CS 536: Programming Language Design
-
Rust has an affine type system, which is one kind of substructural type system
-
Substructural type systems
-
Type systems that give up one or all of the following structural principles
-
Contraction: Variables can be duplicated freely
-
Weakening: Unused variables are acceptable
-
Exchange: The order in which variables are defined does not limit the order in which they are used, within their scope
-
-
Linear types: +E, -C, -W
- Used to model resource management
-
Affine types: +E, -C, +W
-
Assumes that all data values are capable of being deleted
-
+ Automated memory management without GC
-
- Shared references to data are more complex, the need to copy data increases
-
+ Simplifies the development of correct parallel programs
-
-
-
Value
-
Is a program that represents a result and cannot be executed further
-
Pure data
-
E.g., “my string”, true, false, 0, 0.03
-
-
Variable
-
Has many different meanings, depending on context
-
Immutable (R), mutable (RW), math variable
-
-
References
-
A PL abstraction that provides indirect access to a storage location, e.g., in memory
-
Indirection is a fundamental concept across PLs
-
Pointers (C, C++, etc.): Indirect access is supported through a numeric location, representing an address in memory
-
References (Java, Python, etc.): Indirect access is supported through a location, which is not treated as a number
-
References (Rust): In addition, the type system for references plays an important role in making affine types practical (lifetimes)
-
+ Safe, do not allow for pointer arithmetic, is not interchangeable with its numeric counterpart in other languages
-
+ Allows efficient passing of structures without copying
-
+ Simple tool to write code that is idiomatic in Rust: each variable is used at most once
-
-
-
-
Expressions: computations that can be evaluated for a value
-
e is a program that can be evaluated
-
To evaluate an expression is more than just running it. To evaluate an expression is to run it and, if it terminates get a value as the result
-
Every value is an expression
-
But not every expression is a value
-
Macros
-
Like functions that get executed at compile time to generate custom code which will be executed at runtime
-
E.g., format!() takes in a variable number of arguments whose types are unknown without looking at the format string
-
Thus, cannot write a definition for a format() function that applies for all format strings
-
Languages like C must make their formatting functions unsafe because their type system cannot check a format string against the arguments
-
Rust macros can, by inspecting each macro call one-at-a-time
-
-
Cost complexity, should not be used when functions suffice
-
-
-
Array Expressions
-
Rust has many kinds of arrays. A true array, written [e1, …, …, eN], does not store its length; length must be known at compile time
-
To avoid this restriction, we almost always use vectors, written vec![1,2,3,4], which store their length and can have any length
- The ! Indicates that vec! is a macro. Unlike traditional functions, it can process the syntax of its arguments at compile-time, for example, to support custom syntax
-
All array-like types are homogeneous, meaning all their elements have the same type as each other
-
All array-like types support syntax e[i] for reading (or writing) the i’th element of array e — not recommended due to no bounds checking
-
-
Patterns
-
The compiler performs important correctness checks on pattern-matches
-
Exhaustiveness: Every possible (well-typed) value of the scrutinee (the expression who is being matched against patterns) must match at least one pattern
-
Redundancy: Each pattern must match at least one value that was unmatched by all the previous patterns
-
-
Variable pattern: match every possible value and will define that variable name to be equal to the value
-
Boolean, integer, string, tuple, and array values can appear directly as patterns
- Floating point literals cannot though, challenging for exact comparison
-
Wildcard pattern (_) matches everything else
-
Range pattern (min..max)
-
Or pattern (|)
-
Tuple patterns (pat1, …, patN)
-
-
Definition: a program whose job is to define one or more variables. Introduce names (variables, functions)
-
Parameters: input variables used in function body
-
Arguments: the expression you pass when calling function
-
-
Declaration: a program whose job is to assert which variables exist, without defining their values
-
Statement: a program whose main job is to do something when executed, like modify state or perform output. Runs for side-effects, not return values
-
Side effect: something a program does other than evaluate to a value
-
lvalue: something we can assign to. Means “something that appears at the left side of an assignment”
-
Types
-
Theorem (Many PLs): If an expression terminates, the value has the same type as the expression
-
Theorem (Rust): Well-typed Rust programs are free of memory errors (use-after-free, double-free, memory leak). Rust can be used to guarantee concurrent programs are free of data races and deadlocks as well
-
Strings
-
String slice (&str)
-
Tracks length
-
String literals take on this type, convert to String with .to_string()
- Heap allocation then copy from static data section of the process to the heap
-
Read-only view into a string
-
-
Growable string (String)
-
Heap-allocated, growable, mutable
-
Tracks length
-
-
-
The array type
-
[t;N] means “an array of N elements, each of type t”
-
Requires length to be known at compile time
-
- Restrict usage
-
- Cannot grow
-
+ More space-efficient representation at runtime
-
-
-
The slice type &[t]
-
Refers to an array of elements whose length is not known at compile-time
-
Tracks the length at runtime
-
- Space
-
- Cannot grow
-
+ Flexibility
-
-
The vector type Vec<t>
-
Vector of any length, with elements of type t
-
Growable
-
-
References
-
Immutable reference &t
- A reference that can be used to read a value of type t, but not modify it
-
Mutable reference &mut t
-
Only allowed if the value is mutable
-
E.g., mut e has type t, &mut e has type &mut t, &e has type &t
-
-
Borrowing
-
Most Rust values can only be used once
-
Too strong limitation → References circumvent this by borrowing the ownership of a value temporarily and giving it back at the end
-
Depends on the type — some types support automatic copying
-
Immutable references assume their values never change
-
At any point in time, can only have one mutable reference OR multiple immutable references to a value, but never both
-
Acronym WOoRM: Write One or Read Many
-
-
-
Inductive/recursive types
-
enum IntLinkedList { Empty, Cons(i32, IntLinkedList), }
-
Will produce compiler error: “recursive type `IntListList` has infinite size” and suggests: “insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle: `Box<`, `>`”
-
Cannot declare variable/“infinitely nested” size of types in memory → Box<t>
-
The Box<t> type represents a smart pointer, which always has a fixed size, no matter how complex the underlying data. In simpler words: implementing inductive types requires references for indirection, just as a pointer would be used to implement them in C.
