space can therefore be much larger than physical address space
-
Allows address spaces to be shared by several processes
-
Allows for more efficient process creation
- Pages can be shared during fork() with copy-on-write
-
More programs running concurrently
-
Less I/O needed to load or swap processes
-
-
Can be implemented via:
-
Demand paging
-
Demand segmentation
-
-
-
Demand paging
-
Demand paging is a specific implementation of the paging memory management technique where pages are loaded into memory when they are actually accessed by the program
-
Only required pages are brought in, not the entire program at once
-
“Lazy loading” approach to paging
-
Hardware support
-
Page table with valid / invalid bit
-
Secondary memory (swap device with swap space)
-
Instruction restart
-
-
Free-frame list
-
A pool of free frames in RAM/main memory to satisfy page-faulted requests where the desired frame must be brought into main memory from secondary storage by the OS
-
Zero-fill-on-demand
- A technique to zero out the content of the frames before being allocated
-
On startup, all available memory is placed on the free-frame list
-
-
Performance of demand paging: Effective access time (EAT)
-
Three major activities
-
Service the interrupt — careful coding means just several hundred instructions needed
- ~ 0.1—10 sec
-
Read the page — lots of time
- ~ 8-20 milliseconds!
-
Restart the process — again just a small amount of time
- ~ 0.1—10—100 sec
-
-
Page Fault Rate 0 <= p <= 1
