Mechanisics Interpretability of LLMs
Extracting model features
Section titled “Extracting model features”Extract model features using Sparse Autoencoder. These extracted features often map to higher-level concepts, such as “sentiment” or “grammar”.
Can increase or decrease the activation of these features to see how they affect model behavior.
Q: Can we extract the “cognitive core” as described by Karpathy using SAE?
The final embedding vector (last row) has to matmul with the unembedding matrix to decode into logits, then into softmax to become a probability distribution over the vocabulary.
You can extract model features by following the last row of the input through the attention block + add-norm + MLP block + add-norm and matmul that with the unembedding matrix and softmax to get the “activation map” after each layer. Map that back to the vocabulary space to see what tokens are being activated at each layer. This tells us at exactly which layer does certain words get introduced -> which layer contains which high-level concept.
Residual stream: the resulting matrix after each add-norm block.
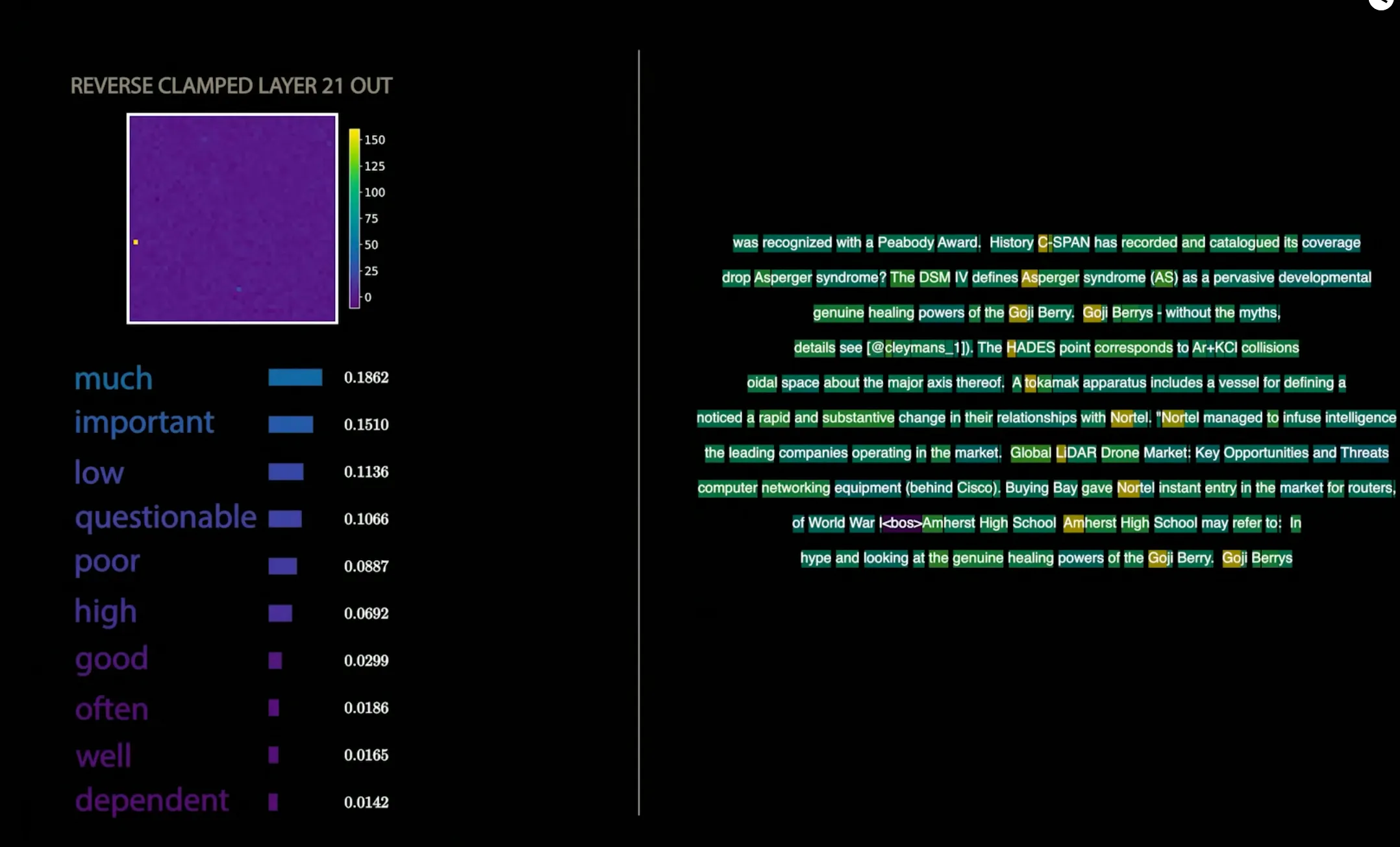
For example, clamping the “suspicion” layer in Gemma-2B causes tokens like “scam” to go up in probability, and vice versa.