-
Traits
-
Hash: stores values in hash table
-
Eq, PartialEq: compare values for equality
-
Debug: produces string representations suitable for format! and println!
-
Clone: deep copy
-
-
Regular expression (Regex)
-
A programming language where every program defines a string language (a set of strings)
-
Core features
-
Character regex
-
Matches a single character (e.g., ‘a’ matches “a”)
-
Escaping: Use \ for special characters (e.g., \* matches ”*”)
-
-
Sequential composition
- Combines two regexes (e.g., ‘ab’ matches “ab”)
-
Choice
- Matches either of two regexes (e.g., ‘a|b’ matches “a” or “b”)
-
Repetition
- Matches zero or more repetitions of a regex (e.g., ‘a*’ matches "", “a”, “aa”, etc.)
-
Parentheses
- Clarifies order of operations (e.g., ‘(a|b)c’ vs. ‘a|(bc)’)
-
Zero regex
- Matches no strings (e.g., ” matches nothing)
-
-
Defineable (syntatic sugar) features
-
Wildcard
-
Matches any single character (e.g., ’.’ matches “a”, “b”, etc.)
-
Commonly used with repetition (e.g., ’.*’ matches any string)
-
-
Ranges and sets
-
Matches a range or set of characters (e.g., ‘[a-z]’ matches any lowercase letter)
-
Negation: Use ^ inside brackets (e.g., ’[^0-9]’ matches any non-digit)
-
-
Extended matching
-
Matches substrings within a larger string
-
Begin (^) and end ($)
-
^ matches the start of a string
-
$ matches the end of a string
-
Example: ‘^error’ matches lines starting with “error”
-
-
\d matches any one digit
-
r{k} matches exactly k copies of r
-
r+ matches 1 or more copies of r
-
-
-
Mathematical meaning
-
String language
-
For a regex r, L(r) is the set of strings it matches
-
Defined recursively
-
L(”) = {} (empty set)
-
L(‘c’) = {“c”} (single character)
-
L(r1r2) = L(r1) o L(r2) (concatenation)
-
L(r1|r2) = L(r1) ∪ L(r2) (union)
-
L(r*) = L(r)* (Kleene star)
-
-
Example: L(‘(a|b)*’) = all strings of “a” and “b”
-
-
-
Pumping lemma
-
Purpose: Determines if a language is regular
-
Statement:
-
For any regular expression r, there exists a pumping length n such that any string s of length |s| ≥ n can be split into xyz where:
- xyᵏz ∈ L(r) for all k ≥ 0.
-
-
Implication: If a language does not satisfy the pumping lemma, it is not regular
-
-
-
Parsing
-
A string is syntactically valid if it follows the grammar of the language
-
A syntactically valid string has a semantics if it can be assigned a meaning. It has an ambiguous semantics if >1
-
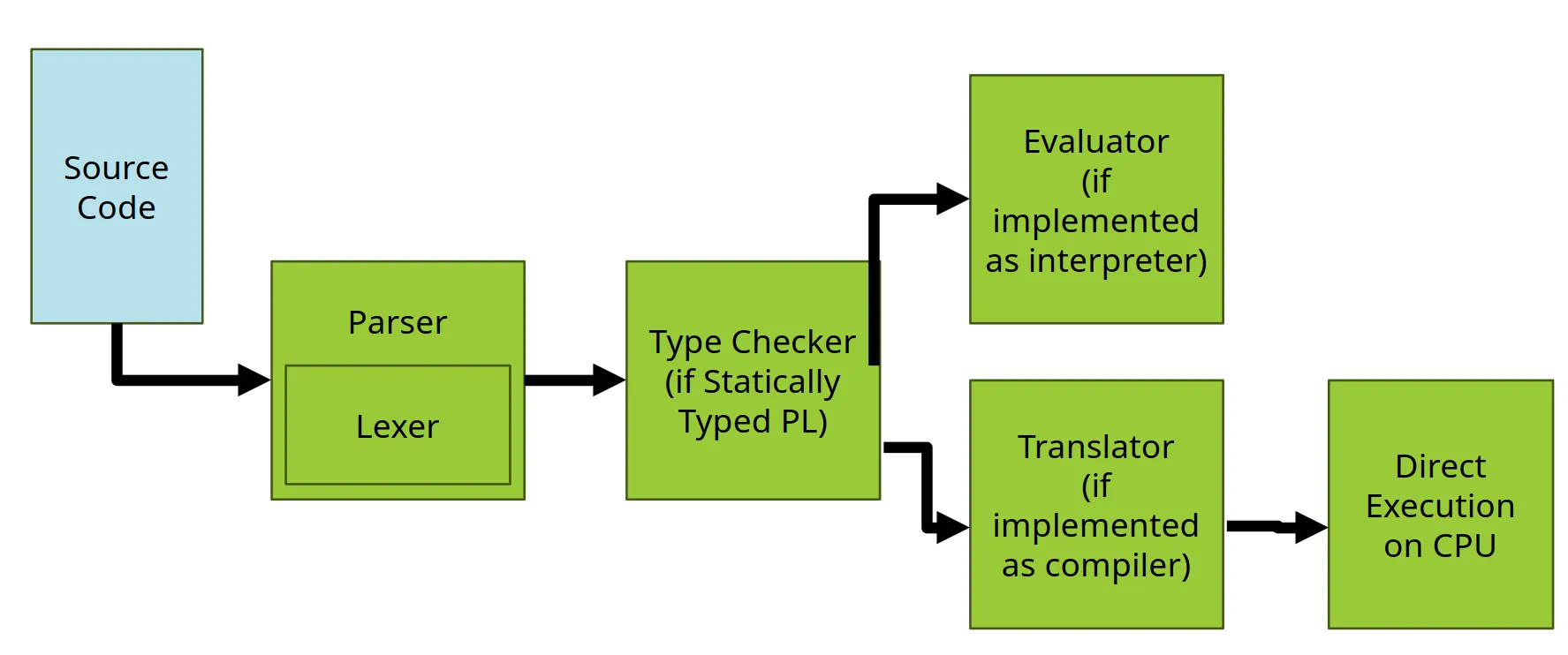
-
Context-free grammars can define recursive string languages (e.g., syntaxes of PLs)
-
Basis of many tools for implementing PL parsers
-
Goal: Discover the tree-like (recursive) structure of a program
-
A CFG must specify:
-
A set of variable symbols which are all of the symbol names except tokens
-
A set of terminal symbols which are names of tokens
-
Rules V → S … S turning V into S…S
-
The start symbol: what are we trying to make? What’s at the top of the tree?