-
if p = 0 no page faults
-
if p = 1, every reference is a fault
-
-
Effective Access Time (EAT)
- EAT = (1 — p) x memory access + p (page fault overhead + swap page out + swap page in)
-
-
-
Copy-on-write
-
Allows both parent and child processes to initially share the same pages in memory
-
If either process modifies a shared page, only then is the page copied
-
COW allows more efficient process creation as only modified pages are copied
-
In general, free pages are allocated from a pool of zero-fill-on-demand pages
-
Pool should always have free frames for fast demand page execution
-
Don’t want to have to free a frame as well as other processing on page fault
-
Why zero-out a page before allocating it?
-
-
-
vfork() variation on fork() system call has parent suspend and child using copy-on-write address space of parent
-
Designed to have child call exec()
-
Very efficient
-
-
-
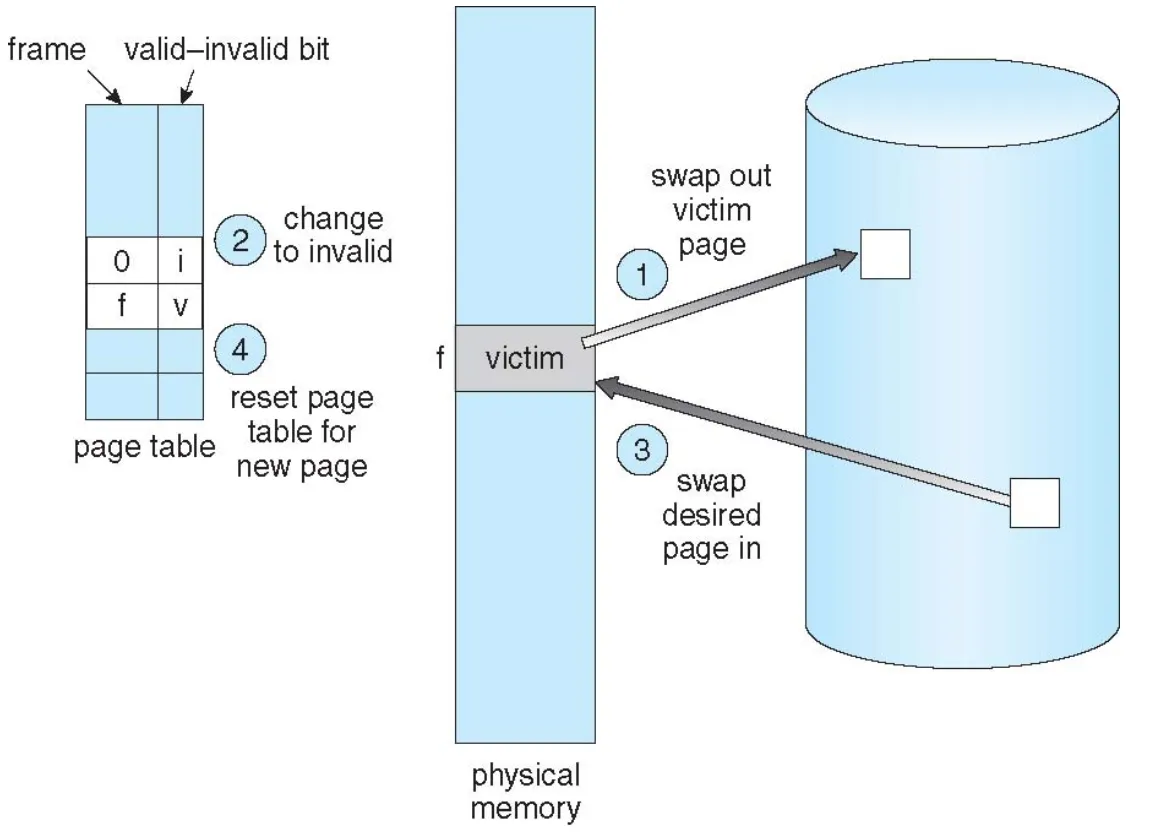
Page replacement algorithms
-
Prevent over-allocation of memory by modifying page-fault service routine to include page replacement
-
Use modify (dirty) bit to reduce overhead of page transfers — only modified pages are written to disk
- whether the page has been modified or not
-
Want lowest page-fault rate on both first access and re-access
-
Basic algorithm
-
-
-
Find the location of the desired page on disk
-
Find a free frame:
a. If there is a free frame, use it
b. If there is no free frame, use a page replacement algorithm to select a victim frame
