CS 2223: Algorithms
- Notable Challenges
- Closed-form formula for the sum of the first n cubic numbers
- Defective binary search for sorted array
- A sorted, ascending array of exactly 2^n integers from 1 to 2^n
- Closed form formula, p(n), for the success rate of confirming that a randomly selected integer from 1 to 2^n is found by the defective binary search algorithm
- Attempt
- Divide by half, even-positioned numbers will all be checked but one, odd-positioned numbers will be all unchecked but one
- p(n) = ½
- p(o) = 2^(1-n)
- p(e) = 1-2^(1-n)
- Fewest number of comparisons to determine k largest integers in an unordered array containing N values - Naive approach - Create a max-heap that contains the first k integers in the array - From index k + 1 to N - 1, try to insert the element there into the heap - Optimized approach for k = 2 - Single elimination tournament
- Closed-form formula for the sum of the first n cubic numbers
- Every round/comparison, one number is eliminated
comparisons to find the largest number
- Have to remembers all losers to the winner → candidates for second largest
number spot
- But cannot determine the winners from the beginning → Have to remember every single match
- Space complexity:
- The number of candidates for the second spot equals to how “deep” the
tournament goes because that is equal to how many competitors have lost to the
winner →
candidates - Assume that N is a power of 2
- The number of comparisons is
- The number of comparisons is
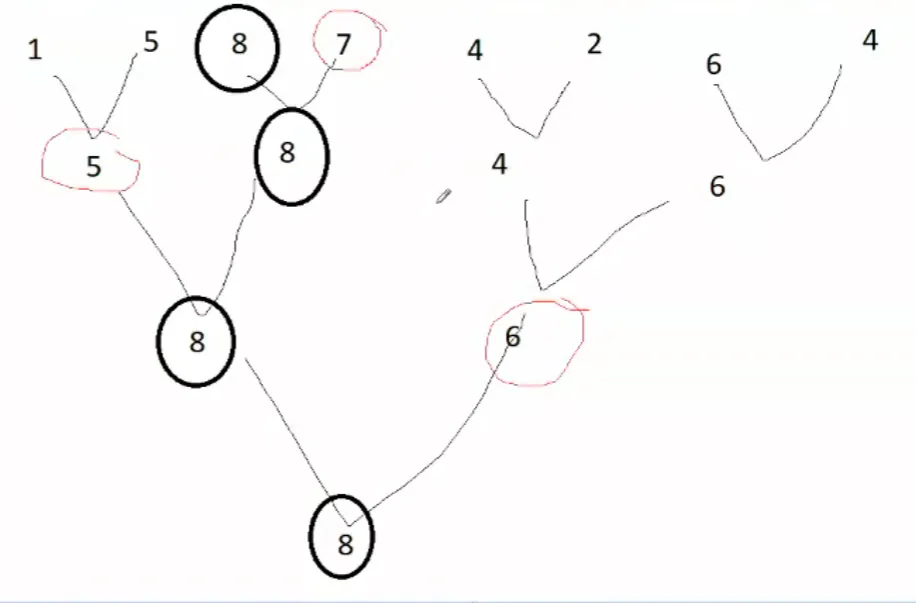
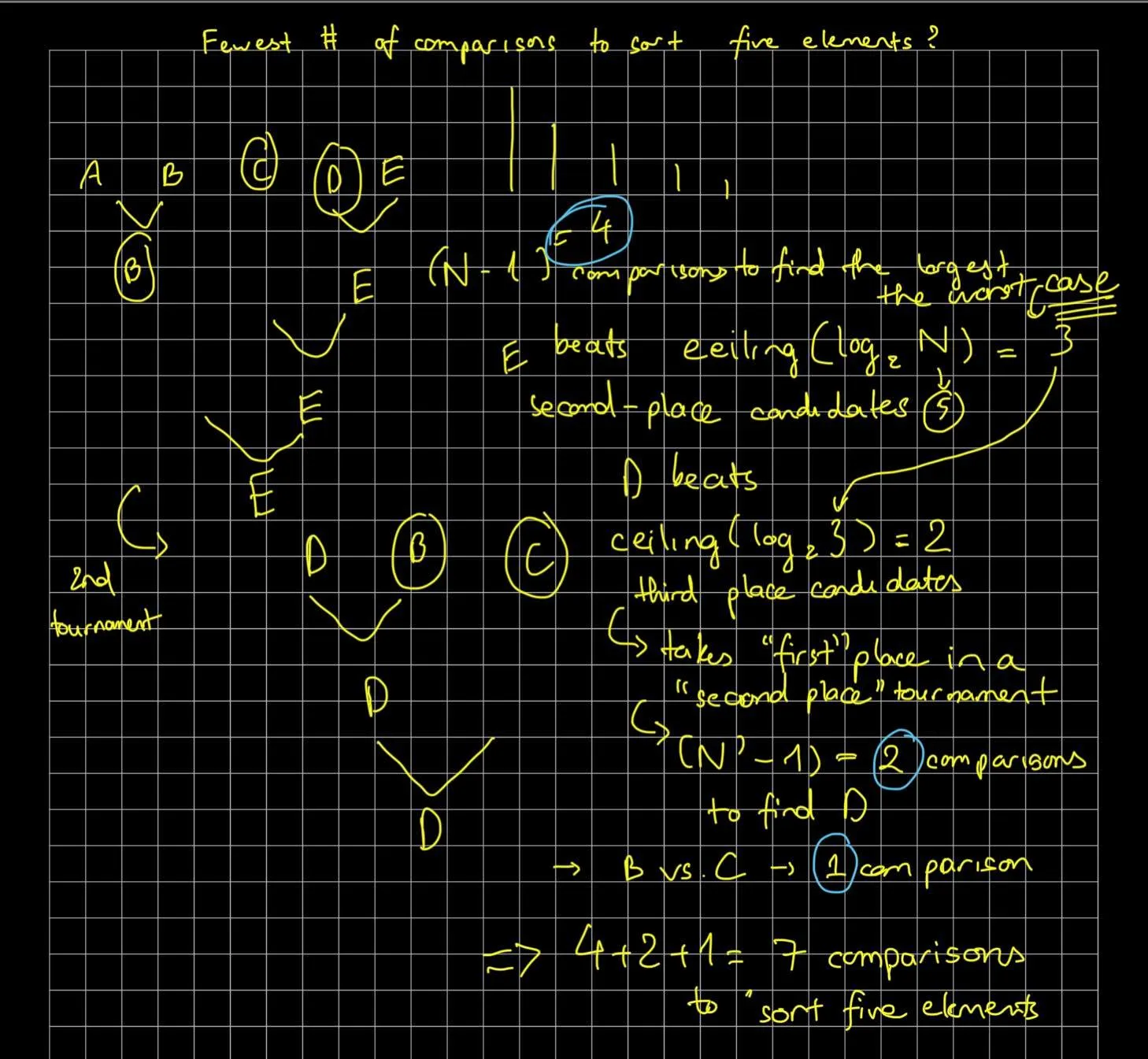
- Given 5 values A, B, C, D, E, what is the least number of comparisons you need to place these five values into ascending order?