-
-
Derivations: To parse a string str (of tokens), we derive it from the CFG
-
Start with the start symbol S
-
Repeatedly, replace any symbol A with right-hand-side B of some rule A → B
-
When you have the string str, you’re finished parsing it
-
The derivation can be used to read off a tree showing the program structure
-
-
Language of a CFG: the set of all valid strings that can be derived from the start symbol by applying production rules
- L(CFG) = { str | str there exists a derivation S → str according to CFG}
-
Ambiguity: A grammar is ambiguous if a string can be derived in multiple ways, leading to different parse trees (and potentially different interpretations)
-
Precedence ambiguity: when there are two different operators (+, *) and you don’t know which one comes first
- Fix idea: insert new variable symbol. Force * to be tighter than +
-
Associativity ambiguity: when the same operator appears twice and we don’t know the order, but it matters. E.g., subtraction
- Same fix
-
-
Both fixes share the same idea called precedence climbing
-
Operators are divided into precedence levels. High precedence = tighter
- e.g. a*b + c*d is (a*b) + (c*d) and * is higher precedence than +
-
The precedence level starts at the lowest level
-
Precedence increases at the right of a left-associative operators, vice-versa
-
Once precedence increases, you can never again parse a low-precedence operator unless you reset the level with parens ()
-
Precedence starts low and climbs because CFG is top-down
-
-
Traditional parsing = RE + CFG
-
RE “lexing” identifies basic building blocks like “x” or ”=” or “124.4”
-
CFG parsing organizing basic building blocks into full tree
-
Ambiguous CFG often bad, often fixable (precendence climbing)
-
-
-
Parsing expression grammars (PEGs): A style of formal grammars that are unambiguous and have a clear operational meaning
-
Contrast with CFGs, which can be ambiguous
-
Eliminate ambiguity by using prioritized choice (try first rule, if fails, try second…)
-
Can be understood as algorithms: predictable execution
-
Trade-offs
-
Some CFGs cannot be expressed by PEGs
-
Can lead to infinite loops if not carefully designed
-
-
Syntax
-
PEGS are defined using left arrows (←)
-
Atomic PEGs
-
String literals (e.g., “grammar”)
-
Character classes (e.g., [a-z])
-
Wildcard (. matches any character)
-
-
Unary suffix operators
-
e?: Optional (matches e zero or one time)
-
e*: Zero or more repetitions of e
-
e+: One or more repetitions of e
-
-
Unary prefix operators (Lookahead)
-
&e: Positive lookahead (succeeds if e matches but consumes no input)
-
!e: Negative lookahead (succeeds if e does not match)
-
-
Sequential composition
- e1 e2: Matches e1 followed by e2
-
Prioritized choice
- e1 / e2: Tries e1 first, then e2 if e1 fails
-
-
-
Precedence-climbing parsers
-
A technique for parsing infix operators with precedence and associativity
-
Works for both CFGs and PEGs
-
Key idea
-
Start parsing at the lowest precedence level
-
Increase precedence when parsing operands
-
Use repetition to handle multiple operators at the same precedence level
-
-
Termination: Guaranteed because at least one character is consumed at the highest precedence level
-
Efficiency: Linear time for a fixed number of precedence levels
-
Metaphor: Precedence-climbing is like a system of escalators---you can go up at any time but can only go down when you see parentheses
-
-
Evaluating
-
Abstract syntax trees (ASTs)
-
Trees representing the structure of a program after parsing
-
Emphasize how program structure should be represented for easy implementation
-
Reusable: compiler, interpreter, and pretty-printer can all use same parser
-
Or reuse compiler with new parser for new syntax
-
-
Relation to parse trees (PTs)
-
Parse trees: Focus on the structure encoded in the source code
-
ASTs: Focus on representation for implementation ease
-
-
Example
-
value = NumberValue(int)
-
expr = Id(string) | Number(int) | Times(expr, expr) | Plus(expr, expr) | Minus(expr, expr) | Let(defn, expr) | Call(string, expr)
-
defn = Var(string, expr) | Fun(string, string, expr)
-
-
-
Algebraic data types (ADTs)
-
-
Types combining inductive definition (recursion), tuples (AND), and choice (OR)
-
Not inherently related to ASTs, but extremely useful for ASTs
-
Examples
-
Lists: int_list = Empty() | NonEmpty(int, int_list)
-
Binary trees: int_tree = Leaf() | Node(int_tree, int, int_tree)
-
-
Operations on ADTs
-
Creation: Constructor
- Each variant can be used as a function
-
Taking apart: Pattern matching
-
Functions defined case-by-case over ADTs
- Example: length(Empty) = 0, length(NonEmpty(x, L)) = 1 + length(L)
-
-
From grammars to ASTs
-
Process
-
Start with a formal grammar
-
Define ADTs for each variable symbol in the grammar
-
Create one variant for each production rule
-
-
Example
-
V → num
-
E → id | num | E ”*” E | E ”+” E | E ”-” E | “let” D “in” E | id ”(” E ”)”
-
D → id ”=” E | id ”(” id ”)” ”=” E
-
-
-
Interpreters
-
An evaluator is a function that runs programs
-
An interpreter is the complete PL implementation: parser + evaluator
-
An evaluator is a function from programs to values
- eval : Program → Value
-
Environments
- Track variable definitions during interpretation
-
-
-
Types
-
Immutable variables: Implemented by substitution.
-
Mutable variables: Implemented by maintaining state in an environment.
-
-
Environment definition: E : Var ⇀ Value ∪ (String, Expr)
-
Notation
-
E(x): Value assigned to variable x.
-
E[x↦v]: Environment assigning value v to variable x.