Polysemanticity
Section titled “Polysemanticity”However, finding which tokens in an example dataset that maximizes suspicion lead to totally unrelated tokens. This phenomenon of single neuron mapping to multiple unrelated concepts is called polysemanticity.
Observed across a broad range of models and happens much more frequently to language models than vision models.
One possible explanation is the superposition hypothesis (Chris Olah, 2022):
Language models want to represent more concepts than they have neurons
So they “superimpose” multiple concepts into a single neuron to save space. As such, one concept maps to many neurons spread across the network.
Tracking down these mappings is very hard. Remarkably, there’s a model we can train to learn these mappings called the Sparse Autoencoder (SAE).
How SAE works
Section titled “How SAE works”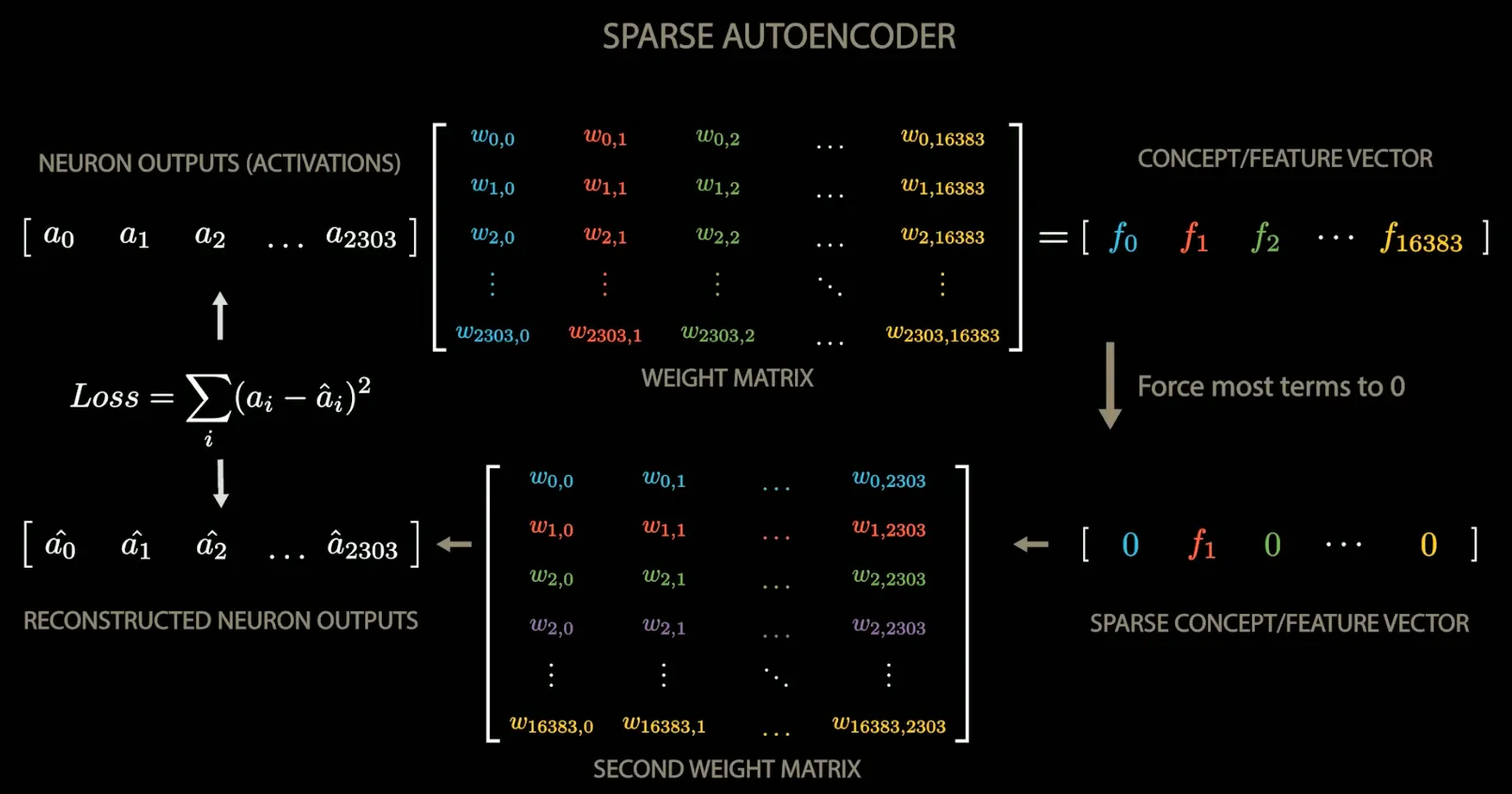
Core idea is to train a neural network that when hooked up to a specific layer’s activation, would attempt to reconstruct the original activation, but with a sparsity constraint. The model is trained to minimize the reconstruction loss. This way, SAE can tease out the concepts that a layer is trying to represent.