- Based on Dijkstra’s two-stack algorithm to process infix expressions with full
parentheses, devise a one-stack solution to compute the values of postfix
expressions
- Infix (1 + ((2+3) * (4*5)))
- Postfix 1 4 5 * 2 3 + * +
- Attempt
- Value → push onto stack
- Operator → pop as many values as needed by the operator off the stack and push the value of the operation formed onto the stack
- Approach end → last value on stack is the result
- Provide an implementation of the API of a fixed-capacity stack of up to 63 bits, where you could push values of 0 or 1, and pop off the most recently pushed bit
- Single Spur Problem: You are given a train track arrangement with an incoming
track containing (from left to right) cars 1, 2, 3, …, N. A single spur can
contain up to N cars, and a single outgoing track. What is the most number of
permutations that you can achieve on the outgoing track?
- Mar 17
- Given the 10 base-10 digits (0, 1, 2, 3, 4, 5, 6, 7, 8, and 9) can you construct a mathematical expression solely of addition that produces the value 100?

- Since the only way we can bring up 45 to 100 is through concatenation and concatenation only differs the sum by an amount divisible by 9, the altered sum by using concatenation will always be divisible by 9, which 100 does not. Thus, it is impossible.
- Given a reference to the first node in a linked list, L, that contains N
elements. Traverse the linked list ONCE. The result is to split L into two
lists, L and back, where L is updated to only contain the first floor(N/2)
elements (in their original order) and back contains the remaining N -
floor(N/2) elements (in their original order).
- 2 pointers: slow and fast
- Principle idea: fast goes twice as fast as slow so in the end, the slow pointer will point at the middle of the linked list
- Check two nodes forward before advancing fast by two, advance slow by one afterward
- In an array, a repeater, is a value which appears more than n/2 times in an
array of size n. What if you had a heap of size n stored in an array and you
were told that there is a repeater value in the heap. Can you guarantee that
one of the leaf nodes is a repeater value? Either prove or provide a counter
example.
- In a binary heap, a parent node at kth index can find its children at 2k and 2k + 1.
- Write an in-order iterator for a Binary Search tree that uses only O(log N) extra storage, rather than the keys() method that requires O(N).
- Sample exam questions
- There is an alternate notation known as postfix notation. The above equation would be represented as “1 4 5 * 2 3 + * +”. As its name implies, in postfix notation the operator comes after the arguments. Based on the structure of Dijkstra’s algorithm, devise a one-stack solution to compute the value of this sequence of tokens
- Write pseudocode for a function that takes a Stack of elements and modifies
the stack so that its bottom two elements are swapped with each other
- Pop each stack A’s element and push into a stack temp
- When A is empty, pop 2 elements from temp
- Push them into temp again with the order switched
- Pop from temp back into A again until temp is empty
- How would you implement a contains method that determines whether an element
is to be found in the Bag. Evaluate the performance of the method in terms
of N, where N is the number of elements in the Bag.
- Duplicate pointer to first item
- While pointer is not null, traverse and compare until found or can’t be found
- O(N) performance
- A researcher proposes to design a data type which consists of a linear
linked list of nodes, each of which stores an array of K individual
comparable items in sorted order. Only the last node in the list may contain
fewer than K items. This data type will offer the following operations: -
insert (v) — insert v into the collection - remove (v) — remove v from the
collection - contains(v) — check whether collection contains v
He claims he needs ~ log(N*K) performance for determining whether the collection contains a given element.
From this idea, there are several possible questions to ask:
- Start with the contains method. Come up with an algorithm for this method. What is the performance of your method?
- Is his performance claim correct?
- Write pseudo code for insert.
- Write pseudo code for remove.
- You have an array of N elements in sorted order. You wish to use Binary Array Search to determine the rank for a target value, x. The only problem is, the compareTo(a, b) operator will lie exactly one time during your search. This function returns 0 if the values are the same, a negative number if a < b, and a positive number if a > b.
- You have an array of N elements in sorted order. You wish to use Binary Array
Search to determine the rank for a target value, x. The only problem is, the
compareTo(a, b) operator will lie exactly one time during your search. This
function returns 0 if the values are the same, a negative number if a < b,
and a positive number if a > b. Complete the following skeleton algorithm (in
pseudo code or Java code) and then identify the fewest number of less requests
that your algorithm needs to accurately determine the rank of x.
- (a) Design your algorithm in Java or pseudo code
int rank (Comparable a, Comparable x) { // fill in here... }
- (a) Design your algorithm in Java or pseudo code
- (b) Compute the fewest number of less requests needed in terms of N where N is the number of elements in the Comparable[] array.
- In a binary tree with N nodes, there must be at least n/2 leaf nodes.
- False, for skewed binary trees, the property breaks
- Interview challenge
- There are five cups placed on a table upside down in a line. Let’s label them “A B C D E”. Under one of the cups is a terrified squirrel. Your goal is to find the squirrel under the following restrictions. You can lift up exactly one cup at a time. If you find the squirrel you win! If not, then you put the cup back in its original position, upside down again, turn around, and wait for five seconds. When you are turned around, the squirrel has just enough time to move to one of the cups that is a direct neighbor to the one it was hiding underneath. For example, if the squirrel had been hiding in a cup “C”, it could move to cups “B” or “D”. If it had been hiding under cup “E”, then it can only move to cup “D”. Devise an algorithm that will find the squirrel after picking up a finite number of cups
- A plane with N seats is ready to allow passengers on board, and it is indeed a full flight; every seat has been purchased. Each person has a boarding pass that identifies the seat to sit in. When the announcement is made to board the plane, all passengers get in line, in some random order. The first person to board the airplane somehow loses his boarding pass as he enters the plane, so he picks a random seat to sit in. All other passengers have their boarding passes when they enter the plane. If no one is sitting in their seat, they sit down in their assigned seat. However, if someone is sitting in their seat, they choose a random empty seat to sit in. My question is this: What is the probability that the last person to take a seat is sitting in their proper seat as identified by their boarding pass?
- You have three pair of colored dice — one red, one green and one blue —
and for each colored pair of dice, one of the die is lighter than the other.
You are told that all of the light dice weigh the same. And also you are
told that all of the heavy dice weigh the same. You have an accurate pan
balance scale on which you can place any number of dice. The scale can
determine whether the weight of the dice on one side is equal to, greater,
or less than the weight of the dice on the other side.
- Task: You are asked to identify the three lightest dice from this collection of six dice.
- Obvious Solution: You could simply conduct three weight experiments.
- Put one red die on the left pan, and the other red die on the right pan — this will identify the lighter red die
- Put one green die on the left pan, and the other green die on the right pan — this will identify the lighter green die
- Put one blue die on the left pan, and the other blue die on the right pan — this will identify the lighter blue die This takes three weighing operations.
- Challenge: Can you locate the three lighter dice with just two weight experiments, where you can place any number of dice on either side of the pan
- Write a method for a Binary Search Tree that returns the Key for the node
that has the greatest depth: that is, the node that is the farthest from the
root node. If there are multiple nodes that share this same distance, then
print any one of them.