- Interpretation algorithm
-
-
Interpreter function: interpreter : Program → Value
-
Core functions
-
interp_expr: (Env, Expr) → Value
-
interp_defn: (Env, Defn) → Env
-
-
Pseudocode
-
interpreter(e) = interp_expr({}, e)
-
Cases for Id, Number, Times, Plus, Minus, Let, Call, Var, Fun
-
Advanced implementation techniques
-
Hash-consing
-
Ensure each ADT value appears at most once in memory
-
Space savings and constant-time comparisons
-
-
Arenas
-
Efficient memory allocation and deallocation for short-lived objects
-
Allocate AST nodes in a dedicated arena
-
-
Line numbers and efficiency
-
Provide useful error messages with minimal memory overhead
-
Store metadata out-of-band and recompile with metadata on error
-
-
-
-
-
Operational semantics
-
Defines the meaning of a program by describing how it runs
-
Phases of language implementation
-
Parsing: Converts syntax into an AST
-
Type-checking: Analyzes the AST for type errors (in statically-typed languages)
-
Translation: Converts high-level AST into lower-level representations (in compilers)
-
Execution: Runs code (in interpreters or on hardware)
-
-
Errors
-
Syntax errors: Detected during parsing
-
Type errors: Detected during type-checking
-
Runtime errors: Occur during execution
-
Output errors: Detected after execution
-
-
Approaches to semantics
-
Denotational: What mathematical concept models code?
-
Equational: When do 2 programs mean the same thing?
-
Operational: How does a program run?
-
Big-step: assume program terminates, what value does it evaluate to? Does not consider programs that loop forever
-
Small-step: execute program one step at a time. Can use to talk about forever-looping programs
-
-
-
Inference rules
-
Judgements: Formal mathematical assertions defined using inference rules
-
Example: `e ↪ v` (big-step semantics), `e1 ↦ e2` (small-step semantics)
-
-
Inference rule notation
-
Premises: Above the horizontal line
-
Conclusion: Below the horizontal line
-
Side conditions: Optional, written in parentheses
-
Example
-
```
-
Premise1 Premise2
-
------------------------------------------------ (side condition)
-
Conclusion
-
```
-
-
Big-step semantics
-
Big-step evaluation: Evaluates a program all at once
-
Notation: `e ↪ v` (“e evaluates to v”)
-
Rules:
- EvalVal: A value evaluates to itself
-
-
```
v value
v ↪ v
```
- EvalOp: Evaluates operands and applies the operation
```
e1 ↪ v1 e2 ↪ v2
e1 op e2 ↪ v1 op v2
```
-
Small-step semantics
-
Small-step evaluation: Executes a program one step at a time
-
Notation: `e1 ↦ e2` (“e1 steps to e2 in one step”), `e1 ↦* e2` (“e1 steps to e2 in any number of steps”)
-
Rules:
-
Beta rules: Core rules for stepping (e.g., `BetaVar`, `BetaOp`)
-
Structural rules: Allow stepping of subexpressions (e.g., `StepOpS1`, `StepOpS2`)
-
-
-
Environments
-
Environments (E): Used to handle variables and function definitions
-
Notation: `E ⊢ e ↪ v` (“in environment E, expression e evaluates to v”)
-
Rules:
- EvalVar: Evaluates a variable by looking it up in the environment
-
```
*
E ⊢ x ↪ v
(where E(x) = v)
```
- EvalLetVar: Adds a variable to the environment
```
E ⊢ e1 ↪ v1 E,x↦v1 ⊢ e2 ↪ v2
E ⊢ (let x = e1 in e2) ↪ v2
```
-
Errors
-
Error judgement: `E ⊢ e error` (program e produces a runtime error in one step)
-
Example: `EvalVarErr` for undefined variables
-
```
*
E ⊢ x error
(where x is not defined in E)
```
-
Relating judgements
- StepsEq: Relates stepping to equality
```
e1 ↦* e2
e1 = e2
```
-
Types
-
Role of static types in correctness
- Examples: factorial function, next_day function
-
Values of static types
-
Bug detection
-
Documentation
-
Performance
-
-
Theorist’s perspective
-
Universality: apply to every program
-
Rigor
-
“Theorems for Free”: certain theorems about the behavior of a value fall directly out of its type
-
-
Type safety
-
Milner’s principle: “Well-typed programs cannot go wrong”
-
Variants: memory safety (Rust), proof correctness (Coq)
-
Focus theorem: “If program has type t and returns value v ⇒ v has type t”
-
-
Example programming language
-
Grammar:
-
Values: n | true | false | ()
-
Expressions: x | e op e | f(e) | e;e | x := e | if/else | while | let
-
Definitions: x : t = e | f(x:t):t = e
-
Types: bool | num | unit | t→t
-
-
Values
-
num: Integer literals
-
bool: true/false
-
unit: Single value ()
-
-
Expressions
-
Variables, assignment (x := e)
-
Sequencing (e1;e2), operators (e1 op e2)
-
Function calls (f(e)), conditionals (if), loops (while)
-
let expressions for definitions
-
-
Definitions
-
Variable: x : t = e
-
Function: f(x:t1):t2 = e
-
-
Types
-
Base types: bool, num, unit
-
Function types: t1→t2
-
Higher-order functions (e.g., num→(num→bool))
-
-
Type contexts (Γ)
-
Maps variables/functions to types
-
Syntax: Γ ::= · | Γ, x:t
-
Environment consistency: E : Γ
-
-
Typing judgements
-
Expressions: Γ ⊢ e : t
-
Definitions: Γ ⊢ d : Δ (produces new context)
-
-
Typing rules
-
Values:
- TyNum, TyTrue, TyFalse, TyUnit
-
Expressions:
- TyVar, TyAsgn, TySeq, TyOp, TyApp, TyIf, TyWhile, TyDef
-
Definitions:
- DefVar, DefFun
-
-
-
Type-checker pseudocode
-
Algorithm for tc(C, e) with case analysis
-
Handling variables, assignments, functions, conditionals, loops
-
-
Big-step operational semantics
-
Judgement: E ⊢ e ↪ (E’, v)
-
Key rules:
-
OpVal, OpVar, OpOp
-
OpDefVal, OpDefFun, OpAsgn
-
OpIf1/OpIf2, OpWhile1/OpWhile2
-
-
-
Proofs
-
Type safety theorem:
- If Γ ⊢ e : t and E : Γ and E ⊢ e ↪ (E’, v) ⇒ E’ : Γ and Γ ⊢ v : t
-
Proof techniques:
-
Rule induction on derivations
-
Progress/Preservation lemmas (small-step)
-
Inversion lemma
-
-
Case analysis for each semantic rule
-
-
-
Midtern
-