We can then clamp individual features in the SAE representation and modify the activation to see how it affects the model’s output. Works as expected!
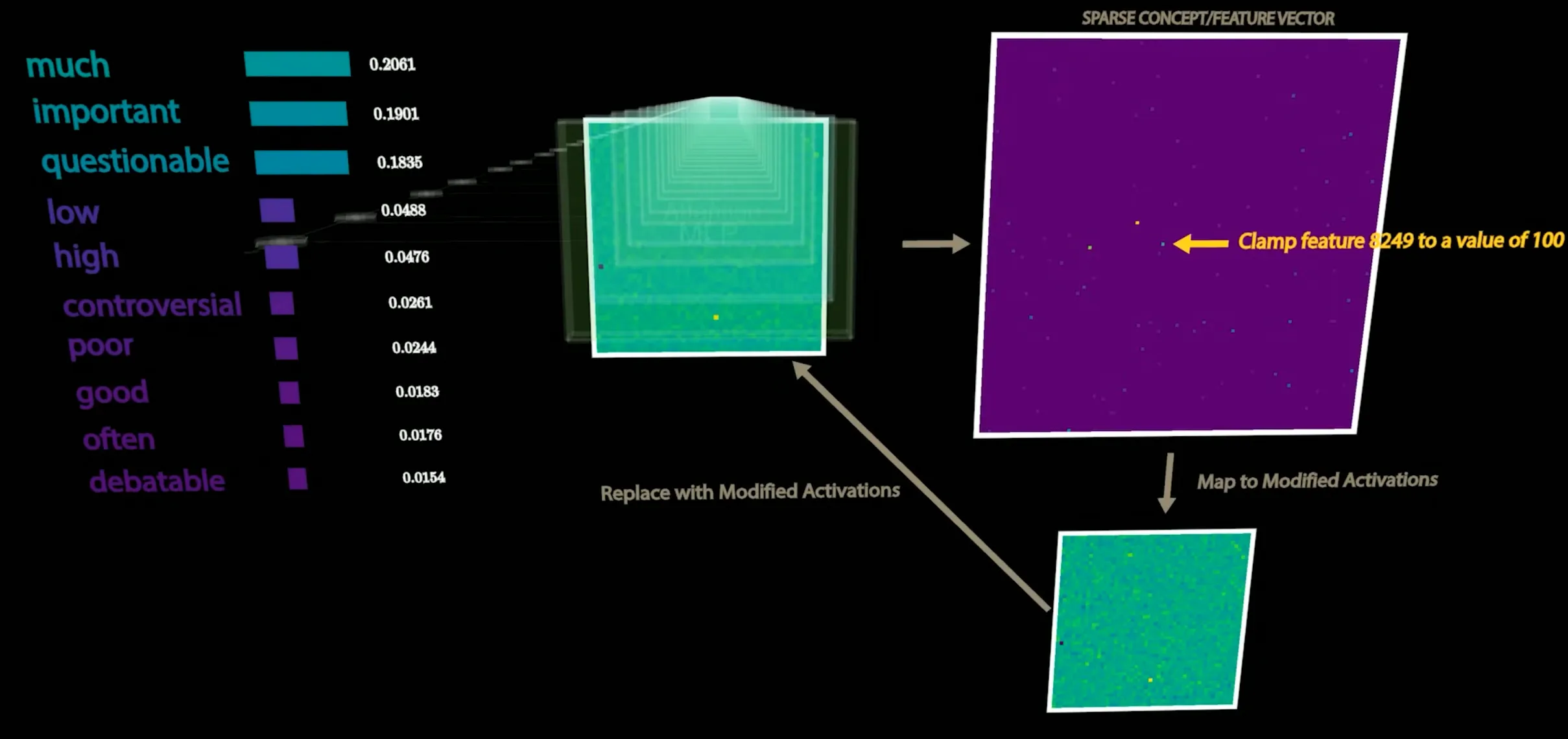
However, it cannot detangle cross-layer superpositions. Ongoing research area.
Sparse crosscoders research from Anthropic
Captum: model interpretability library for PyTorch
Section titled “Captum: model interpretability library for PyTorch”Do this some time later. Just went over my head.