- No nodes: return key at root
- Only left/right node: return maxDepth(node.left/node.right)
- Two nodes: return maxDepth of whoever has larger depth
- Java Basics
- Formatted output static void printf(String f, … )
- In simplest forms, printf() takes two arguments
- A format string that describes how the second argument is converted to a string for output
- Format string
- ”…%<field width><.a>[d | f | s]…”
- Conversion codes
- d (decimal), f (float), s (String)
- Field with
- the number of characters in the converted output string
- The period is followed by the number of digits to put after the decimal points for a double value or the number of characters to take from the beginning of a string for a String value
- The format string is then replaced by the converted value and output to stdout, along with the rest of the first argument
- stdin
- Program consumes values as it reads them → Cannot recover the values once read (StdIn library static methods. using String[] args is persistent)
- Binary Array Search
- Determine whether a sorted array contains a target item
- Can find the indexes of the leftmost and rightmost occurrences of the target assuming it has duplicates near the middle of the array
- Can find max element recursively
- Idea
- Search for the target item by keeping track of a range within the array in which the target must be if it exists
- Initially, the range is the entire array
- The range is shrunk by comparing its central element to T and discarding half the range
- Continue the process until T is found or the range is empty
- For an N-element array, the search uses
comparisons - Implementation for ascending array:
boolean contains(int[] A, int target) { int lo = 0; int hi = A.length - 1; // KEY #1 while (lo <= hi) { // KEY #2 int mid = (lo + hi) / 2; // KEY #3 int rc = A[mid] - target; // TRICK for <, =, > if (rc < 0) { lo = mid + 1; // KEY #4 } else if (rc > 0) { hi = mid - 1; // KEY #5 } else { return true; } } return false; // KEY #6}- Questions
- Is the while loop guaranteed to terminate?
- Presume that the range now contains only one element, lo and hi, and mid now point to the same element. Whatever the target, the consequences guarantee that the next iteration will not happen due to the break condition.
- How many times will the while loop execute?
- Given any N, the while loop will run
times
- Given any N, the while loop will run
- Can you prove this code is correct?
- Is the while loop guaranteed to terminate?
- Optimization
- Check less than first, then greater than, then equal in an ascending array
- Because the middle index is floored, it lies in the lower half. Thus, a randomly chosen target would be larger than the middle element statistically
- The chance for these two to be equal would be the lowest so the equality test needs to be last
- Replace floor division of two integers with bit operations
- avg = (x & y) + ((x ^ y) >> 1)
- Check less than first, then greater than, then equal in an ascending array
- Expansion
- How many copies of a target value exist in a sorted (ascending) array?
Once the search finds its first occurrence, latch onto it and sweep the lower half and upper half:
- How many copies of a target value exist in a sorted (ascending) array?
if (rc < 0) { lo = mid + 1; // KEY #4} else if (rc > 0) { hi = mid - 1; // KEY #5} else { // Account for first occurrence count++; // Search lower half for similar values int loSearch = mid - 1; while (loSearch >= lo && A[loSearch] == target) { loSearch--; count++; } // Search upper half for similar values int hiSearch = mid + 1; while (hiSearch <= hi && A[hiSearch] == target) { hiSearch++; count++; }}- Downside
falls apart when the whole array contains all duplicates of the target, which would make the time complexity to be
- Key idea
- Not stop searching when == condition is reached, instead performing two more binary searches, one for the left edge, one for the right edge
- Algorithm
- A finite, deterministic and effective problem-solving method suitable for implementation as a computer program
- Approach computational structures with a scientist’s mindset
- Make observations
- Form hypotheses
- Develop testable predictions
- Gather data to test predictions
- Develop general theories
- Key tents of the scientific method
- Experiments must be reproducible
- Hypotheses must be falsifiable
- Can’t conclude a hypothesis is absolutely correct, only validate that it is consistent with observations
- Analyzing algorithms is based on counting the number of times key operations occur in terms of the input size (loops, comparison, swapping array elements,…)
- Mathematical model to describe the running time of any program - The toral
running time of a program is determined by two primary factors - The cost of
executing each statement (specific of the computer, the compiler, and the
OS) - The frequency of execution of each statement (specific of the the
program and input) - To ignore insignificant terms (substantially simplify
mathematical formulas), use tilde notation (~) — approximation - We write
to represent any function that, when divided by approaches 1 as N grows - Commonly encountered order-of-growth functions - Constant: 1 - Logarithmic: - Linear: - Linearithmic: - Quadratic: - Cubic: - Exponential: - The cost model should include operations that fall within the inner loop (operations that get repeated based on the input size)

- Amortized analysis
- A method of analyzing the costs associated with a data structure that averages the worst operations out over time
- Example
- Pushing an element onto a stack when it is full doubles the size of the underlying array
- Total cost over lifetime:
- Average cost for 1 push:
- Half-full principle
- Empirical studies have shown that doubling the size of the inventory when it is full or shrinking the size by half when it is 25% full is most effective when you have no idea how many items are going to be added
- Big O notation
- Stands for “order of growth” and used to evaluate the performance of an algorithm independent of the programming language
- Relates to the upper bound of whatever cases you are interested about
(best, average, worst)
- Upper bound on the growth rate of an algorithm’s time complexity as the input size increase
- We are interested in determining the number of “fundamental machine operations” based on the problem size N for the worst case of an algorithm - However, this is incredibly hard - Assume that every key operation within the language we work with is a constant number of individual machine operations - Focus on specific key operations and count how many times they are invoked for a problem of size N - The total number of machine operations is at least this amount
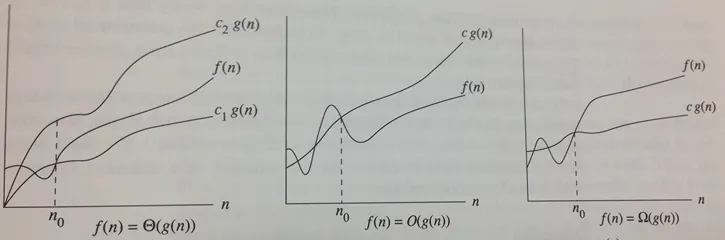
- Lower Bound Ω(g(n)) (best case) — after a certain point, f(n) is always greater than c1*g(n)
- Upper Bound O(g(n)) (worst case) — after a certain point, f(n) is always smaller than c2*g(n)
- Tight Bound Θ(g(n)) (average case) — after a certain point, f(n) is bracketed on the bottom by c1*g(n) and on the top by c2*g(n)
- Usage
- Analyze running time performance
- Count the number of key operations
- Space utilization
- Data Structures
- Data structures are just structures into which data is stored. When you wrap them in a behavioral API, they become data types
- Euclid’s Algorithm (Sedgewick)
- Determine the GCD of two nonnegative integers, a and b
- Idea
- If a is 0, the answer is b
- If not, divide b by a and take the remainder r
- GCD(a, b) = GCD(b, r)
- The bag data structure
- A collection where removing items is not supported
- Purpose
- Allow clients to collect items and iterate through all the collected items
- The order of iteration is unspecified and unimportant to the users
- Examples: calculating the average or standard deviation of a set of numbers
- Dijkstra’s Two-Stack Algorithm
- Infix mathematical expression evaluation with two stacks
- Initialize two stacks, one for operands and one for operators.
- Read the expression from left to right.
- If the token is a number, push it onto the operand stack.
- If the token is an operator, push it onto the operator stack.
- If the token is a right parenthesis, pop the top operator and two operands from the stacks, apply the operator to the operands, and push the result onto the operand stack.
- Repeat steps 3-5 until the end of the expression is reached.
- The final result is the top element of the operand stack.