Vocabulary and Schools of Thought: 20pt
-
Define the following terms
-
Value
-
Is a program that represents a result and cannot be executed further
-
Pure data
-
-
Expression
- computations that can be evaluated for a value
-
Statement
-
a program whose main job is to do something when executed, like modify state or perform output
-
Runs for side-effects, not return values
-
-
Definition
-
a program whose job is to define one or more variables
-
Introduce names (variables, functions)
-
-
Pattern
-
The compiler performs important correctness checks on pattern-matches
-
Exhaustiveness: Every possible (well-typed) value of the scrutinee (the expression who is being matched against patterns) must match at least one pattern
-
Redundancy: Each pattern must match at least one value that was unmatched by all the previous patterns
-
-
-
Reference
- A PL abstraction that provides indirect access to a storage location, e.g., in memory
-
Static type
- A PL feature that specifies variable types during compilation
-
Judgement
-
Formal mathematical assertions defined using inference rules
-
Example: `e ↪ v` (big-step semantics), `e1 ↦ e2` (small-step semantics)
-
-
(Inference) rule: “result” of the judgement
-
Big-step evaluation: Evaluates a program all at once
-
Small-step evaluation: Executes a program one step at a time
-
-
Type safety
- the extent to which a programming language discourages or prevents type errors
-
-
Draw a Venn-like diagram of the Chomsky hierarchy of formal languages, as presented in the Regular Expressions lecture
-
-

-
Name the 5 archetypes (i.e., characters or schools of thought) in HCPL. Describe in one in ~1 sentence. Give examples of what activities each one would do.
-
Practitioner: Goal-oriented programmers focused on writing code efficiently for work/hobbies, valuing practical aspects like syntax, tooling, and error messages.
Activities: Coding specific projects, discussing language features on forums (e.g., StackOverflow), optimizing workflows, reading language-specific guides (e.g., “The Rust Book”). -
Implementer: Developers who build compilers/interpreters, prioritizing tools like parsers, abstract syntax trees, and intermediate representations (e.g., LLVM).
Activities: Designing grammars, optimizing compilers, debugging semantic behaviors, reading compiler-construction textbooks. -
Social Scientist: Researchers studying programming communities through empirical methods (quantitative/qualitative) to analyze inclusivity, productivity, or social dynamics.
Activities: Conducting surveys on developer behavior, publishing HCI studies, analyzing GitHub collaboration patterns -
Humanist: Scholars applying humanities methods (e.g., rhetorical analysis, critical theory) to critique programming cultures and code-as-text.
Activities: Analyzing rhetoric in language documentation, theorizing power structures in open-source communities, close-reading code aesthetics -
Theorist: Mathematically inclined designers focused on formal language properties (e.g., type systems, semantics) to ensure correctness via abstraction.
Activities: Proving type-safety theorems, designing static analyzers, debating abstraction tradeoffs, studying formal semantics
-
-
Rust
-
From textbook: 3.6.[a-e], 3.7.[a-g], 3.9.[a-k]
-
Additional format: For the above programming questions, we could also ask you to read and understand code that implements the given programming problem.
-
Additional question: For each of the following Rust programs, select whether it obeys or violates the WOoRM (Write One or Read Many) rule. Assume function f is defined with appropriate type in the third example.
-
• let mut x = 5;
-
let r1 = &mut x;
-
let r2 = &mut x;
-
*r1 = *r2 + 1;
-
• let mut x = 5;
-
let imm = &x;
-
let r = &mut x;
-
let x1 = *imm;
-
*r = x + 1;
-
let x2 = *imm;
-
• let x = 5;
-
let ir1 = &x;
-
let ir2 = &x;
-
f(ir1,ir2);
-
• let mut x = 5;
-
let r = &mut x;
-
*r = 3;
-
-
-
Regular Expressions (Regex): 25pt (typical questions: “which regex implements this language? Is this string in this language? Find the bug in the given regex)
-
Theory
-
A programming language where every program defines a string language (a set of strings)
-
Core features
-
Character regex
-
Matches a single character (e.g., ‘a’ matches “a”)
-
Escaping: Use \ for special characters (e.g., \* matches ”*”)
-
-
Sequential composition
- Combines two regexes (e.g., ‘ab’ matches “ab”)
-
Choice
- Matches either of two regexes (e.g., ‘a|b’ matches “a” or “b”)
-
Repetition
- Matches zero or more repetitions of a regex (e.g., ‘a*’ matches "", “a”, “aa”, etc.)
-
Parentheses
- Clarifies order of operations (e.g., ‘(a|b)c’ vs. ‘a|(bc)’)
-
Zero regex
- Matches no strings (e.g., ” matches nothing)
-
-
Defineable (syntatic sugar) features
-
Wildcard
-
Matches any single character (e.g., ’.’ matches “a”, “b”, etc.)
-
Commonly used with repetition (e.g., ’.*’ matches any string)
-
-
Ranges and sets
-
Matches a range or set of characters (e.g., ‘[a-z]’ matches any lowercase letter)
-
Negation: Use ^ inside brackets (e.g., ’[^0-9]’ matches any non-digit)
-
-
Extended matching
-
Matches substrings within a larger string
-
Begin (^) and end ($)
-
^ matches the start of a string
-
$ matches the end of a string
-
Example: ‘^error’ matches lines starting with “error”
-
-
\d matches any one digit
-
r{k} matches exactly k copies of r
-
r+ matches 1 or more copies of r
-
-
-
-
4.3.[a-m], 4.4[a-c], 4.6.[a-i], 4.7.[a-e] (datatype of core regular expressions would be provided), 4.8.[a-k], 4.9.[a-i]
-
Expected formats:
-
“Given these regexes and these descriptions of languages, which regex implements which language?”