c. Write victim frame to disk if dirty
-
Bring the desired page into the (newly) free frame; update the page and frame tables
-
Continue the process by restarting the instruction that caused the trap
- Note now potentially 2 page transfers for page fault — increasing EAT
- FIFO

-
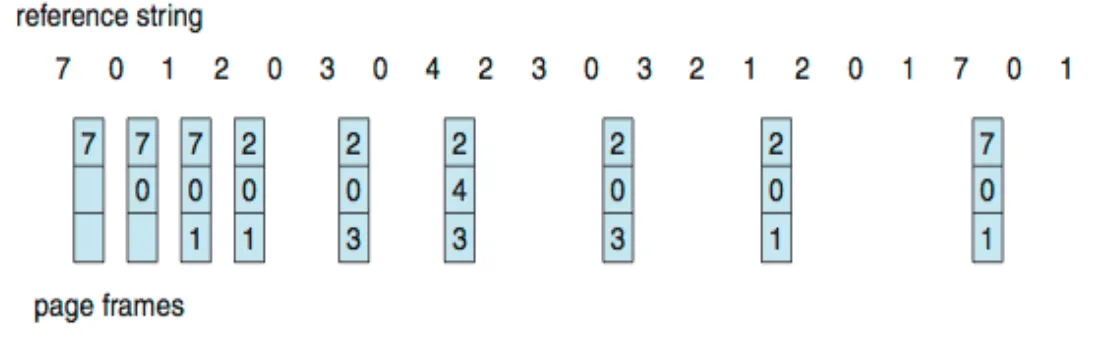
Optimal
-
Replace page that will not be used for longest period of time
-
How do you know this?
- Can’t read the future
-
Need future information (i.e., how long will a page not be needed?) → Not practical — Only used for measuring how well your algorithm performs
-
-
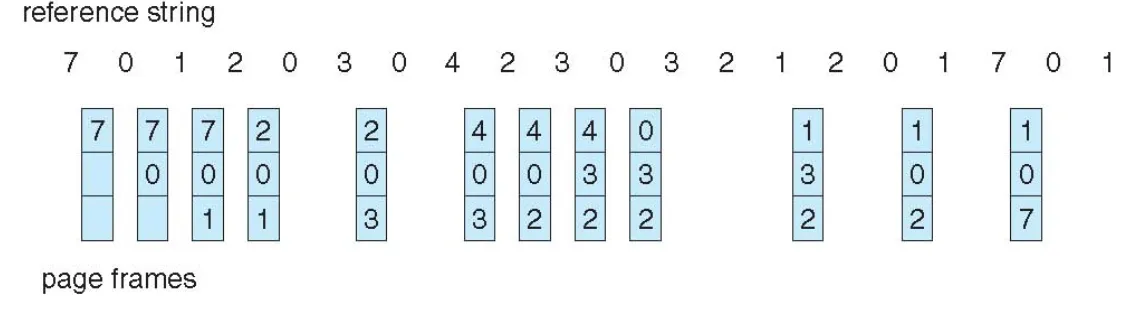
LRU
-
Use past knowledge rather than future
-
Replace page that has not been used in the most amount of time
-
Associate time of last use with each page
-
-
Generally good algorithm and frequently used
-
Implementation
-
Counter
-
Every page entry has a counter; every time page is referenced through this entry, copy the clock into the counter
-
When a page needs to be changed, look at the counters to find smallest value
- Search through table needed
-
-
Stack
-
Keep a stack of page numbers in a double link form:
-
Page referenced:
-
move it to the top
-
requires 6 pointers to be changed
-
-
But each update more expensive
-
No search for replacement
-
-
-
LRU approximation
-
LRU needs special hardware and still slow
-
Reference bit
-
Whether this page has been referred to in the last clock cycle or not
-