- Example: (3 + 4) * 5
- Infix mathematical expression evaluation with two stacks
- Linked lists
- A linked list is a recursive data structure that is either null or a reference to a node that stores some item and has a reference to a linked list
- Maintain a first and last pointer to properly implement the queue data type
- Inserting/removing at the start is O(1)
- Circular queue
- first = (first + 1) % a.length;
- Useful for embedded systems — limited memory
- O(1) for all operations
- Sorting methods
- Key factors
- sort(Comparable[] a)
- less(Comparable v, Comparable w)
- exch(Comparable[] a, int i, int j)
- show(Comparable[] a)
- isSorted(Comparable[] a)
- Cost model
- Count comparisons and exchanges
- For sorting algorithms that do not use exchanges, count array accesses
- Key factors
- Selection sort
- Find the smallest item in the array and exchange it with the first entry (itself if the first entry is the smallest). Then find the next smallest item and exchange its place with the second entry. Continue until the entire array is sorted
- In short, repeatedly select the smallest remaining item
- Each exchange puts an item into its final position →
exchanges - Use
comparisons to find the smallest among unordered elements → comparisons - Properties
- Running time is insensitive to input
- Takes the same time to sort a sorted array or an array with all keys equal as a random one
- Data movement is minimal
- Running time is insensitive to input
- Insertion sort
- Consider the first element in the array as being in a sorted subarray. Then consider if the next element is less than the first. If it is, swap. After that, the two elements are now sorted. Do the same for the next elements, pair-wise comparison, and swapping until you put an element into its place in the sorted subarray.
- Worst case — Descending array
- For every element at
index considered, it takes comparisons and exchanges to take it to the left end of the sorted subarray comparisons exchanges
- For every element at
- Best case — Sorted array
comparisons exchanges
- Properties
- Very efficient for small arrays or partially sorted arrays
- Merge sort
- Divide the unsorted array into two halves, sort (recursively) and merge them
- Time complexity:
- Auxiliary space:
- Abstract in-place merge
- Takes two input arrays
- Successively choose the smallest remaining item from the two
- Add to output array
- Algorithmic implementation of merge() - Assume that the two halves are sorted - Copy a into aux - Place 1 pointer k at a[lo], 2 pointers i and j at aux[lo] and aux[mid + 1] - If left half is exhausted, take from the right and advance k and j - Do the same for right half - If aux[j] < aux[i], advance take from the right and advance j - Else, take from the left and advance i
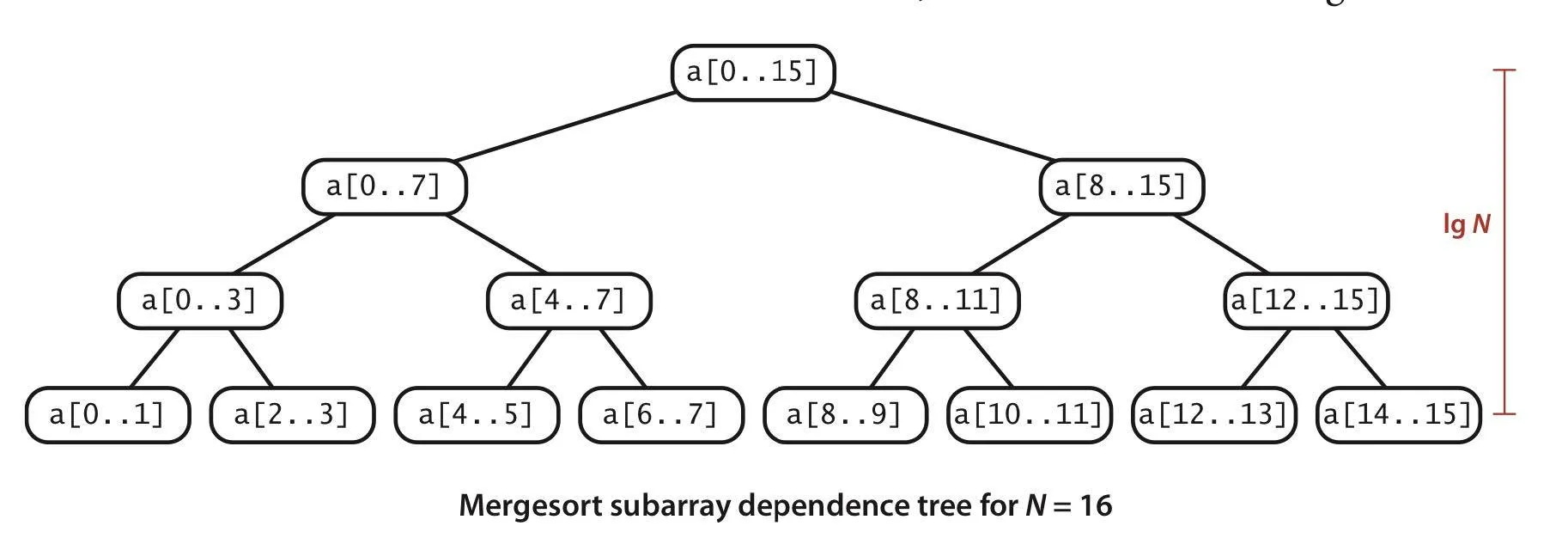
- Like tournament sort, for
, the tree has levels - For
from 0 to as the level - As
goes up by 1 - The number of subarrays at the
‘th level doubles - The length of each subarray
halves - The number of compares at most required for the merge of each subarray
halves
- The number of subarrays at the
- Thus
total compares for levels - Total
- As
- Optimization
- Use insertion sort for small subarrays
- Skip merge() if a[mid] <= a[mid + 1]
- Eliminate the copy to the auxiliary array
- Botton-up merge sort
- A sequence of passes over the whole array, doing sz-by-sz merges starting with sz equal to 1 and doubling it after each pass
- Can be implemented to sort linked lists
- No compare-based sorting algorithm can guarantee to sort
items with fewer than compares - Merge sort is an asymtotically optimal compare-based sorting algorithm
- Heap sort
- Turn an arbitrary array of values into a heap (heapify) and then exchange largest into proper place
- Convert arbitrary array into heap
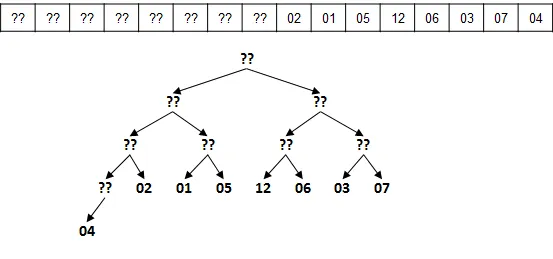
- Going from left to right, use sink() to make subheaps of increasing size beginning from 2 (first element that has a child is at floor(N/2))
- Seems to take (N/2) (N/2 elements) * (logN) (worst case performance of sink()) but is really 2N, because you cannot continually experience the worst case as you work backwards
- Exchange largest into proper place
- Divide array into sorted and unsorted (heap) region
- Swap largest element with the last element in the heap and decrease the number of elements in array (reduce size of unsorted region)
- Restore heap using sink() at the position of the swapped out element
- Worst case performance of sink() * N elements = O(N * logN)
- Time complexity: O(N*logN)
- Space complexity: O(1) (sort input array in-place)
- Quick sort
- Time complexity: Θ(N*logN) on average case, O(N^2) on worst case
- Space complexity: Θ(logN) on average case, O(N) on worst case
- Partition an array into two subarrays, then sort the subarrays independently
- Symbol table
- An abstract mechanism where we save a value to be retrieved later by
specifying a key
- E.g: dictionaries, indices
- Supports inserting key-value pair into the table and search for the value associated with a given key