-
“Given this string and this regex, does the string match the regex?”
-
“Give a description of a language and a buggy regex that tries to implement it, identify strings that reveal the bug in the implementation. That is, identify strings that are in the language but do not match the regex or vice versa”
-
-
-
CFGs:
-
Theory
-
Can define recursive string languages (e.g., syntaxes of PLs)
-
Basis of many tools for implementing PL parsers
-
Goal: Discover the tree-like (recursive) structure of a program
-
-
Can be ambiguous → solve with precedence climbing
-
-
5.7.a (would provide definition / examples of S-expression syntax) 5.10.[a-f], 5.12.[a-c], 5.13.[a-h]
-
Convert Parse Tree to Derivation (15pt)
-
Consider the polynomial grammar from the CFG lecture. Translate the following parse tree to a derivation (there are multiple correct answers):
-
Grammar: S → num | var | (S) | S op S
-
Derivation
-
S → S op S
-
S op S → S op S op S
-
S op S op S → num op S op S
-
num op S op → num op var op S
-
num op var op S → num op var op S op S
-
num op var op S op S → num op var op var op S
-
num op var op var op S → num op var op var op num
-
-
-
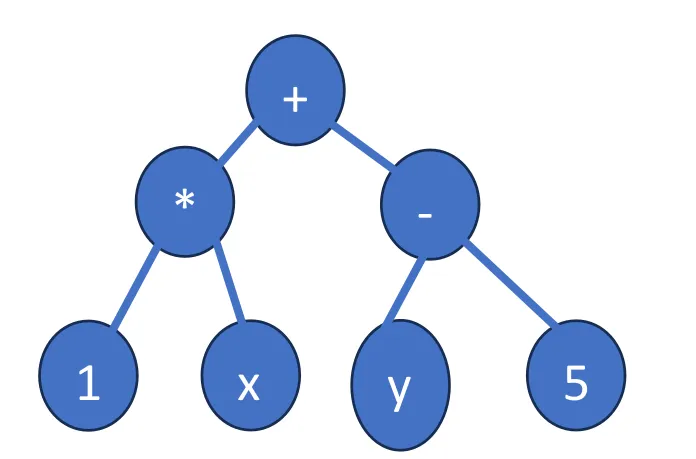
-
Conversely, convert the following derivation into a parse tree
-
S -> S op S
-
S op S -> S op S op S
-
S op S op S -> id op S op S
-
id op S op S -> id op id op S
-
id op id op S -> id op id op id
-
CFG parsing ends at this stage, but for example, this sequence of terminal symbols would match the string “x + y * z”
-
CFG + PEG (other): 10pt
-
Parsing Expression Grammars
-
Style of formal grammars that are unambiguous and have a clear operational meaning
-
Contrast with CFGs, which can be ambiguous
-
Eliminate ambiguity by using prioritized choice (try first rule, if fails, try second…)
-
Can be understood as algorithms: predictable execution
-
Trade-offs
-
Some CFGs cannot be expressed by PEGs
-
Can lead to infinite loops if not carefully designed
-
-
-
For each CFG in 5.11 and 5.13, either write a PEG which matches the same language as the CFG, or explain in one sentence why none exists
-
-
Comparing Regex vs CFG vs PEG:
-
1) Which is weakest: regex, CFG, or PEG? Weakest means that it can define fewer languages, only simpler languages compared to the others.
- Regex (regular expressions) are the weakest. They can only describe regular languages, which are a strict subset of context-free languages (CFG) and parsing expression grammars (PEG).
-
2) Comparing the strength of regex, CFG, and PEG, which of the following statements is true about the strongest one? Is there a strongest one? Are more than one equally strong? Are they stronger than each other in different ways?
-
Regex < CFG = PEG.
-
Regex is the weakest, limited to regular languages.
-
CFGs and PEGs are equally strong in different ways: CFGs can handle recursive string languages but are ambiguous, while PEGs are unambiguous but cannot express some CFGs.
-
-
3) Which best describes the limitations of regex?
-
a. Can’t handle recursion (X)
-
b. Can’t handle repetition
-
c. Generates strings, doesn’t recognize a given input string
-
d. Always harder to read than CFG or PEG
-
-
4) Which best explains why weak languages like regex are widely used?
-
a. Weak languages often provide stronger guarantees, e.g., regex is easier to compile into highly-efficient state machine formats (X)
-
b. Weak languages are reflective of weak people
-
c. Regex notation is especially easy to understand
-
d. Regex is mostly used in legacy code, it is not widely used in new code
-
-
-
To help you prepare, here is an approximate breakdown of the sections on the exam and their likely grade point distributions. I do not guarantee that these will be an exact match for the real exam:
-
Vocabulary and background: 15pt
-
Rust and HW code: 20pt
-
Regex: 20pt
-
6 usability questions: 15pt
-
Survey design 10pt
-
Disability: 10pt
-
Other case studies: 10pt
-
Total: 100pt
Many of the questions below are drawn from the textbook, “Human-Centered Programming Languages”. For these questions, I simply give the chapter and exercise numbers. Some problems may be new, in which case we give the full problem text.
Vocabulary
Section titled “Vocabulary”To study:
Define the following terms
-
Value: Is a program that represents a result and cannot be executed further. Pure data
-
Expression: computations that can be evaluated for a value
-
Statement: a program whose main job is to do something when executed, like modify state or perform output. Runs for side-effects, not return values
-
Definition: a program whose job is to define one or more variables. Introduce names (variables, functions)
-
Pattern: The compiler performs important correctness checks on pattern-matches
-
Exhaustiveness: Every possible (well-typed) value of the scrutinee (the expression who is being matched against patterns) must match at least one pattern
-
Redundancy: Each pattern must match at least one value that was unmatched by all the previous patterns
-
-
Reference: A PL abstraction that provides indirect access to a storage location, e.g., in memory
-
Static type: A PL feature that specifies variable types during compilation
-
Judgement: Formal mathematical assertions defined using inference rules
- Example: `e ↪ v` (big-step semantics), `e1 ↦ e2` (small-step semantics)
-
(Inference) rule: “result” of the judgement
-
Big-step evaluation: Evaluates a program all at once
-
Small-step evaluation: Executes a program one step at a time
-
-
Type safety: the extent to which a programming language discourages or prevents type errors
Draw a Venn-like diagram of the Chomsky hierarchy of formal languages, as presented in the Regular Expressions lecture.
