Large Language Models (LLMs)
Training LLMs
Section titled “Training LLMs”- Pre-training: on Internet documents corpus. Output is a base model that “dreams” documents. The model learns about the world in this stage. However, this is not helpful yet.
- Fine-tuning/alignment: continue training to get an assistant model by swapping out the dataset with human-assistant conversations. This is to change their formatting to match the conversational style but keeping their general knowledge in the pre-training stage.
- (Optional) Reinforcement learning with human feedback (RLHF): further fine-tuning the model by having the human labellers pick the best output from different outputs from the assistant model instead of writing the answers from scratch.
Important points:
- Tool use gives models a huge boost in utility
- Multi-modality is also an axis along which models are improving
- Current models can only think in system 1 thinking, no system 2 thinking yet
- Self-improvement: AlphaGo started off by imitating human players. However, that only gives you human-level performance. To get superhuman performance, it learns by self-play (reward = win the game). Question: how to design reward function for language tasks to enable self-play for LLMs?
Pre-training
Section titled “Pre-training”Download and pre-processing the Internet
Section titled “Download and pre-processing the Internet”Tokenization
Section titled “Tokenization”Once we have concatenated all the documents into a 1-D sequence of characters, we need to decide how to represent this sequence to feed into a neural network.
There is a trade-off here between the vocabulary size (the number of unique tokens) and the sequence length (the number of tokens in the sequence).
Beyond UTF-8 for tokenization: byte pair encoding (BPE) algorithm. Idea is minting new token from commonly co-occuring tokens. Do this iteratively to decrease sequence length and increase vocabulary size. A good vocabulary size is about 100,000 possible tokens.
Visualization of tokenization in various models
Tokenization is kinda evil as it is done for efficiency reasons and brought about many deficiencies in LLMs (e.g., models can’t count, etc.). Many people are interested in training character-level models.
Neural network training
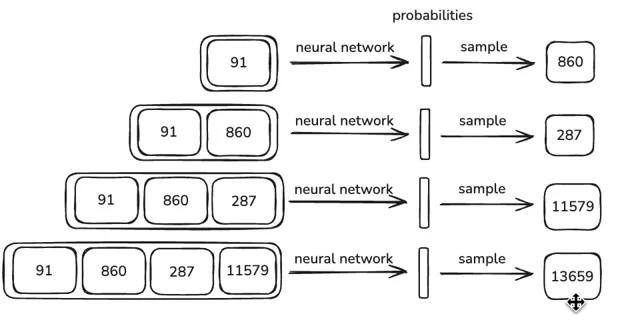
Section titled “Neural network training”We sample a randomly-sized window from the tokenized sequence (we decide a maximum window size, e.g., 8000 tokens). We call this the context window and the goal is to predict the next token.
The context window is the input into the neural network. The output is n
probabilities with n being the maximum vocabulary size. The probabilities are
the likelihood of each token being the next token.
The neural network parameters (weights and biases) are initialized randomly. We then use backpropagation to update the parameters for the results to more closely match the actual next token in the sequence.
This process happens in parallel with many batches of context windows.
Visualization of LLM architecture
Inference
Section titled “Inference”To generate data, just predict one token at a time.
Forward pass gives the probabilities of the next token. Sampling these probabilities gives the next token. Append this token to the context window and repeat.
In training, the most probable token in the output distribution is picked to calculate the loss.
However, in inference, we want diversity because we do not know what the best answer is (i.e., no ground truth). So we use specific algorithms to determine the next best token to pick into the context window:
- Beam search: keep track of the top
kmost probable tokens at each step and expand them in parallel. At the end, pick the most probable sequence - Greedy search: pick the most probable token at each step. As with greedy algorithms, this is not guaranteed to be optimal
Post-training (supervised fine-tuning, SFT)
Section titled “Post-training (supervised fine-tuning, SFT)”Exact same setup except substituting dataset with human-assistant conversations and continue training. This is to change their formatting to match the conversational style but keeping their general knowledge in the pre-training stage.
Tokenizing conversations
Section titled “Tokenizing conversations”Human: What is 2+2?Assistant: 2+2 is 4.Tokenized into:
<|im_start|>system<|im_sep|>What is 2+2?<|im_end|><|im_start|>user<|im_sep|>2+2 is 4.<|im_end|><|im_start|>assistant<|im_sep|>im_start, im_sep, and im_end are all new, special tokens introduced during
the post-training stage that get interspersed with normal text.