- Null keys
- Keys must not be null
- Null values
- No key can be associated with the value null, because we associate null with keys not in the table
- Deletion
- Lazy deletion
- Associate keys in the table with null, and remove all such keys at a later time
- Eager deletion
- Remove the key from the table immediately
- Lazy deletion
- Hashing
- Hash function transforms search keys into array indices
- Ideal hash function
- Consistent — equal keys must produce the same hash value
- Easy to compute
- Uniformly distribute the keys
- For integer key types
- Modular hashing
- Choose array size M to be prime (to be optimal), and for every positive integer key k, computer k % M
- Modular hashing
- For floating-point numbers
- For keys between 0 and 1, we multiply by M and round to the nearest integer
- For strings
- Modular hashing also works
- Treat the string as a N-digit base-R integer
- Modular hashing also works
- Collision resolution
- Different keys may hash to the same array index → have to resolve
- Separate chaining
- For each of the M array indices, build a linked list of the key-value pairs whose keys hash to that index
- With N keys and M lists, the average length of each list is always N/M
- According to classical probability, the probability that the number of keys in a list is within a small constant factor N/M is extremely close to 1
- Easy to implement and the fastest where key order is unimportant
- Open addressing — relying on the table’s empty entries to resolve
collision
- Simplest method is linear probing
- When there is a collision, we check the next entry in the table
- For searching, hash the key, check whether the search key matches the key at that table index and continue incrementing (and wrapping back to the start if we reach the end) until we find the search key or an empty entry
- The performance depends on the ratio N/M
- N key-value pairs
- M-sized hash table
- Different from N/M of separate chaining
- Load factor — how full the table is
- Ensure load factor is between ⅛ and ½
- For deletion, find the location of the target, rehash all keys after it and put them back into the table
- Simplest method is linear probing
- An abstract mechanism where we save a value to be retrieved later by
specifying a key
- Priority queues — abstract data type
- Each element in a priority queue has an associated priority. In a priority queue, elements with high priority are served before elements with low priority
- Representation
- Unordered array — lazy approach
- Insert: O(1)
- Remove maximum: O(N)
- Ordered array — eager approach
- Insert: O(N)
- Remove maximum: O(1)
- Linked list
- Unordered array — lazy approach
- Two operations
- Remove the maximum: O(logN)
- Insert: O(logN)
- Heap
- The binary heap is a data structure that can support the priority queue
- A priority queue can be implemented using a heap
- A binary tree is heap-ordered if the key in each node is larger than or equal to the keys in that node’s two children (if any)
- A binary tree has heap-shape if each level is filled “in order” from left to right and no value appears on a level until the previous level is full
- Represent complete binary trees sequentially within an array by putting the nodes in level order (BFS)
- By restraining the partial ordering vertically on the heap-ordered binary tree but not horizontally, it reduces the overhead of full ordering but still yields performance benefits
- Implementation of heap - A collection of keys arranged in a complete heap-ordered binary tree, represented in level order in an array (not using the first entry)
- The binary heap is a data structure that can support the priority queue
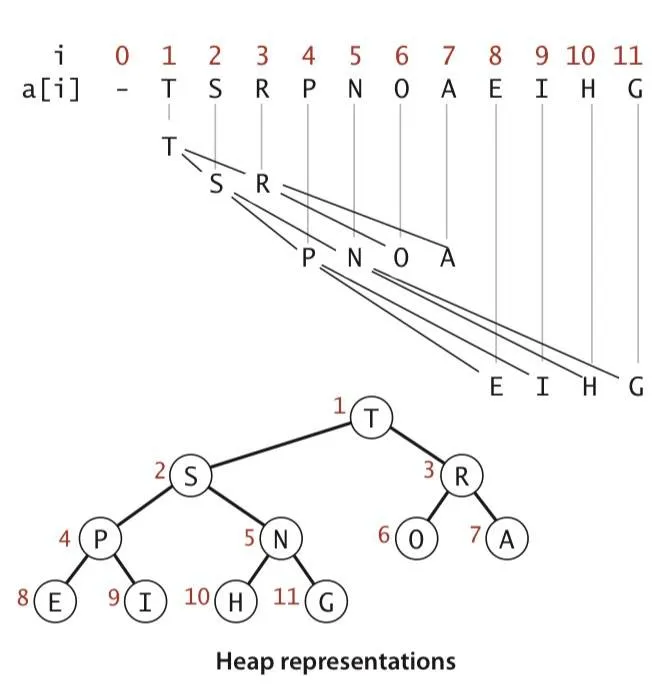
- Parent of node at kth is at floor(k/2)
- Two children of node at kth are at 2k and 2k + 1
- Move up the tree with floor(k/2)
- Move down the tree with 2k and 2k + 1
- Height of tree floor(lgN)
- Operations
- Inserting
- Bubble up: insert to the last position, swap with parent if larger to maintain invariant
- Deleting the max - Trickle down: save and return the max, swap the last element to the top, and swap this value with the larger of its two children (if they exist)
- Inserting
- Binary search trees
- Keep the keys in order → Can be used to implement ordered symbol-tables
- Every node has up to 2 nodes, left and right
- A link is either a reference to the left or right child of a node. We also use (interchangeably) the term edge.
- The height of a node is the number of edges from that node to its most distant leaf. What follows is that the height of any leaf node is zero.
- The height of a tree is the height of its root.
- The depth of a node is the number of edges from the root to that node. What follows is that the depth of the root is zero.
- Each of the keys in the left subtree n.left is guaranteed to be smaller than or equal to n.key.
- Each of the keys in the right subtree n.right is guaranteed to be larger than or equal to n.key.