With each page associate a bit, initially = 0
-
When page is referenced bit set to 1
-
Replace any with reference bit = 0 (if one exists)
- We do not know the order, however
-
-
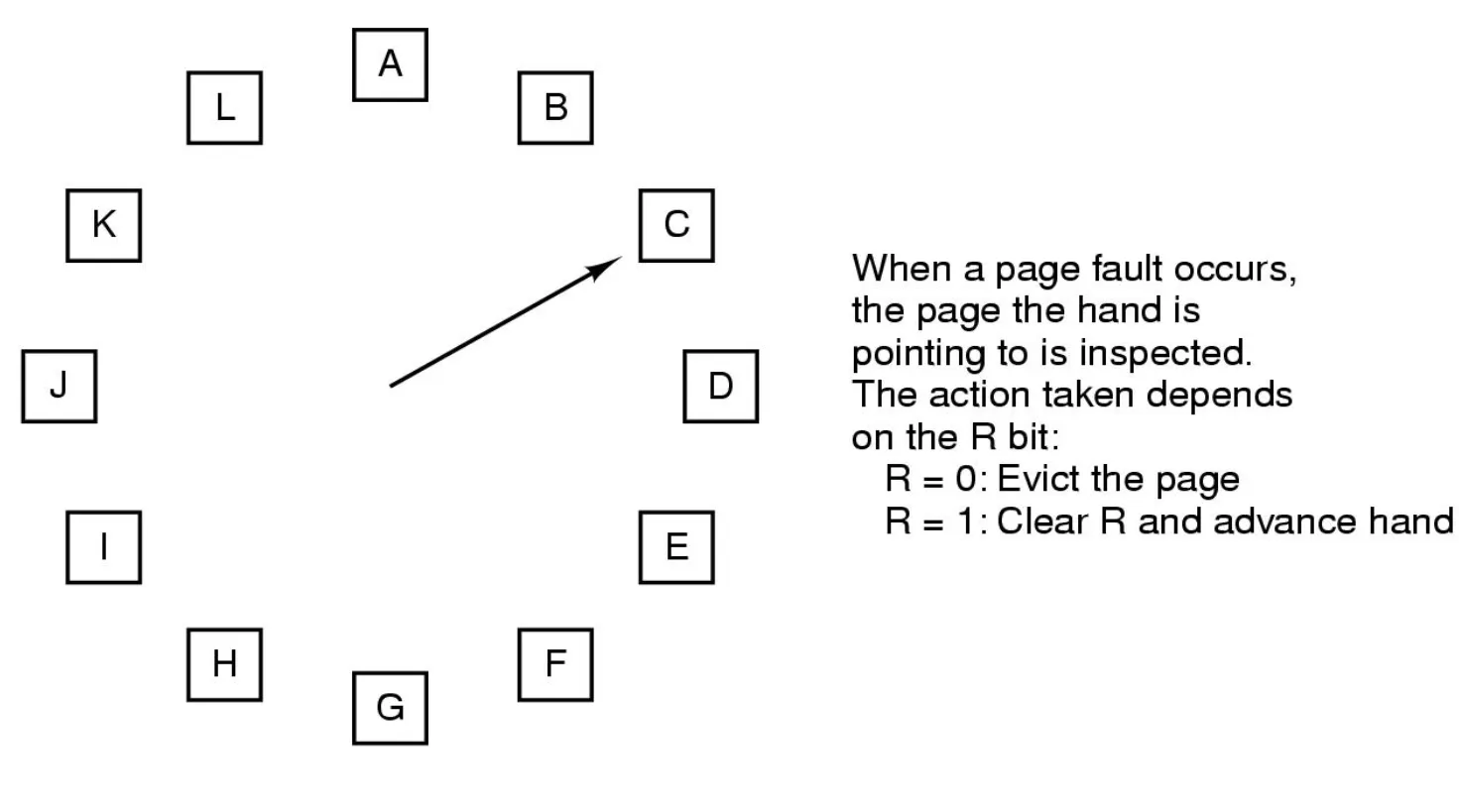
Second-chance algorithm
-
Generally FIFO, plus hardware-provided reference bit
-
Clock replacement
-
If page to be replaced has
-
Reference bit = 0 -> replace it
-
reference bit = 1 then:
-
set reference bit 0, leave page in memory
-
replace next page, subject to same rules
-
-
-
-
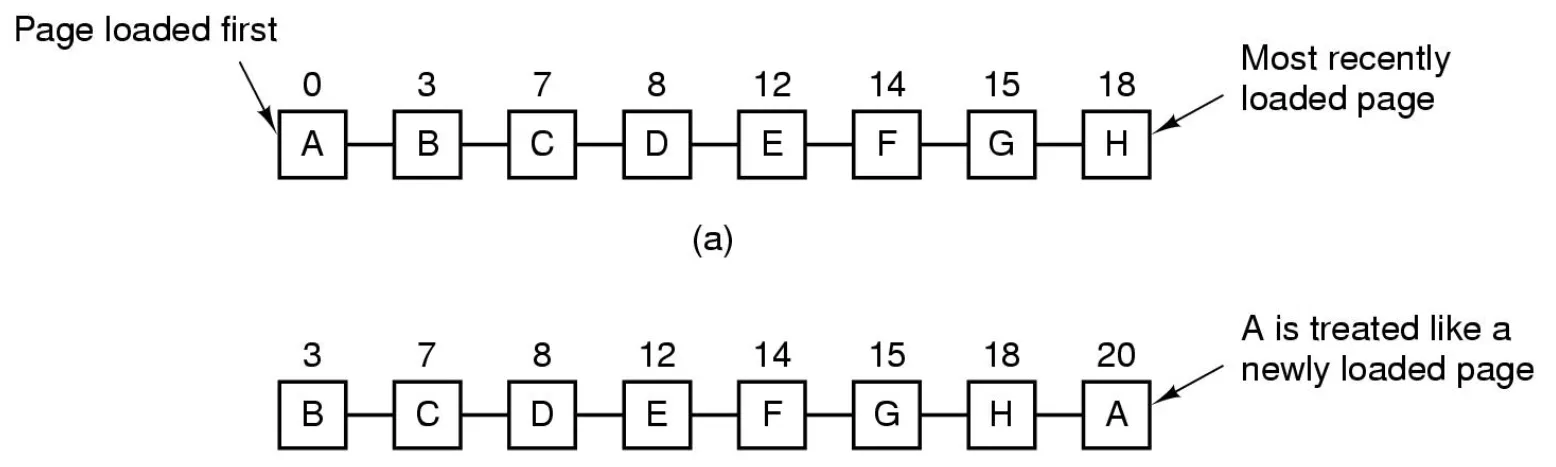
- Clock algorithm
-
Cache
-
Paging allows us to treat physical memory as a cache of virtual memory → all caching principles apply
-
A small subset of active items held in small, fast storage while most of the items remain in much larger, slower storage
-
Includes mechanisms for
-
Recognizing what items are in the cache and for accessing them quickly
-
Bringing things into cache and throwing them out again
-
-
Cache in paging
-
Paged Virtual Memory
-
Very large, mostly stored on (slow) disk
-
Small working set in (fast) RAM during execution
-
-
Page tables
-
Very large, mostly stored in (slow) RAM
-
Small working set stored in (fast) TLB registers
-
-
Application in page
-
Page fault overhead is dominated by time to read page in from disk! (see above for time)
-
Working sets must get larger in proportion to memory speed!
- Disk speed ~ constant (nearly)
-
I.e., faster computers need larger physical memories to exploit the speed!