<|im_start|>assistant<|im_sep|> is appended after the user submits their
query. We then sample from the model to get the next best tokens.
LLM involvement in SFT
Section titled “LLM involvement in SFT”As LLMs get smarter, human labellers no longer have to write answers from scratch. They can be generated by LLMs instead.
Hallucinations
Section titled “Hallucinations”Hallucinations happen because answers in the post-training dataset have a confident tone.
Interrogation
Section titled “Interrogation”To alleviate this, we add examples to the dataset where the correct answer is the model doesn’t know. However, to do this, we need to know the knowledge boundary of the model. This can be done through interrogation:
- Extract a context window
- Use an LLM to generate question-answer pairs relevant to the context
- Feed questions to the model to see if it can answer them correctly
- Score the correctness and informativeness of the generated answer using an LLM judge
- If the model answers incorrectly, put the Q&A pair into the post-training dataset with “I don’t know” as the answer
Tool use
Section titled “Tool use”Another mitigation is to allow the model to search the Internet via tool use.
Same as tokenizing conversations, we introduce new
tokens to represent a Search tool use. This can be hooked up to external
search engines so the inference program can go search the query emitted by the
LLM when encountering the <SEARCH_END> token and pasting the answer in the
context window.
Psychology of LLMs
Section titled “Psychology of LLMs”Vague recollection vs working memory
Section titled “Vague recollection vs working memory”Note the distinction between knowledge in the parameters and in the tokens of the context window. One is a vague recollection and the other is the working memory.
Knowledge of self
Section titled “Knowledge of self”Doesn’t have one because they are just trained to be a general, helpful, harmful assistant.
Either have to remind them through system prompt or hardcoded conversations in the SFT (post-training) dataset (“Who are you?”, “Who made you?”, etc.).
Models need tokens to think
Section titled “Models need tokens to think”Since roughly the same amount of computation happens for each token in the context, you cannot cram all of the computation required for a question (e.g., answer for a math equation) into one token and expect it to be correct. As such, intermediate tokens (i.e., “thinking steps”) are needed to break down the problem.
Intuition: tell the LLM to spread out its computation over multiple tokens.
Intuition: prefer to use tools over vague recollection whenever possible.
Post-training (reinforcement learning, RL)
Section titled “Post-training (reinforcement learning, RL)”Analogy with textbook: pre-training is the exposition to give the students background knowledge, post-training SFT is the example solved problems for the students to refer to how solution experts look like, and post-training RL is where you’re given a problem statement and the final answer and we want to practice solutions that take us from the problem statement to the final answer, and “internalize” them into the model.
Two purposes of RL: correctness of answers and nice-to-human formatting of the solution-arrival process.

There’s a risk of distillation where other companies can copy a model’s reasoning CoT when coming up with answers. That’s why OpenAI hides their reasoning step.
Frontier research: create diverse sets of game environments in many different domains and perform RL on them to get superhuman level of reasoning/thinking.
Verifiability of a domain: can you check the correctness of an answer automatically? E.g., code generation, math problems, etc. either with human in the loop or an LLM judge?
Reinforcement learning with human feedback (RLHF)
Section titled “Reinforcement learning with human feedback (RLHF)”RL is unscalable. RLHF comes in.

RLHF upside: We can run RL in arbitrary domains (even the unverifiable ones). This (empirically) improves the performance of the model, possibly due to the “discriminator-generator” gap:
In many cases, it’s easier to discriminate than to generate.
e.g., “Write a poem” vs. “Which of these 5 poems is the best?”
This makes it much easier for human labellers.
RLHF downside: Might be misleading as it’s just a lossy simulation of human preferences. Even more subtle is RL discovering ways to “game” the model, i.e., adversarial inputs that get in between the nooks and crannies of the model to make it prefer the input the most, even though the input doesn’t make sense to humans.
Mitigation: for now, just crop it so the reward model doesn’t find adversarial inputs to game. It WILL always find adversarial inputs if let run long enough, since they are giant neural networks.
RLHF is not RL as you cannot throw infinite compute at it and expect it to get better (non-verifiability). It’s just a band-aid, fine-tuning step to squeeze out a bit more juice.
The future
Section titled “The future”Places to rent GPUs: Modal, Lambda Labs, vast.ai, Hyperbolic Labs, together.ai
- Multi-modality: models that can process images, videos, audio, etc. Just introduce new token types and intersperse them into text like tokenizing conversations
- Tasks -> agents (long, coherent, error-correcting contexts)
- Pervasive, invisible, computer-using
- Test-time training