- In a BST, all operations take time proportional to the height of the tree, in the worst case
- Can use preorder and (inorder or postorder) to serialize and deserialzie a tree
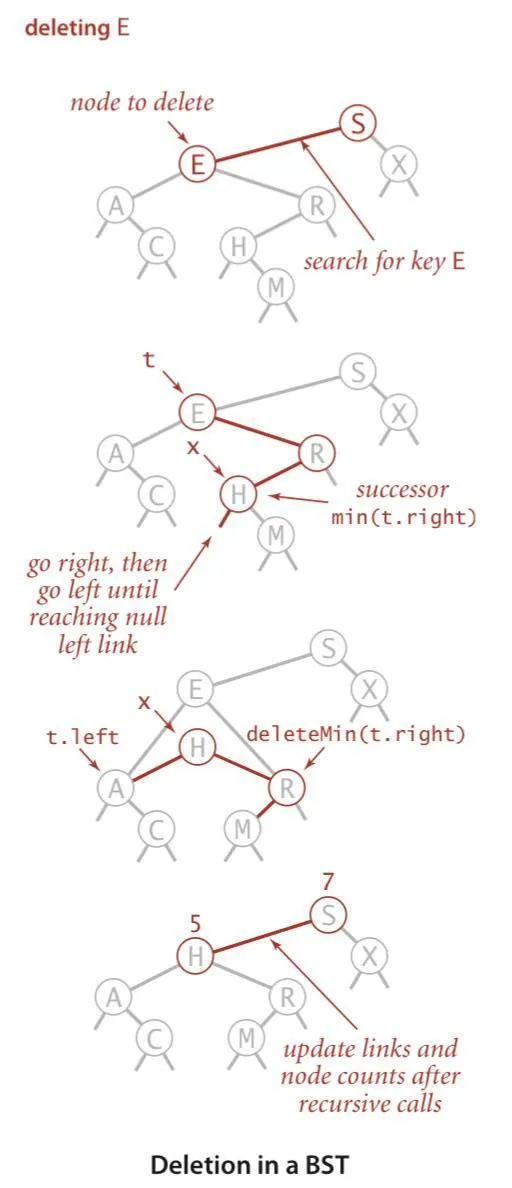
- Operations - Minimum and maximum - Move left/right until finding a null link, return current node if null link - Floor and ceiling (largest key in BST less than or equal to key) - key < key at root - floor(key) = floor(key.left) - key > key at root - floor(key) = floor(key.right) if it does not return null - key = key at root - floor(key) = key - Selection — node containing key of rank k (k keys in BST is smaller than) - root.left.N > k - rank(root, k) = rank(root.left, k) - root.left.N < k (then we already found root.left.N lesser keys) - rank(root, k) = rank(root.right, k - root.left.N - 1) - root.left.N = k - Return root - Delete the minimum/maximum - Go left until first null left link - Return that node’s right link - Deletion of a node - Same for nodes with one or no children - For nodes with two children (x) - Delete by replacing it with its successor - Because x has a right child, its successor is the min key in its right subtree - Replacing x by its successor - Save a link to the node to be deleted in t - Set x to point to its successor min(t.right) - Set the right link of x to deleteMin(t.right) - Set the left link of x to t.left
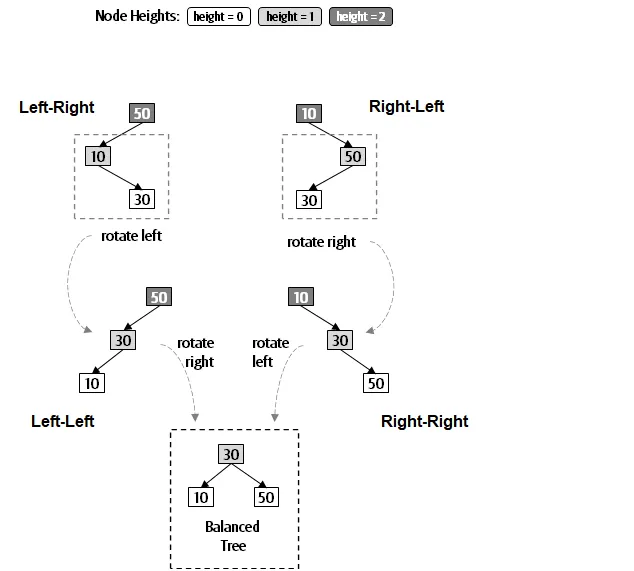
- Balanced binary tree
- An AVL tree guarantees that the height difference for any node (left - right) can only be -1, 0, and 1 if we denote the height of null as -1
- Has to balance the tree upon insertion or deletion
- Red Black trees
- AVL trees enforce a strong global property, namely, that the heights for left and right subtrees are never more than -1, 0 or 1. If you relax this restriction, you can reduce the number of rotations.
- A RedBlack tree guarantees that no path to a leaf node is more than twice as long as any other path to another leaf node. This is strong enough to guarantee the desired properties.
- RedBlack trees, therefore, allow for less compact trees, which increases the search time slightly, but it noticeably reduces the time to perform insertions and deletions.
- Traversal
- Inorder: left root right
- Preorder: root left right
- Postorder: left right root
- Graphs
- Applications
- Maps, web content, circuits, schedules, commerce, matching, computer networks. Software, social networks
- 4 most import types
- Undirected graphs (with simple connections)
- Digraphs (where the direction of each connection is significant)
- Edge-weighted graphs (where each connection has an associated weight)
- Edge-weighted digraphs (where each connection has both a direction and a weight)
- Applications
- Undirected graphs
- A graph is a set of vertices and a collection of edges that each connect a pair of vertices
- Anomalies
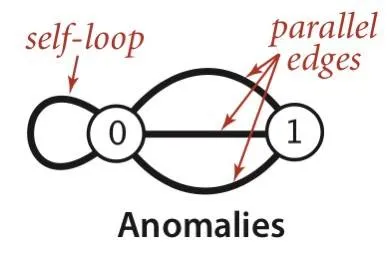
- An edge connects two vertices
- The vertices are adjacent to one another
- The edge is incident to both vertices
- The degree of a vertex is the number of edges incident to it
- A path in a graph is a sequence of vertices connected by edges
- A simple path is one with no repeated vertices
- A cycle is a path with at least one edge whose first and last vertices are the same
- A simple cycle is a cycle with no repeated edges or vertices (except the first and last vertices)
- The length of a path or a cycle is its number of edges
- A graph is connected if there a path from every vertex to every other vertex
in the graph. A graph that is not connected consists of a set of connected
components, which are maximal connected subgraphs
- A simple graph has no self-loops and parallel edges
- A complete graph has an edge between each pair of vertices
- An acyclic graph is a graph with no cycles
- A tree is an acyclic connected graph
- A forest is a disjoint set of trees
- A spanning tree of a connected graph is a subgraph that contains all of that graph’s vertices and is a single tree
- A spanning forest of a graph is the union of spanning trees of its connected components
- A bipartite graph is a graph whose vertices we can divide into two sets such that all edges connect a vertex in one set with a vertex in the other set
- A graph G with V vertices is a tree if and only if it satisfies any of the
following five conditions
- G has V - 1 edges and no cycles
- G has V - 1 edges and is connected
- G is connected, but removing any edge disconnects it
- G is acyclic, but adding any edge creates a cycle