-
-
-
Issues
-
When to put something in the cache
-
What to throw out to create cache space for new items
-
How to keep cached item and stored item in sync after one or the other is updated
-
How to keep multiple caches in sync across processors or machines
-
Size of cache needed to be effective
-
Size of cache items for efficiency
-
-
Goals
-
To take advantage of locality to achieve nearly the same performance of the fast memory when most data is in slow memory
-
Select size of cache and size of cache items so that p is low enough to meet acceptable performance goal
-
Usually requires simulation of a suite of benchmarks
-
-
-
I/O Files
- User-space I/O software
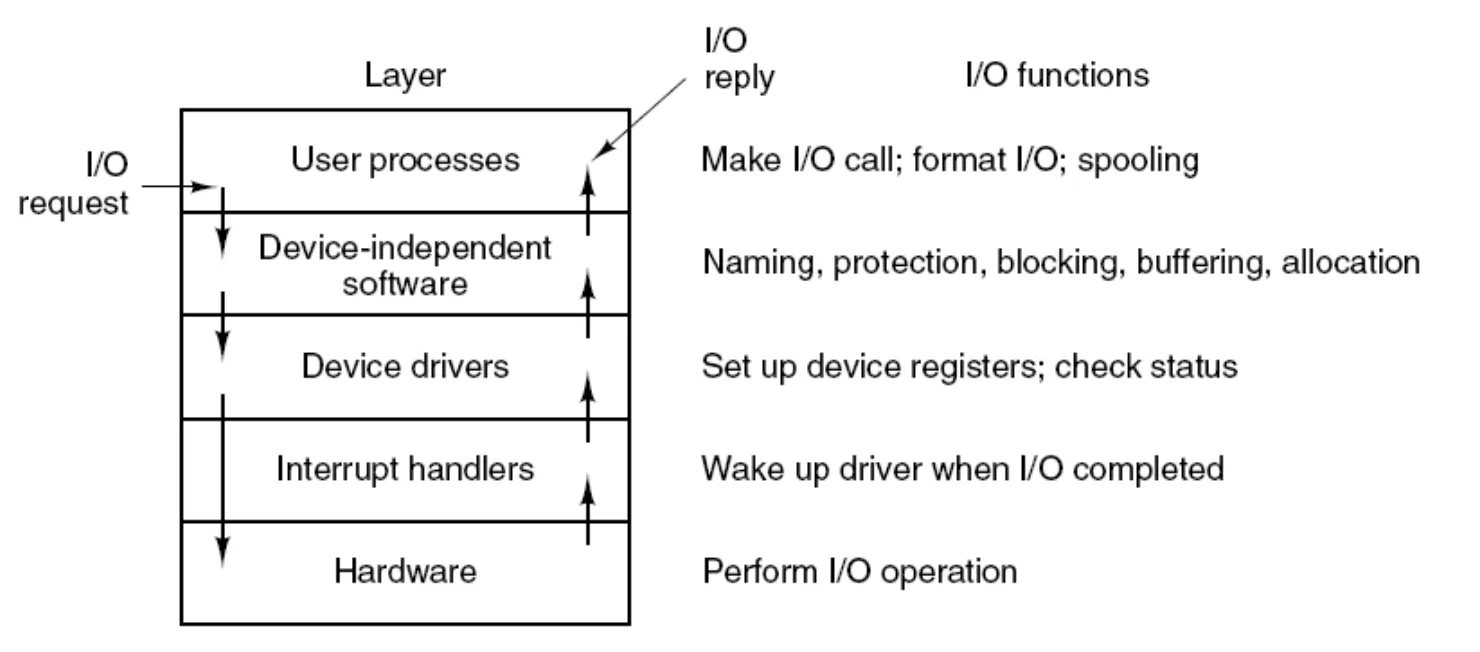
-
File
-
Logical unit of storage in an OS
-
An organizing abstraction
- The way information is organized, stored, kept for a long time, and updated
-
A powerful abstraction
-
Documents, code
-
Databases
-
Streams
-
Input, output, keyboard, display
-
Pipes, network connections, …
-
-
Virtual memory backing store
-
Temporary repositories of OS information
-
Any time you need to remember something beyond the life of a particular process/computation
-
-
Different perspectives
-
User perspective: a name, collection of data
-
System perspective: container of data blocks
-
-
Operations:
-
Open, Close
-
Read, Write, Truncate
-
Seek, Tell
-
Create, Delete
-
-
-
File attributes: name, type, size, protection, dates, locks
-
File metadata
-
Information about a file
-
Maintained by the file system
-
Separate from file itself
-
Usually attached or connected to the file
- E.g., in block # —1
-
Some information visible to user/application
- Dates, permissions, type, name, etc.
-
Some information primarily for OS
- Location on disk, locks, cached attributes
-
-
Observation
-
Some attributes are not visible to user or program
-
E.g., location
-
Location is stored in metadata
-
Location can change, even if file does not
-
Location is not visible to user or program
-
-
-
File name attribute
-
Not attached to file in most modern systems
- Stored in directory
-
Unix/Linux: file may have multiple names
- Example: hard links
-
Windows: file normally has only one name
-
Still stored in directory
-
May be changed without touching the file!
