CUDA
-
Introduction
-
GPUs vs. CPUs
-
CPU: Central Processing Unit
-
General purpose
-
High clock speed
-
Few cores
-
High cache
-
Low Latency
-
Low throughput
-
-
GPU: Graphics Processing Unit
-
Specialized
-
Low clock speed
-
Many cores
-
Low cache
-
High Latency
-
High throughput
-
-
TPU: Tensor Processing Unit
- Specialized GPUs for deep learning algorithms (matrix multiplication, etc)
-
FPGA: Field Programmable Gate Array
-
Specialized hardware that can be reconfigured to perform specific tasks
-
Very low latency
-
Very high throughput
-
Very high power consumption
-
Very high cost
-
-
-
What makes GPUs so fast for deep learning?
-
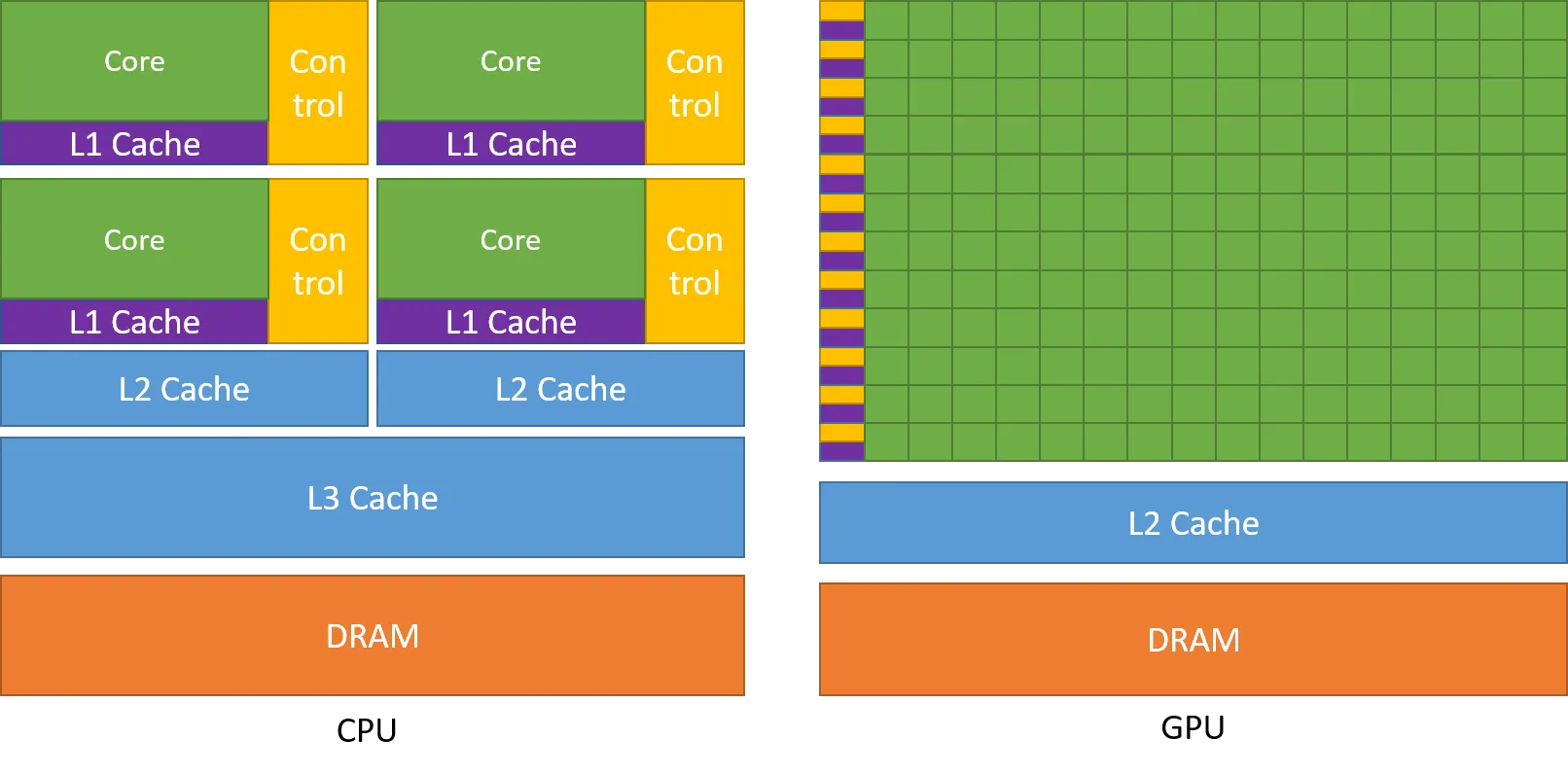
-
Less control (less instructions)
-
More cores
-
L1 cache shared between cores
-
CPU (host)
-
minimize time of one task
-
metric: latency in seconds
-
-
GPU (device)
-
maximize throughput
-
metric: throughput in tasks per second (ex: pixels per ms)
-
-
Typical CUDA program structure
-
CPU allocates CPU memory
-
CPU copies data to GPU
-
CPU launches kernel on GPU (processing is done here)
-
CPU copies results from GPU back to CPU to do something useful with it
-
Lingo
-
kernels (not popcorn, not convolutional kernels, not linux kernels, but GPU kernels)
-
threads, blocks, and grid (next chapter)
-
GEMM = GEneral Matrix Multiplication
-
SGEMM = Single precision (fp32) GEneral Matrix Multiplication
-
cpu/host/functions vs gpu/device/kernels
-
CPU is referred to as the host. It executes functions.
-
GPU is referred to as the device. It executes GPU functions called kernels.
-
-
-
CUDA