- Exactly one simple path connected each pair of vertices in G
- The density of a graph is the proportion of possible pairs of vertices that are connected by edges → sparse/dense graphs
- Data structures to represent graphs
- An adjacency matrix
- V-by-V boolean array, with true entry in row v and column w defined as an edge between vertex v and vertex w → Space complexity too large
- An array of edges
- Using an Edge class with two instance variables of type int → Time complexity too large
- An array of adjacency lists - A vertex-indexed array of lists of the vertices adjacent to each vertex
- An adjacency matrix
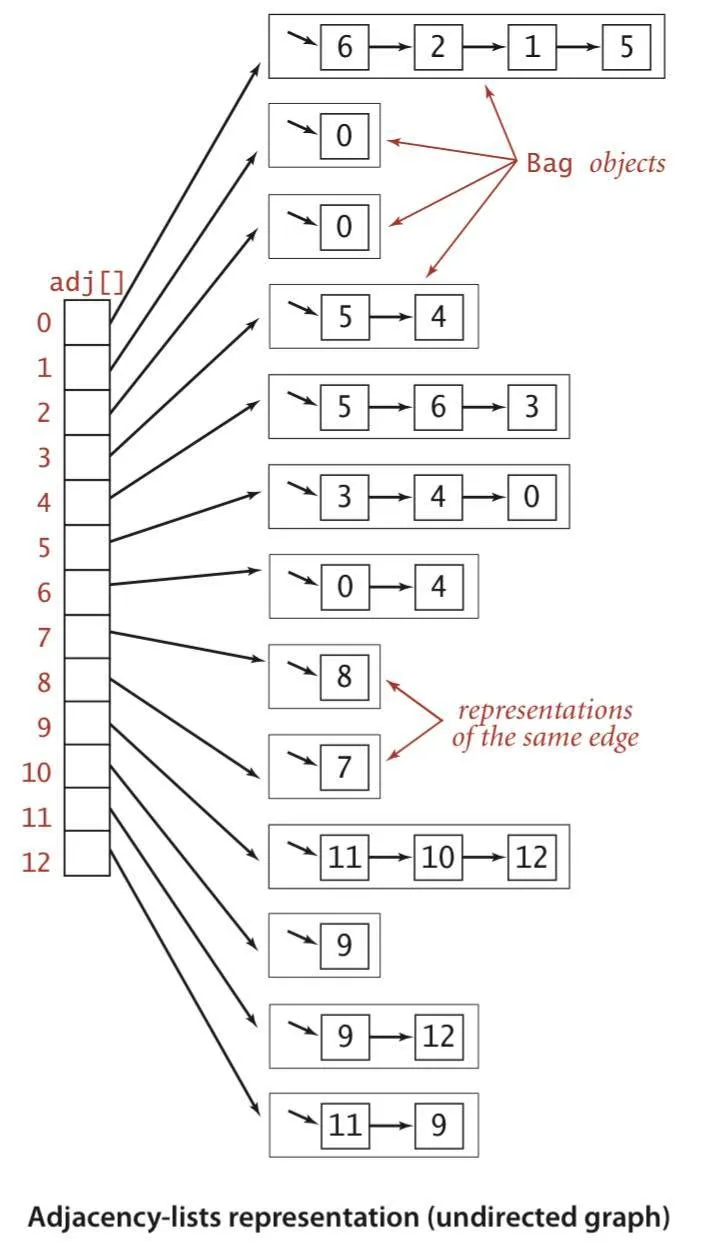
- Searching algorithms over graphs
- DFS - To visit a vertex - Mark it as visited - Visits (recursively) all adjacent and unmarked vertices - Time complexity - Visits each vertex and edge once → O(V+E)
public DepthFirstSearch(Graph g, int s) { marked = new boolean[g.V()]; this.g = g; dfs(s);}
/** Continue DFS search over graph by visiting vertex v. */void dfs(int v) { marked[v] = true; // we have now seen this vertex count++; // look into neighbors for (int w : g.adj(v)) { if (!marked[w]) { // will never dfs() on this vertex again dfs(w); } }}- Recovering path with DFS
- Record a separate one-dimensional vector edgeTo[] for each vertex that records the previous vertex in a DFS from the source vertex
- Recover the path by tracing from target vertex to source using edgeTo[] and a stack
- BFS
void bfs(Graph G, int s) { marked = new boolean[G.V()]; edgeTo = new int[G.V()]; distTo = new int[G.V()]; Queue<Integer> q = new Queue<>(); for (int v = 0; v < G.V(); v++) { distTo[v] = Integer.MAX_VALUE; } distTo[s] = 0; marked[s] = true; q.enqueue(s); while (!q.isEmpty()) { int v = q.dequeue(); for (int w : G.adj(v)) { if (!marked[w]) { edgeTo[w] = v; distTo[w] = distTo[v] + 1; marked[w] = true; q.enqueue(w); } } }}- Maintains the state of the search in a queue
- Will also find a path like DFS, but guarantees that no shorter paths exist
- Maintains distance from vertex to source in distTo[]
- Path recovery with edgeTo[]
- Time complexity
- Visits each vertex and edge once → O(V+E)
- Directed graphs
- A set of vertices and a collection directed edges. Each directed edge connects an ordered pair of vertices in a specific direction
- May have up to two different edges between the same pair of vertices
- Topological sort - Given a digraph, produce a linear ordering of its vertices such that for every directed edge uv (from vertex u to vertex v), u comes before v in the ordering (or report that doing so is impossible)
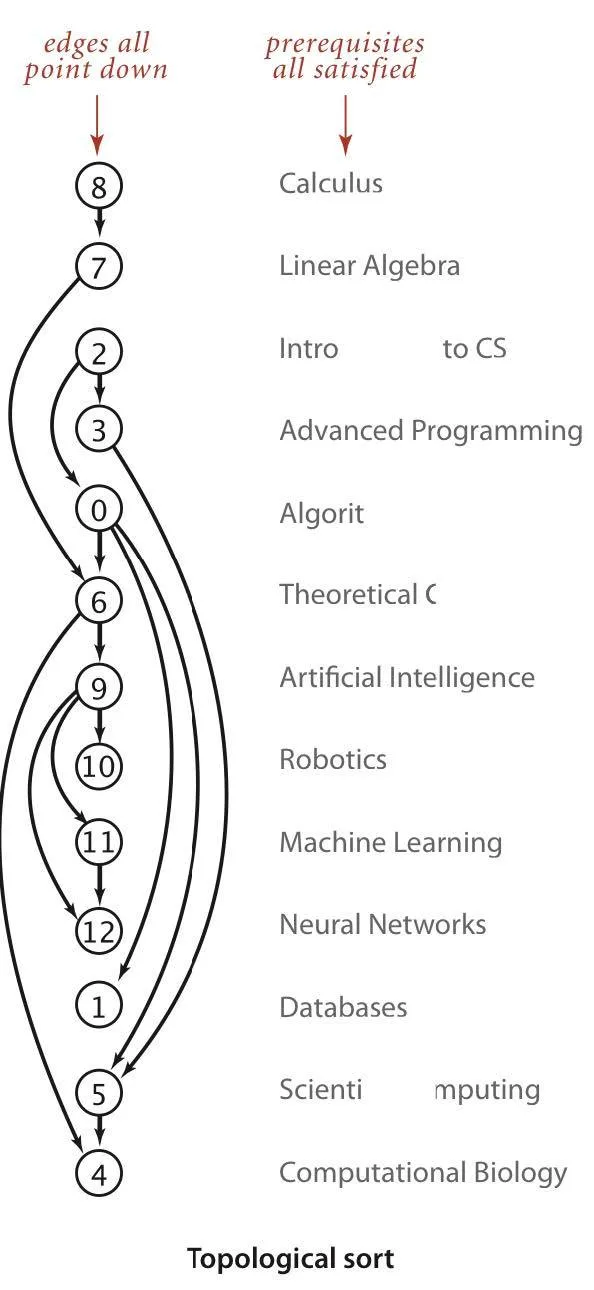
- As recursion unwinds to pop the onStack[] (refer below) vertices off the stack, it finds that those vertices are dead ends of sorts in reverse postorder → push them onto reversePost stack (DF reverse postorder)
- Applications
- Precedence-constrained task scheduling → represents a solution
- Core behavior in spreadsheet programs
- Cycles in digraphs
- If a precedence-constrained scheduling problem has a directed cycle, there is no solution
- To check for cycles — Directed cycle detection
- Use graph traversal algorithms to explore the graph and detect if there is a back edge, which connects a node to an ancestor node in the traversal tree
- If a back edge is found, then the graph contains a cycle
- Maintains a vertex-indexed array onStack[] to keep track of the current directed path from source to v using DFS
- Directed acyclic graph
- A directed acyclic graph (DAG) is a digraph with no directed cycles
- A digraph has a topological order if and only if it is a DAG
- Reverse postorder in a DAG is a topological sort
- With DFS, we can topologically sort a DAG in time proportional to V+E
- Depth-first ordering of vertices - Preorder: Put the vertex on a queue before the recursive calls - Postorder: Put the vertex on a queue after the recursive calls - Reverse postorder: Put the vertex on a stack after the recursive calls
- Weighted graphs
- Assign numeric weights to each edge representing real-world measurements
- Single Source Shortest Path (SSSP) - The shortest possible accumulated path from a designated source vertex to each other vertex in G (with non-negative edge weights) reachable from s (not by # of edges) - Similar to distTo[v] that records the shortest # of edges to traverse from vertex s to each vertex x, use an array dist[v] that records our the computer shortest path from s to each vertex x (dist[s] = 0) - Also maintains a min priority queue of vertices, with priority determined (key) by the current shortest known distance to s - Starts by setting dist[s] = 0, all other vertices to infinity - Adds s to the queue with key 0, same with all other vertices with infinity - Repeatedly select the vertex with the minimum known distance and relax all its outgoing edges