Name the 5 archetypes (i.e., characters or schools of thought) in HCPL. Describe in one in ~1 sentence
-
Practitioner: Goal-oriented programmers focused on writing code efficiently for work/hobbies, valuing practical aspects like syntax, tooling, and error messages.
-
Implementer: Developers who build compilers/interpreters, prioritizing tools like parsers, abstract syntax trees, and intermediate representations (e.g., LLVM).
-
Social Scientist: Researchers studying programming communities through empirical methods (quantitative/qualitative) to analyze inclusivity, productivity, or social dynamics.
-
Humanist: Scholars applying humanities methods (e.g., rhetorical analysis, critical theory) to critique programming cultures and code-as-text.
-
Theorist: Mathematically inclined designers focused on formal language properties (e.g., type systems, semantics) to ensure correctness via abstraction.
On exam: We reserve the right to test this knowledge in a simpler format, such as match-the-word-and-definition questions.
From textbook: 3.6.[a-e], 3.7.[a-g], 3.9.[a-k]
Additional question: For each of the following Rust programs, select whether it obeys or violates the WOoRM (Write One or Read Many) rule. Assume function f is defined with appropriate type in the third example.
-
• let mut x = 5; violates
-
let r1 = &mut x;
-
let r2 = &mut x;
-
*r1 = *r2 + 1;
-
• let mut x = 5; violates
-
let imm = &x;
-
let r = &mut x;
-
let x1 = *imm;
-
*r = x + 1;
-
let x2 = *imm;
-
• let x = 5; obeys
-
let ir1 = &x;
-
let ir2 = &x;
-
f(ir1,ir2);
-
• let mut x = 5; obeys
-
let r = &mut x;
-
*r = 3;
Parsing
Section titled “Parsing”Regular expressions:
4.3.[a-m], 4.4[a-c], 4.6.[a-i], 4.7.[a-e] (datatype of core regular expressions would be provided), 4.8.[a-k], 4.9.[a-i]
-
Theory
-
A programming language where every program defines a string language (a set of strings)
-
Core features
-
Character regex
-
Matches a single character (e.g., ‘a’ matches “a”)
-
Escaping: Use \ for special characters (e.g., \* matches ”*”)
-
-
Sequential composition
- Combines two regexes (e.g., ‘ab’ matches “ab”)
-
Choice
- Matches either of two regexes (e.g., ‘a|b’ matches “a” or “b”)
-
Repetition
- Matches zero or more repetitions of a regex (e.g., ‘a*’ matches "", “a”, “aa”, etc.)
-
Parentheses
- Clarifies order of operations (e.g., ‘(a|b)c’ vs. ‘a|(bc)’)
-
Zero regex
- Matches no strings (e.g., ” matches nothing)
-
-
Defineable (syntatic sugar) features
-
Wildcard
-
Matches any single character (e.g., ’.’ matches “a”, “b”, etc.)
-
Commonly used with repetition (e.g., ’.*’ matches any string)
-
-
Ranges and sets
-
Matches a range or set of characters (e.g., ‘[a-z]’ matches any lowercase letter)
-
Negation: Use ^ inside brackets (e.g., ’[^0-9]’ matches any non-digit)
-
-
Extended matching
-
Matches substrings within a larger string
-
Begin (^) and end ($)
-
^ matches the start of a string
-
$ matches the end of a string
-
Example: ‘^error’ matches lines starting with “error”
-
-
\d matches any one digit
-
r{k} matches exactly k copies of r
-
r+ matches 1 or more copies of r
-
-
-
HW code
Section titled “HW code”Question 1: Select all statements which are true about the type-checker program you wrote for HW4*:
-
It executes a program in order to determine its type → False
-
It uses several mutually-recursive functions in order to handle several different sorts of programs → True
-
It mutates its arguments in-place → False
-
Its input (the AST) contains no type information at all (e.g., type annotations in function and variable definitions) and thus the algorithm infers types completely from scratch, with no help from the AST → False, the AST for function definition contains type information
-
When the input (AST) has a type error, the algorithm reports the type error. This is a core feature of the algorithm, not a rare edge case → False, just returns None
*These questions are phrased with respect to a complete, correct implementation, regardless of any issues in a given person’s solution
Question 2: Recall that the type-checker consists of two core functions: type_check_expr and type_check_defn. Which of the following best describes the type of type_check_defn? (Note: for improved readability, assume the type Context is defined to be HashTrieMap<String, Type>, which maps names to types. We ignore reference types for readability as well. Recall that Option<t> means “either a t or a special error value”):
-
Defn -> Context
-
Context -> Option<(Defn, Context)>
-
(Context, Defn) -> Option<(String,Type)> This one
-
(Context, Expr) -> Context
-
(Context, Defn) -> Defn
Question 1: Recall the 6 usability questions (given):
-
Who are the users of the programming language?
-
What are the programmers’ goals?
-
What is the context of use?
-
How effective are programmers in achieving their goals?
-
How efficient are programmers in achieving their goals?
-
How satisfied are the programmers?
For a given passage, mark which questions are answered and which are not. Underline and number the places in the text where the question is addressed. The first three questions relate to defining the usability problem and the last three relate to evaluating a potential solution. Thus, the first three are typically described via goals and the last three through evaluation or similar concepts.
Passage A:
“Our design goal is to support professional programmers (1) working on
low-level systems software (3) in their goal of writing memory-error-free
programs (2). We measure the percentage of functions they write which are
memory-error-free (4)”
(5) (6) not mentioned
Passage B:
“Our design goal is to support comic illustrators (1) working on serial art monographs on contract basis (3) in writing scripts that generate storyboards (2). We will interview the artists to determine their feelings about their experience (6). During interviews, we will ask them how the time required to develop a storyboard varied when they used code vs. when they did not (5).”