-
-
-
Links
-
Links are file names (directory entries) that point to existing (source) files
-
Symbolic (soft) links
-
Uni-directional relationship between a file name and the file
-
Directory entry with text of absolute or relative path for source
-
If the source file is deleted, the link exists but points to nowhere!
-
-
Hard links
-
Bi-directional relationship between file names and file
-
A hard link is directory entry that points to a source file’s metadata
-
Metadata maintains reference count of the number of hard links pointing to it — link reference count
-
Link reference count is decremented when a hard link is deleted
-
File data is deleted and space freed when the link reference count goes to zero
-
-
-
Unix/Linux hard links
-
File may have more than one name or path
-
rm, mv ---directory operations, not file operations!
-
The real name of a Unix file is internal name of its metadata
- Known only to OS!
-
-
Hard links are not used very often in modern Unix practice
-
Exception: Linked copies of large directory trees!
-
When building your Linux kernel in OS course
-
(Usually) safe to regard last element of path as name of file
-
-
-
-
Accessing files
-
Sequential access
-
Read all bytes or records in order from the beginning
-
Writing implicitly truncates
-
Cannot jump around
-
-
Random access
-
Bytes/records can be read in any order
-
Writing can
-
Replace existing bytes or records
-
Append to end of file
-
Cannot insert data between existing bytes!
-
-
Seek operation moves current file pointer
-
Maintained as part of “open” file information
-
Discarded on close
-
-
-
Keyed (or indexed) access
-
Hardly ever used (outside a DBMS) now
-
Access items in file based on the contents of (part of) an item in the file
-
-
-
Directory: a special kind of files
-
Logical container for files and other subdirectories
-
A tool for users and applications to organize and find files
-
User-friendly names
-
Names that are meaningful over long periods of time
-
-
The data structure for OS to locate files (i.e., containers) on disk
-
Special entries
-
The working directory itself: .
-
Parent in hierarchy: ..
-
Essential for maintaining integrity of directory system
-
-
Operations
-
Create
-
Add, Delete entry
-
Find, List
-
Rename
-
Link, Unlink
-
Destroy
-
-
-
Directory structures
-
Single level
-
One directory per system, one entry pointing to each file
-
Small, single-user or single-use systems
- PDA, cell phone, etc.
-
-
Two-level
-
Single “master” directory per system
-
Each entry points to one single-level directory per user
-
Uncommon in modern operating systems
-
-
Hierarchical
-
Any directory entry may point to
-
Individual file
-
Another directory
-
-
Common in most modern operating systems
-
-
-
Directory considerations
-
Efficiency: locate a file quickly
-
Naming: convenient to users
-
Overloading names across users
-
Separating names across users
-
Uniqueness only within a directory
-
User’s language
-
-
Grouping: logical grouping of files by properties
- e.g., all Java programs, all games,…
-
-
Path name translation
-
fd = open(“/home/staneja/foo.c”, O_RDWR);
-
File system does the following
-
Opens directory ”/” — the root directory is in a known place on disk
-
Search root directory for the directory home and get its location
-
Open home and search for the directory staneja and get its location
-
Open staneja and search for the file foo.c and get its location
-
Open the file foo.c
-
Note that the process needs the appropriate permissions at every step
-
-
File systems spend a lot of time walking down directory paths
- This is why open calls are separate from other file operations
-
File system attempts to cache prefix lookups to speed up common searches
-
”~” for user’s home directory
-
”.” for current working directory
-
-
Once open, file system caches the metadata of the file
-
-
Directory problems
-
Orphan: a file not named in any directory
-
Cannot be opened by any application (or even OS)
-
May be nameless
-
-
Tools
-
FSCK — check and repair file system, find orphans
-
delete_on_close attribute (in metadata)
-
-
-
OS outline
-
Processes
-
Process list
- Process control block (PCB)
-
Process tree
-
Process states
- Events
-
-
Threads
-
Thread control blocks
-
Critical sections
-
Race conditions
-
Mutex
-
Synchronization primitives
-
Locks
-
Condition variables
-
Semaphores
-
-
-
Mechanisms
-
Limited direct execution
-
User mode
-
Kernel mode
-
-
CPU scheduling
-
Cooperative
-
Non-cooperative
-
Timer interrupt
-
Context switch
-
-
-
-
Policies
- Scheduling policy
-