while (!pq.isEmpty()) { int v = pq.delMin(); for (DirectedEdge e : G.adj(v)) { relax(e); }}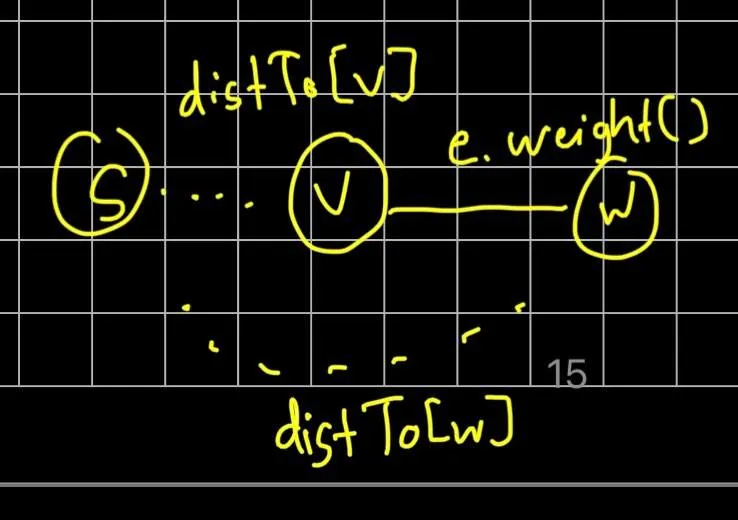
- As the algorithm relaxes edges, it updates the distance of each adjacent vertex:
void relax(DirectedEdge e) { int v = e.from(); int w = e.to(); if (distTo[w] > distTo[v] + e.weight()) { distTo[w] = distTo[v] + e.weight(); edgeTo[w] = e; pq.decreaseKey(w, distTo[w]); }}- The vertices are essentially visited in order of their shortest known accumulated path from s, eliminating vertices to be visited from the priority queue one at a time
- The algorithm terminates when all vertices have been visited
- Time complexity: O((|E| + |V|)log|V|) → More efficient on dense graphs, where the number of edges is proportional to the square of the number of vertices, rather than on sparse graphs, where the number of edges is proportional to the number of vertices, than other pathfinding algorithms
- Shortest Accumulated Path (SAP)
- Like SSSP but only for a given source and end vertex
- These 2 above can work for undirected weighted graphs by transforming to an equivalent paired edges weighted digraph
- SSAP for DAGs
- Relax the edges in topological sorting order
- Does not use priority queue → Process each vertex after the topological order is computed, relaxing all edges enemating from those vertices
- SSAP for negative edge weights
- Bellman-Ford algorithm
- Intuition: The maximal path between the source vertex and a vertex
vin a graph withVvertices containsV - 1edges. We have to relax a maximum ofV - 1times to confirm that there is a shorter path than the maximal path.
int n = G.V();for (int i = 1; i <= n; i++) { // For each edge in the graph, see if we can relax for (DirectedEdge e : G.edges()) { if (relax(e)) { if (i == n) { return; // Negative cycle. DONE } } }}
boolean relax(DirectedEdge e) { int v = e.from(); int w = e.to(); if (distTo[w] > distTo[v] + e.weight()) { distTo[w] = distTo[v] + e.weight(); edgeTo[w] = e; return true; } return false;}- Time complexity: Θ(E*V) for sparse graph, O(E^3) for dense (since E ~ V^2)
- All Pairs Shortest Path (APSP)
- Floyd-Warshall algorithm — dynamic programming
pred[u][v]means “on shortest path fromutov, last edge came from vertexpred[u][v].”
- Floyd-Warshall algorithm — dynamic programming
int[][] pred = new int[G.V()][G.V()];double[][] dist = new double[G.V()][G.V()];
// Initialize edges and base casesfor (int u = 0; u < G.V(); u++) { for (int v = 0; v < G.V(); v++) { dist[u][v] = Integer.MAX_VALUE; pred[u][v] = -1; } dist[u][u] = 0; // Distance to self is 0 for (DirectedEdge edge : G.adj(u)) { int v = edge.to(); dist[u][v] = edge.weight(); pred[u][v] = u; // Base case }}
// Algorithm now proceedsfor (int k = 0; k < G.V(); k++) { for (int u = 0; u < G.V(); u++) { for (int v = 0; v < G.V(); v++) { // Can we shorten distance from u to v by going through k? double newLen = dist[u][k] + dist[k][v]; if (newLen < dist[u][v]) { dist[u][v] = newLen; pred[u][v] = pred[k][v]; // TRICK } } }}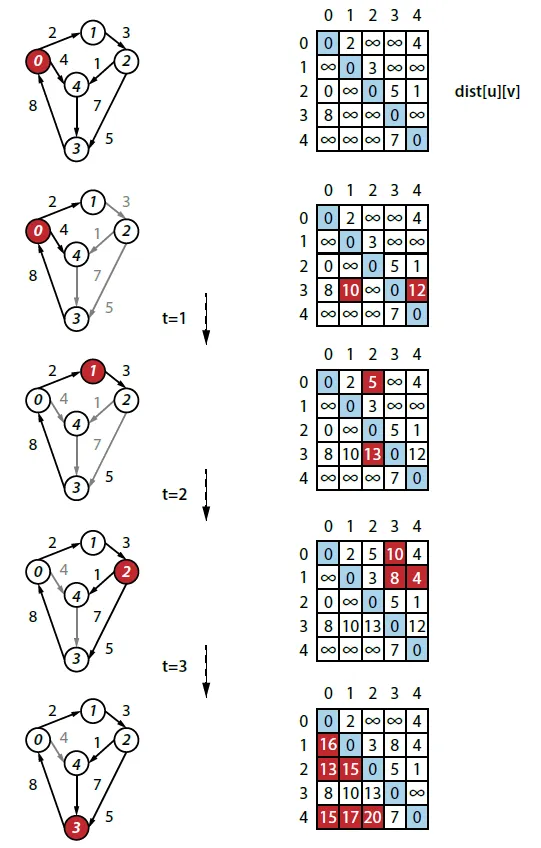
- Time complexity: O(V^3)
- Indexed Priority Queue
- Basic heap structure added with
- Determine existing index in heap for a given key.
- Allows you to decrease the priority for that key — essentially moving it closer to the front of the queue.
- You can only decrease the priority key — you can never INCREASE the key. The issue can be seen in the implementation of decreaseKey in IndexMinHeap.
- Provides a mapping between keys and their index
- Basic heap structure added with
- Technical Interviews
- UMPIRE method
- Understand what the interviewer is asking for by using test cases and questions about the problem.
- Match what this problem looks like to known categories of problems, e.g. Linked List or Dynamic Programming, and strategies or patterns in those categories.
- Plan the solution with appropriate visualizations and pseudocode.
- Implement the code to solve the algorithm.
- Review the code by running specific example(s) and recording values (watchlist) of your code’s variables along the way.
- Evaluate the performance of your algorithm and state any strong/weak or future potential work.
- UMPIRE method