(4) not directly measured
Passage C:
“Our design goal is to support first-year undergraduate computer science
majors (1) in developing proficiency with loops (2), during their formal
classroom instruction (3). We will record the percentage of homework tasks
implemented correctly (4) and the amount of time spent on each homework task
(5).”
(6) not addressed
Question 2: Given a list of questions for a Likert scale containing both
positive and negative-keyed questions, identify which questions are
positive-keyed and which are negative-keyed. For practice, you can try this
exercise on the System Usability Scale:
1 I think that I would like to use this system frequently 👍
2 I found the system unnecessarily complex 👎
3 I thought the system was easy to use 👍
4 I think that I would need the support of a technical person to be able to use this system 👎
5 I found the various functions in this system were well integrated 👍
6 I thought there was too much inconsistency in this system 👎
7 I would imagine that most people would learn to use this system very quickly 👍
8 I found the system very awkward to use 👎
9 I feel very confident using the system 👍
10 I needed to learn a lot of things before I could get going with this system 👎
Question 3: In one sentence, describe what differentiates a Likert scale from any other set of Likert-type questions.
Likert scale refers to a group of related questions that together measure a single underlying construct, while Likert-type questions are just individual statements with scale responses.
Question 4: Textbook exercise 11.1 (we would only test the same functions you developed in HW5)
pub fn agreement_to_score(a: &Agreement) -> i32 {
match a {
Agreement::StronglyDisagree => -2,
Agreement::SomewhatDisagree => -1,
Agreement::Neither => 0,
Agreement::SomewhatAgree => 1,
Agreement::StronglyAgree => 2,
}
}
pub fn index_to_key(i: i32) -> i32 {
match i {
i if i % 2 == 0 => 1,
i if i % 2 == 1 => -1,
_ => unreachable!(),
}
}
pub fn acquiescence_bias(data: &[Agreement]) -> f64 {
data.iter().map(agreement_to_score).sum::<i32>() as f64 / SURVEY_LENGTH as f64
}
pub fn score(data: &[Agreement]) -> f64 {
data.iter()
.enumerate()
.map(|(i, a)| agreement_to_score(a) * index_to_key(i as i32))
.sum::<i32>() as f64
/ SURVEY_LENGTH as f64
}
Case Studies (+ gender, disability, natural language)
Section titled “Case Studies (+ gender, disability, natural language)”Question 1
Section titled “Question 1”Recall the GenderMag method for assessing gender inclusiveness bugs in software
designs.
Recall that GenderMag analyzes the following facets of users (in our case,
programmers):
-
Motivation
-
Information-Processing Style
-
Computer Self-Efficacy
-
Attitude Toward Risk
-
Learning by Process vs. Tinkering
Each of the following 5 ideas is an example of how one might attempt to design a PL for inclusion on one of the facets. Match the ideas with the facets they address, as proposed in Chapter 13:
-
Develop instructional materials which highlight practical applications of PL features
- Motivation
-
Develop a documentation system for your PL where the documentation can be organized in several different ways for presentation, e.g., both selective detailed information for an individual function or object, as well as comprehensive information about a larger aspect of the language (or software written in that language, such as its standard library)
- Information-Processing Style
-
Provide error messages which are as infrequent, encouraging, and actionable as possible
- Computer Self-Efficacy
-
Develop a type system which rules out as many errors as possible before runtime
- Attitude Toward Risk
-
Provide a means for immediate interactive execution, but provide links to systematic documentation in error messages
- Learning by Process vs. Tinkering
Question 2: Select all items which are examples of the design value of “continuity”:
-
In Processing syntax, variable definitions are formatted as a type, then a name, then an equals sign, an expression, and a semicolon, e.g. int myVar = 0;
-
Yes. Continuity from the left + right
-
Previous + future
-
-
In C++, angle brackets are used to represent type parameters
- No
-
In Rust, algorithms from continuous mathematics such as computing symbolic derivatives can be implemented using an enum for polynomials
- No. Rust enums are pulled from Haskell’s ADTs which is from discrete maths
-
In FLOW-MATIC, English-language syntax is used whenever possible
- Yes. Continuity from the left. Grace Hopper chose English to appeal to laymen
Question 3:
Suppose the text of a program written in C is sent directly to a standard off-the-shelf screen reader without additional processing (e.g. the programmer is blind). Select the option which best describes the problem with this approach:
-
Two programs with different meanings might be impossible for the programmer to tell apart (THIS)
-
The screen reader will not read aloud details of whitespace such as indentation levels, which are significant to program meaning in this language
-
The screen reader will not read aloud punctuation
Question 4:
For each of the following, select whether it is more an example of verbosity vs. an example of complexity (only select one in each example):
-
Java programs frequently include two extra methods called getters and setters for each field (data member) of a class = Verbosity
-
COBOL has hundreds of keywords = Verbosity
-
In C++, the expression reinterpret_cast<int*>(x) is substantially longer to type out that its equivalent from C, which is written (int*)x = Verbosity
-
A 100% comprehensive understanding of the borrowing rules for Rust requires not only an understanding of the WOoRM rule, but an understanding of Clone, Copy, moves, variable scopes, and slices = Complexity
Question 5:
Which of the following best describes how code differs from other typed text, for the purposes of keyboard ergonomics?
-
People who write code often spend hours each day writing it
-
Programming is a potentially emotional process, and stress can exacerbate repetitive strain injuries for some people
-
Programs have a formal semantics
-
Code (in most widely-used programming languages) contains a disproportionate amount of punctuation, which is more difficult to type than other characters THIS ONE
Question 6:
The success of a PL design cannot be assessed without an understanding of its target audience. For each of the listed programming languages discussed in this course, match it with the term that best describes the audience intended by its designers
-
FLOW-MATIC: Businessmen and admirals
-
Rust: Systems programmers
-
Processing: Media artists (such as visual artists)
-
Torino: Visually-disabled children aged 7-11
-
Randomo: This language was specifically not designed for production use. It is only intended to be used in research, as a point of comparison for other languages
-
Twine: Casual developers of interactive fiction games