Bigram language model
Character-level language model predicts the next character in a sequence given some concrete characters before it.
Intuition: A word in itself already packs a lot of examples/structure/statistics a model can pick up on.
Bigram
Section titled “Bigram”One character simply predicts the next one using a lookup table of counts.
Evaluation
Section titled “Evaluation”The likelihood of the bigram model is the product of all the probabilities of each character given the previous one (the bigrams itself). It’s a measure of how well the model predicts the training data.
For convenience, because each probability is very small, and so their product is also very small, we use the log-likelihood instead. The log of a product is the sum of the logs, so we can sum up the log-probabilities instead of multiplying the probabilities.
However, the semantics of a loss function dictates that lower is better (until 0.0, which is perfect). So we take the negative log-likelihood as our loss function. People also normalize that by taking the average log-likelihood per character.
TL;DR: Goal is to maximize likelihood w.r.t. model parameters (statistical modeling)
- equivalent to maximizing the log-likelihood (because log is monotonic)
- equivalent to minimizing the negative log-likelihood (because of the minus sign)
- equivalent to minimizing the average negative log-likelihood per character
The lookup table of counts can now be thought of as the model parameters, and so we don’t store the counts explicitly in it anymore. We wanna tune the table so as to maximizes the likelihood.
Model smoothing: since some uncommon bigrams like jq may appear 0 times in
the training set, people use model smoothing to add fake counts to all bigrams.
This prevents the model from assigning a 0 probability to any bigram, which
would make the whole product 0, or the average negative log-likelihood to
explode to infinity. The more you add, the smoother the model will get.
Comparing with L1 loss
Section titled “Comparing with L1 loss”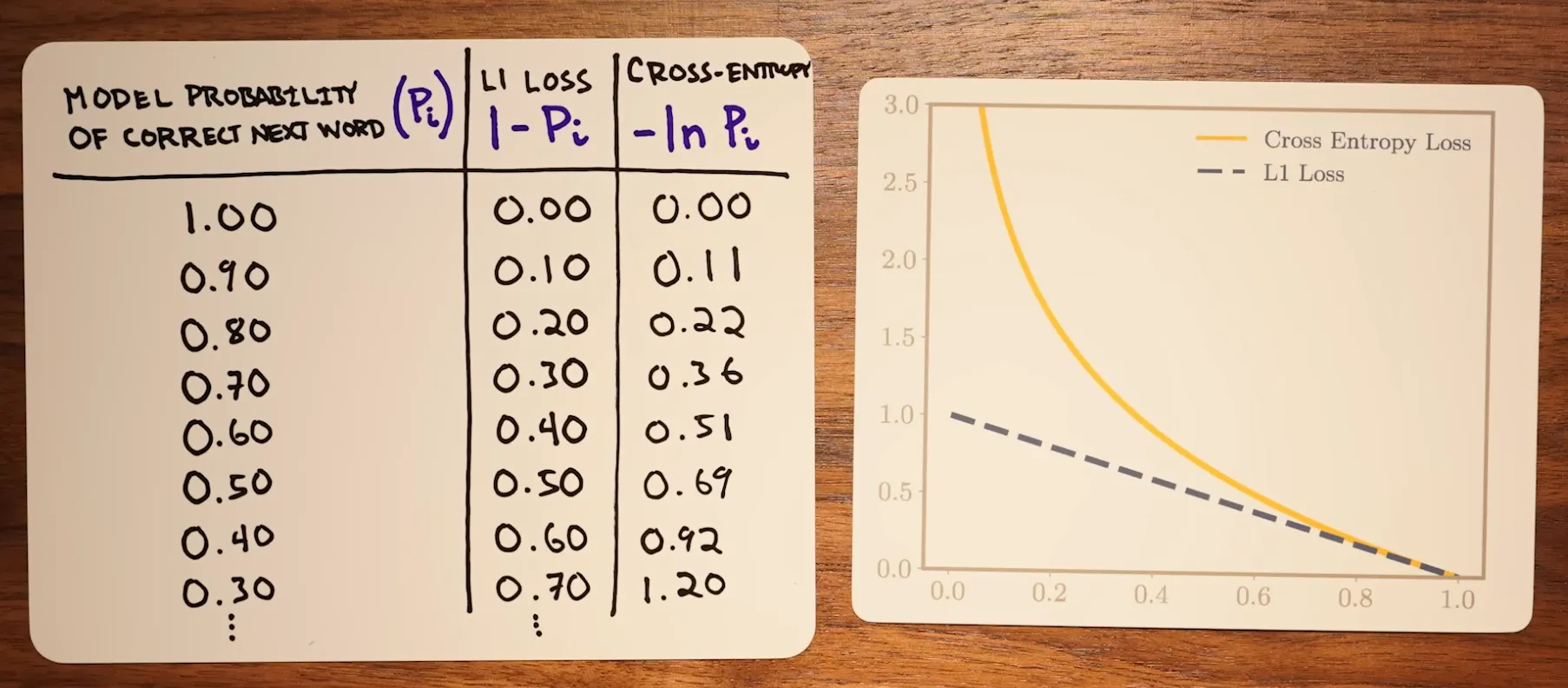
Now with neural network approach
Section titled “Now with neural network approach”We pack up each corresponding bigram pairs so that inputs[i] has the label
outputs[i]. Since we can’t feed the id of the character directly into the
neural network, we need to one-hot encode them first.
One-hot encoding: represent each character as a vector of length equal to the vocabulary size, with all elements being 0 except for the index corresponding to the character, which is 1. Like “turning on” that index only, hence the name.
Going back to why we need tensors, basically lots of inputs packed into matrix x lots of neurons packed into matrix = matrix-matrix multiplication, massive parallelism, GPUs go brrrrrr.
We interpret the neural network outputs as log-counts (aka logits), because neural networks aren’t designed to output direct counts (like the original bigram) or a probability distribution (which must sum to 1).
Sequence: the standard approach is: Logits -> Softmax -> Log -> Negative -> NLL Loss.
Softmax layer: a commmon NN layer that turns an input layer (with positive and negative values, most commonly logits or linear layer) into a probability distribution by exponentiating them (to turn log-counts into counts) and normalizing them (dividing by the sum of all counts) so that they sum to 1.
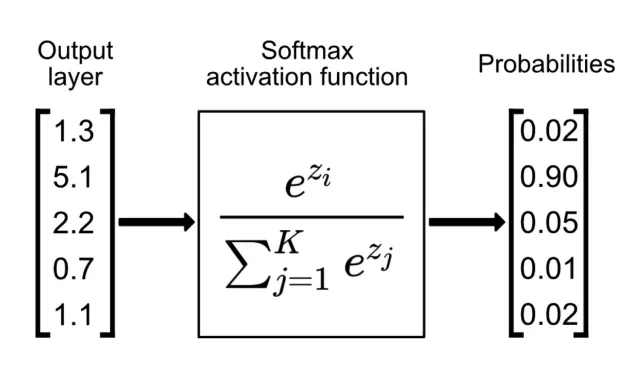
L2 regularization add a term to the loss function that penalizes large weights in the model, encouraging the model to keep its weights small and “flattens” the model’s output distributions This is kinda similar to the model smoothing technique mentioned earlier, which adds fake counts to all bigrams to prevent zero probabilities.